Caffe学习系列(十):腾讯ncnn框架
Caffe学习系列(十):腾讯ncnn框架
《手把手AI项目》七、MobileNetSSD通过Ncnn前向推理框架在PC端的使用(目标检测 objection detection)
1.ncnn安装
安装依赖
sudo apt-get install -y gfortran
sudo apt-get install -y libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler
sudo apt-get install --no-install-recommends libboost-all-dev
sudo apt-get install -y libgflags-dev libgoogle-glog-dev liblmdb-dev libatlas-base-dev
下载ncnn
git clone https://github.com/Tencent/ncnn
cd ncnn
在编译之前,我们希望和示例程序一起编译
需要修改CmakeList.txt文件。去掉下面两段代码前面的#
add_subdirectory(examples)
add_subdirectory(benchmark)
开始编译
mkdir build
cd build
cmake ..
make -j4
make install
编译完成后,在 build 目录下看到会有:
# 示例程序的可执行文件全部在examples内
# ncnn库文件以及头文件全部在install目录下
# tools目录下是一些转化工具
examples install tools
2.YOLOv2测试
下载训练好的yolo模型:
https://github.com/eric612/MobileNet-YOLO/tree/master/models/yolov2
这里我们下载:
mobilenet_yolo_deploy_iter_80000.caffemodel mobilenet_yolo_deploy.prototxt
使用 caffe2ncnn工具进行转换
tools/caffe/caffe2ncnn mobilenet_yolo_deploy.prototxt mobilenet_yolo_deploy_iter_80000.caffemodel mobilenet_yolo.param mobilenet_yolo.bin
将生成的转换文件复制到 build/examples 目录下,运行以下命令
./yolov2 fish-bike.jpg

3.MobileNet_SSD测试
3.1 Caffemodel转换为新版本
旧版caffe模型和网络文件转换成新版caffe模型和网络文件(ncnn只支持新版)
这个tools在caffe/build/tools中直接就有,具体操作如下
# 此处模型为合并完 Bn 层的模型和权重
# 新模型不用再修改数据层,避免了本文5.1节问题的发生
./caffe/build/tools/upgrade_net_proto_text MobileNetSSD_deploy.prototxt MobileNetSSD_deploy_new.prototxt
./caffe/build/tools/upgrade_net_proto_binary MobileNetSSD_deploy.caffemodel MobileNetSSD_deploy_new.caffemodel
3.2 生成bin和param文件
切换到 /ncnn/build目录下,运行以下命令
.param相当于prototxt网络文件,.bin相当于caffemodel模型文件
./tools/caffe/caffe2ncnn MobileNetSSD_deploy_new.prototxt MobileNetSSD_deploy_new.caffemodel MobileNetSSD_deploy.param MobileNetSSD_deploy.bin
3.3 加密bin和param文件(开发APP使用)
在PC端测试可跳过本小节
去掉可见字符串, 一种常见加密方式,不加密的话自己的网络可能被别人套用
./ncnn/build/tools/ncnn2mem MobileNetSSD_deploy.param MobileNetSSD_deploy.bin MobileNetSSD_deploy.id.h MobileNetSSD.mem.h
3.4 生成bin和param文件
将3.2节生成的bin和param文件复制到 build/examples 目录下
./mobilenetssd 00338.jpg
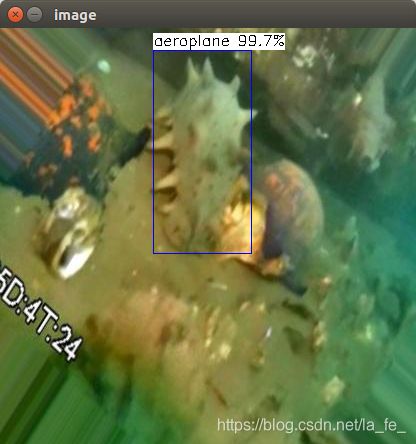
4. 模型量化
将自己训练的 Mobile Net_SSD 得到的模型与权重进行量化压缩,转换成 8 位存储
4.1 工具下载
git clone https://github.com/BUG1989/caffe-int8-convert-tools.git
在 caffe-int8-convert-tools 目录下新建一个 test 文件夹
test 文件夹下建立 images 与 models 两个文件夹
images 目录下放 验证集 图片
models 目录下放 deploy.prototxt 与 caffemodel
4.2 模型转化
在 caffe-int8-convert-tools 目录下运行以下命令:
python2 caffe-int8-convert-tool-dev.py --proto=test/models/MobileNetSSD_deploy_new.prototxt --model=test/models/MobileNetSSD_deploy_new.caffemodel --mean 127.5 127.5 127.5 --norm=0.007843 --images=test/images/ --output=test/MobileNetSSD.table
生成 MobileNetSSD.table 文件,之后进入test文件夹下
cd test
/home/hitwh/workspace/ncnn/build/tools/caffe/caffe2ncnn /home/hitwh/workspace/caffe-int8-convert-tools/test/models/MobileNetSSD_deploy_new.prototxt /home/hitwh/workspace/caffe-int8-convert-tools/test/models/MobileNetSSD_deploy_new.caffemodel MobileNetSSD-int8.param MobileNetSSD-int8.bin 256 MobileNetSSD.table
生成 MobileNetSSD-int8.bin 与 MobileNetSSD-int8.param,模型由22.2M压缩至5.8M。

4.3 模型测试
将转化后的模型名称改为 mobilenet_ssd_voc_ncnn.param 与 mobilenet_ssd_voc_ncnn.bin 并复制到 ncnn/build/examples 路径下
进行测试
./mobienetssd 00338.jpg

5. 问题及解决办法
5.1 mobilenetssd检测报错
find_blob_index_by_name data_splitncnn_6 failed
find_blob_index_by_name data_splitncnn_5 failed
find_blob_index_by_name data_splitncnn_4 failed
find_blob_index_by_name data_splitncnn_3 failed
find_blob_index_by_name data_splitncnn_2 failed
find_blob_index_by_name data_splitncnn_1 failed
find_blob_index_by_name data_splitncnn_0 failed
段错误 (核心已转储)
将 MobileNetSSD_deploy.prototxt 的数据输入层进行修改
# 修改前
#input: "data"
#input_shape {
# dim: 1
# dim: 3
# dim: 300
# dim: 300
#}
# 修改后
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 1 dim: 3 dim: 300 dim: 300 } }
}
5.2 标签问题
修改 ncnn/examples/mobilessd.cpp 文件
static void draw_objects(const cv::Mat& bgr, const std::vector修改后再重新编译。