分布式系统的一致性协议之 Paxos 算法的应用场景
前言
通过Paxos算法的两个阶段(前文《分布式系统的一致性协议之 Paxos 算法》我将它拆分为三个阶段,只是更易于自己理解),可以在分布式系统中得到一个被所有节点承认的值,该值满足一致性要求。那么得到这个值之后,有什么工程化的应用呢,如何做到生成级别。
Paxos算法回顾
我们先简单回顾一下Paxos算法或者叫协议。Paxos算法是布式系统中通用的一致性方案中的一种,它能达到某种最终一致性的状态。
角色划分:
Proposer:存在多个,可以向Acceptor提出Proposal(提案)。
Acceptor:存在多个,可以接收Proposal(提案),针对提案的序号和信息判断是否初步批准、最终批准,形成决议。
Leaner:让所有节点学习决议
简略流程:
1、它通过Prepare阶段的N个Proposer向M个Acceptor提出Proposal(包含编号X),Acceptor在接收到Proposal后,根据已经接收到的所有Proposal以及四个约束,响应给Proposer结果;
2、Proposer在拿到Acceptor的响应后,如果响应信息中预批准数量K>M/2,也就是达到多数派,则向M个Acceptor发起最终确认请求进入Accept阶段,否则序号增加后重新开始;
Acceptor接收到最终确认请求后,只要这个Acceptor没有对编号大于X的Proposal做出过响应(prepare阶段响应),那么它就接受该Proposal(提案),也就形成决议,一旦达成决议,那么其他Proposer也就必须要进入学习阶段,由Leaner来完成。
Paxos是用来干什么的
确定一个值
在这之前反复提到,Paxos的目的是要确定一个值,并且当一个值确定后是永远不能被修改的。那么得到得到后又能做什么?
确定多个值
假设将上面得到一个值的流程定义为Paxos Instance,那么多个Instance就可以得到多个值。这些值是由不同的Instance得到,也就不存在任何关系,完全独立。多个值能干什么?
有序地确定多个值
前文《分布式系统的一致性协议之 Paxos 算法》有提到:
Paxos算法的目的:是在分布式环境下确定一个值,这个值被所有节点承认。注意,这个值并不是狭义上的某个数,它可以是一条日志,也可以是一条命令(command)等等,根据应用场景不同,有不同的含义。
到这已经很豁然开朗了,只要我们通过paxos完成一个多机一致的有序的操作系列,那么通过这个操作系列的演进,可实现的东西就很有想象空间了,存储服务必然不是问题。
如何利用paxos有序的确定多个值?上文我们知道可以通过运行多个实例来完成确定多个值,但为了达到顺序的效果,需要加强一下约束。
首先给实例一个编号,定义为i,i从0开始,只增不减,由本机器生成,不依赖网络。其次,我们保证一台机器任一时刻只能有一个实例在工作,这时候Proposer往该机器的写请求都会被当前工作的实例受理。最后,当编号为i的实例获知已经确定好一个值之后,这个实例将会被销毁,进而产生一个编号为i+1的实例。
基于这三个约束,每台机器的多个实例都是一个连续递增编号的有序系列,而基于paxos的保证,同一个编号的实例,确定的值都是一致的,那么三台机都获得了一个有序的多个值。
下面结合一个图示来详细说明一下这个运作过程以及存在什么异常情况以及异常情况下的处理方式。
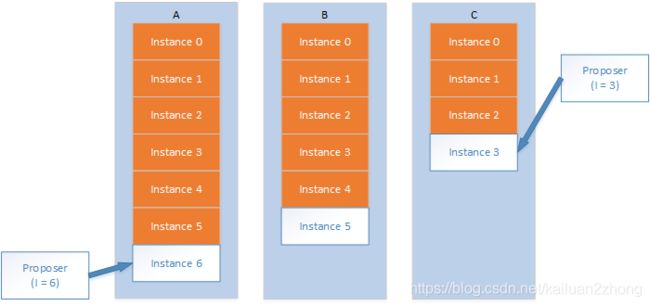
图中A,B,C代表三个机器,红色代表已经被销毁的实例(相同编号的Instance都能确定一个值),根据上文约束,最大的实例就是当前正在工作的实例。A机器当前工作的实例编号是6,B机是5,而C机是3。为何会出现这种工作实例不一样的情况?首先解释一下C机的情况,由于paxos只要求多数派存活即可完成一个值的确定,所以假设C出现当机或者消息丢失延迟等,都会使得自己不知道3-5编号的实例已经被确定好值了。而B机比A机落后一个实例,是因为B机刚刚参与完成实例5的值的确定,但是他并不知道这个值被确定了。上面的情况与其说是异常情况,也可以说是正常的情况,因为在分布式环境,发生这种事情是很正常的。(由于宕机、时间差等情况,ABC三台机器的进度会出现不一致情况)
下面分析一下基于图示状态的对于C机的写入是如何工作的。C机实例3处理一个新的写入,根据paxos协议的保证,由于实例3已经确定好一个值了,所以无论写入什么值,都不会改变原来的值,所以这时候C机实例3发起一轮paxos算法的时候就可以获知实例3真正确定的值,从而跳到实例4(C机在下一轮Paxos过程中会发现Instance3-6都已经被确认,也就会从Instance6开始)。但在工程实现上这个事情可以更为简化,上文提到,各个实例是独立,互不干涉的,也就是A机的实例6,B机的实例5都不会去理会C机实例3发出的消息,那么C机实例3这个写入是无法得到多数派响应的,自然无法写入成功(最初C机发起了Instance3,由于广播给AB时,无法被确认,无法形成多数派)。
(插个嘴,上图红色的Instance完全可以看成是一个确定的值,引申下就是一个Instance编号已经有了一个确定的值,那么当C机器开始Instance3时,就会发现Instance3已经对应上了一个值,也就不会进行了;而白色的Instance是即将要开始的,每个机器上只有在接收到请求或者开启Prepare阶段,才会产生)
再分析一下A机的写入,同样实例6无法获得多数派的响应,同样无法写入成功。同样假如B机实例5有写入,也是写入失败的结果,那如何使得能继续写入,实例编号能继续增长呢?这里引出下一个章节。
实例的对齐(Learn)
上文说到每个实例里面都有一个Acceptor的角色,这里再增加一个角色称之为Learner,顾名思义就是找别人学习,她回去询问别的机器的相同编号的实例,如果这个实例已经被销毁了,那说明值已经确定好了,直接把这个值拉回来写到当前实例里面,然后编号增长跳到下一个实例再继续询问,如此反复,直到当前实例编号增长到与其他机器一致(这样Instance中的包含了Paxos协议中的所有角色了)。
由于约束里面保证仅当一个实例获知到一个确定的值之后,才能编号增长开始新的实例,那么换句话说,只要编号比当前工作实例小的实例(已销毁的),他的值都是已经确定好的。所以这些值并不需要再通过paxos来确定了,而是直接由Learner直接学习得到即可(C机的Instance有3增长到6)。
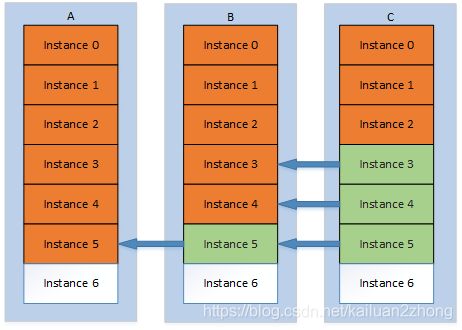
如上图,B机的实例5是直接由Learner从A机学到的,而C机的实例3-5都是从B机学到的,这样大家就全部走到了实例6,这时候实例6接受的写请求就能继续工作下去(达到最终一致)。
如何应用paxos
状态机
一个有序的确定的值,也就是日志,可以通过定义日志的语义进行重放的操作,那么这个日志是怎么跟paxos结合起来的呢?我们利用paxos确定有序的多个值这个特点,再加上这里引入的一个状态机的概念,结合起来实现一个真正有工程意义的系统。
状态机这个名词大家都不陌生,一个状态机必然涉及到一个状态转移,而paxos的每个实例,就是状态转移的输入,由于每台机器的实例编号都是连续有序增长的,而每个实例确定的值是一样的,那么可以保证的是,各台机器的状态机输入是完全一致的。根据状态机的理论,只要初始状态一致,输入一致,那么引出的最终状态也是一致的。而这个状态,是有无限的想象空间,你可以用来实现非常多的东西。
如下图这个例子是一个状态机结合paxos实现了一个具有多机一致的KV系统。
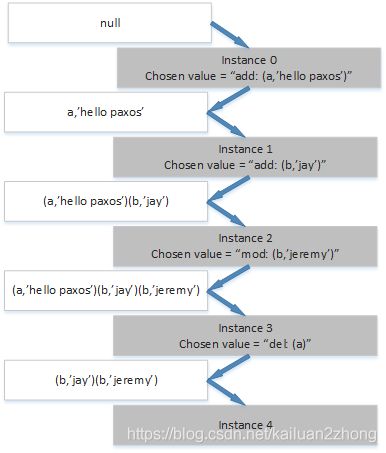
实例0-3的值都已经被确定,通过这4个值最终引出(b, ‘jeremy’)这个状态,而各台机器实例系列都是一致的,所以大家的状态都一样,虽然引出状态的时间有先后,但确定的实例系列确定的值引出确定的状态。
(插个嘴,每个Instance完成的工作都是一次状态机的输入,由于是确定的值,也就保证了状态、输入一致)
下图例子告诉大家Proposer,Acceptor,Learner,State machine是如何协同工作的。
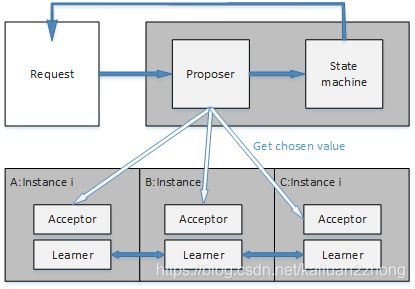
Instance-X工作内容:一个请求发给Proposer,Proposer与相同实例编号为x的Acceptor协同工作,共同完成一值的确定,之后将这个值作为状态机的输入,产生状态转移,最终返回状态转移结果给发起请求者。
顺着这个思路,完成通信、Leaner、封装好一组Instance(包含多个机器或实例)、保证隔离性,就能有一套完整的实现。
多机一致的KV系统
首先,假设数据库对外提供3种操作
- Put
- PutAppend
- Get
在这样的一个架构下,通过多台server组成集群来避免单点问题。但是,如图所示的3台server必须保持同步。也就是说,如果Client向集群发送请求 Put("a", 1)并成功,那么整个集群中任意一台server必须都含有数据("a", 1)(一致性要求)。
这里的Put("a", 1)就是lamport论文中proposer提出的value。对于数据库集群而言,所有的操作都是串行的,就像现在的数据库都提供日志功能一样,每个操作都会记录在日志当中,并而是有先后顺序的。如果我们的集群先后收到3个操作请求,分别为
- Put("a", 1)
- Put("b", 2)
- Put("c", 3)
那么在对于数据库集群而言,应该有这么一个状态表,类似为
+---+-------------+
|1 |Put("a", 1) |
+---+-------------+
|2 |Put("b", 2) |
+---+-------------+
|3 |Put("c", 3) |
+---+-------------+这里的标号1,2,3就对应论文中的Sequence。下面我们就假设数据库集群是空的,即没有任何数据。客户端发送了上面3个请求,当然,这中间可能存在多个客户端同时发送请求的情况。
1、如果这三个请求间隔一定时间到达(或者都发到同一台机器server1),那么根据Paxos协议的逻辑,将会顺利执行并最终确认。每确认一个值,通过Learning阶段,都会让server2和server3也将自己的状态表保持一致。
2、如果这三个请求间隔很小并且发到不同机器上,会根据Paxos协议,每个机器在接收到消息后,会检查自己的状态表进行校正(也就是Leaning过程)在进行Paxos的流程。
假设先进行了一次顺利的Put("a", 1)操作,但还未进行Leaning,也就是server,之后这里我们假设有出现了两个客户端,Client2和Client3。
- Client2向集群发送了请求Put("b", 2),假设这个请求最终到了server1上。
- Client3向集群发送了请求Put("c", 3), 假设这个求情发到了server2上。
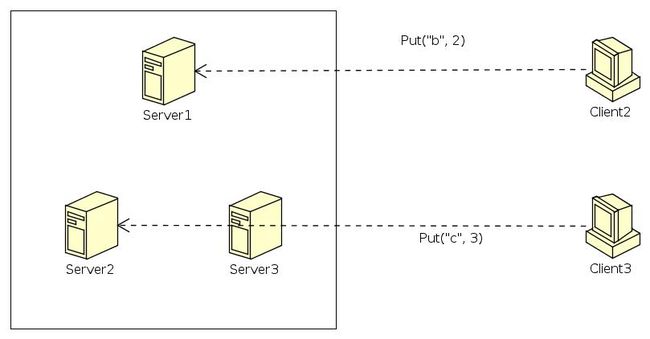
此时server1和server2的状态表是一样的,这一点是由Paxos保证的。他们的不同之处在于:
- server1的数据和server2不同,即server1里面包含一条数据,就是刚刚Client1请求的Put("a", 1), 但是server2是空的。
- server1的sequence为2, 但是server2的sequence仍然为1。原因是server1已经做了一次Put操作,但是server2什么都没有做。
由于server1和server2的不同,因此他们处理各自请求的方式也不同。
先来看server2。server2从1开始遍历自己的状态表,发现1号操作非空,说明这是他遗漏的操作,于是server2也执行了操作Put("a", 1), 此时server2与server1的状态完全一样了。在此之后,server2会向上面server1一样,调用doPaxos函数进行协商,即询问集群中的所有server咱们的第2个操作能否为Put("c", 3)。
doPaxos(2, v);
其中v为 Put("c", 3)。
但就在此时,server1也调用了doPaxos进行协商,询问集群中的所有server第2个操作能否为Put("b", 2)。
这里集群中两个server提出了不同的议题(lamport的论文中也使用了这种说法),Paxos保证了最终会选出一个大家都同意的议题。我们这里假设server1的议题最终被通过了。于是,集群中所有server的状态表都更新为
+---+-------------+
|1 |Put("a", 1) |
+---+-------------+
|2 |Put("b", 2) |
+---+-------------+
并且server1向自己的database中插入("b", 2),并将自己的sequence更新为3.
而此时server2发现自己的状态表中sequence2有了对应的操作,但很可惜不是自己提出的那个操作。这条信心表明集群其实已经做了2个操作了,自己想要提出的这个操作Put("c", 3)已经不能作为集群的第2个操作了。于是server2对自己的database进行Put("b", 2)操作, 然后将自己的sequence更新为3。再次调用doPaxos进行协商,试图将自己的操作作为集群的第3个操作,于是doPaxos的参数为
doPaxos(3, {Put("c", 3)})
此时由于只有一个提议,所以协商很顺利。此时集群中所有server的状态表都为
+---+-------------+
|1 |Put("a", 1) |
+---+-------------+
|2 |Put("b", 2) |
+---+-------------+
|3 |Put("c", 3) |
+---+-------------+
其中,server1包含2条数据,server2包含3条数据,server3为空。
(插个嘴,刚刚的例子是按顺序假设的,在Put("b", 2)和Put("c", 3)发生冲突,抢夺Instance2的过程中,也有可能是Put("c", 3)拿到Instance,那么状态表最终的顺序将会是下面的情况)
+---+-------------+
|1 |Put("a", 1) |
+---+-------------+
|2 |Put("c", 3) |
+---+-------------+
|3 |Put("b", 2) |
+---+-------------+
我们假设此时Client1向集群发送了Get("a")请求,并最终发到了server3。由于server3的sequence为, 所以他会从1开始,将自己状态表中的1,2,3号操作就执行一遍,直到到了sequence4时,发现状态表为空,于是进行查询操作,将结果返回Client。
由于Get是只读操作,因此没必要协商,也没必要将其写入状态表。
参考:
Paxos-->Fast Paxos-->Zookeeper分析
Zookeeper系列(3)--Paxos算法的原理及过程透彻理解
分布式系统理论进阶 - Paxos
Paxos 算法浅析
Paxos理论介绍(2): Multi-Paxos与Leader
微信自研生产级paxos类库PhxPaxos实现原理介绍
Paxos的应用场景