机器学习——DStream操作概述
Spark Streaming工作机制
在Spark Streaming中,会有一个组件Receiver,作为一个长期运行的任务(Task)运行在一个Executor上,每个Receiver都会负责一个DStream输入流(如从文件中读取数据的文件流、套接字流或者从Kakfa中读取的一个输入流等)。Receiver组件接收到数据源发来的数据后,会提交给Spark Streaming程序进行处理。处理后的结果,可以交给可视化组件进行可视化展示,也可以写入到HDFS、HBase中。
编写Spark Streaming程序的基本步骤
编写Spark Streaming程序的基本步骤如下:
- 通过创建输入DStream(Input Dstream)来定义输入源。流计算处理的数据对象是来自输入源的数据,这些输入源会源源不断产生数据,并发送给Spark Streaming,由Receiver组件接收到以后,交给用户自定义的Spark Streaming程序进行处理;
- 通过对DStream应用转换操作和输出操作来定义流计算。流计算过程通常是由用户自定义实现的,需要调用各种DStream操作实现用户处理逻辑;
- 调用StreamingContext对象的start()方法来开始接收数据和处理流程;
- 通过调用StreamingContext对象的awaitTermination()方法来等待流计算进程结束,或者可以通过调用StreamingContext对象的stop()方法来手动结束流计算流程。
创建StreamingContext对象
在RDD编程中需要生成一个SparkContext对象,在Spark SQL编程中需要生成一个SparkSession对象,同理,如果要运行一个Spark Streaming程序,就需要首先生成一个StreamingContext对象,它是Spark Streaming程序的主入口。
可以从一个SparkConf对象创建一个StreamingContext对象。登录Linux系统后,启动spark-shell。进入spark-shell以后,就已经获得了一个默认的SparkContext对象,也就是sc。因此,可以采用如下方式来创建StreamingContext对象:

new StreamingContext(sc,Seconds(1))的两个参数中,sc表示SparkContext对象,Seconds(1)表示在对Spark Streaming的数据流进行分段时,每1秒切成一个分段。可以调整分段大小,比如使用Seconds(5)就表示每5秒切成一个分段,但是,无法实现毫秒级别的分段,因此,Spark Streaming无法实现毫秒级别的流计算。
如果是编写一个独立的Spark Streaming程序,而不是在spark-shell中运行,则需要在代码中通过如下方式创建StreamingContext对象:
import org.apache.spark._
import org.apache.spark.streaming._
val conf=new SparkConf().setAppName("TestDStream").setMaster("local[2]")
val ssc=new StreamingContext(conf,Seconds(1))基本输入源
Spark Streaming可以对来自不同类型数据源的数据进行处理,包括基本数据源和高级数据源(如Kafka、Flume等)。
文件流
首先,在Linux系统中打开第一个终端(为了便于区分多个终端,这里称为“数据源终端”),创建一个logfile目录,一次输入如下语句:

然后,在Linux系统中打开第二个终端(为了便于区分多个终端,这里称为“流计算终端”),启动进入spark-shell,然后,一次输入如下语句:
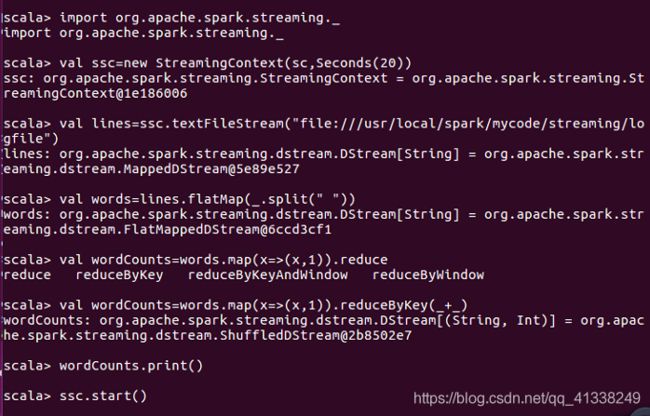
在上面的代码中,ssc.textFileStream()语句用于创建一个"文件流“类型的输入源。接下来的lines.flatMap()、words.map()和wordCounts.print()是流计算处理过程,负责是文件流中发送过来的文件内容进行词频统计。ssc.start()语句用于启动流计算过程,实际上,当在spark-shell中输入ssc.start()并按Enter键后,Spark Streaming就开始进行循环监听。
在spark-shell中输入ssc.start()以后,程序就开始自动进入循环监听状态,屏幕上会不断显示如下类似信息:
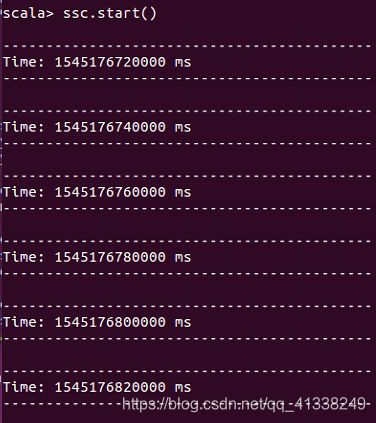
这时可以切换到第一个Linux终端(即”数据源终端“),在“/usr/local/spark/mycode/streaming/logfile"目录下新建一个log.txt文件,在文件中输入一些英文语句后保存并退出文件编辑器。然后,切换到第二个Linux终端(即“流计算终端”),最多等到20秒,就可以看到词频统计结果。
套接字流
Spark Streaming可以通过Socket端口监听并接收数据,然后进行相应处理。
在网络编程中,大量的数据交换都是通过Socket实现的。Socket工作原理和日常生活的电话交流非常类似。在日常生活中,用户A要打电话给用户B,首先,用户A拨号,用户B听到电话铃声后提起电话,这时A和B就建立起了连接,二者之间就可以通话了。等交流结束以后,挂断电话结束此次交谈。Socket工作过程也是类似的,即“open(拨电话)——write/read(交谈)——close(挂电话)”模式。
在套接字流作为数据源的应用场景中,Spark Streaming程序就是socket通信的客户端,它通过Socket方式请求数据,获取数据以后启动流计算过程进行处理。
下面编写一个Spark Streaming独立应用程序来实现这个应用场景。首先创建代码目录和代码文件NetworkWordCount.scala。关闭Linux系统中已经打开的所有终端,新建一个终端(为了便于区分,这里称为“流计算终端”),在该终端里执行如下命令:
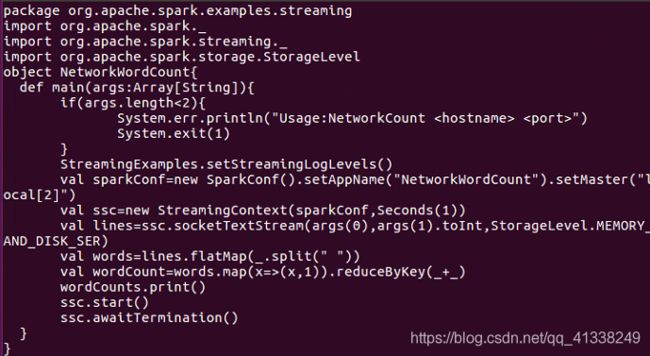
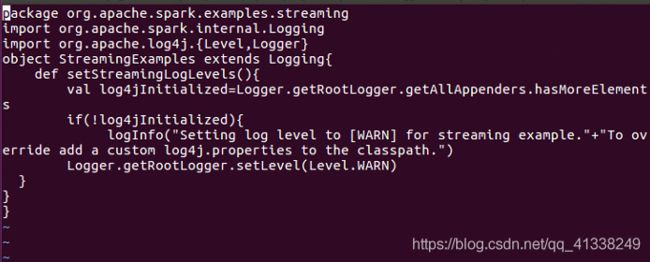
在上面代码中,StreamingExamples.setStreamingLogLevels()用于设置log4j的日志级别,从而使得在程序运行过程中,wordCounts.print() 语句的打印信息能够得到正确显示;StreamingExamples是在另一个代码文件StreamingExamples.scala中定义的。ssc.socketTextStream()用于创建一个“套接字流”类型的输入源。ssc.socketTextStream()有3个输入参数,其中,args(0)提供了主机地址,args(1).toInt提供了通信端口号,Socket客户端使用该主机地址和端口号与服务器端建立通信,StorageLevel.MEMORY_AND_DISK_SER表示Spark Streaming作为客户端,在接收到来自服务器端的数据以后,采用的存储方式为MEMORY_AND_DISK_SER,即使用内存和磁盘作为存储介质。lines.flatMap()、words.map()和wordCounts.print()是自定义的处理逻辑,用于实现对源源不断到达的流数据进行词频统计。
在于代码文件NetworkWordCount.scala相同的目录下,新建一个代码文件StreamingExamples.scala,输入如下代码: