Ubuntu16.04安装hadoop2.7.2分布式集群
Ubuntu16.04安装hadoop2.7.2分布式集群
1. 整个集群的规划
| 节点hostname | 节点IP | 角色 | master/salve |
|---|---|---|---|
| adminserver | 192.168.202.34 | NameNode、SecondaryNameNode ResourceManager、JobHistoryServer |
master |
| monserver | 192.168.202.33 | DataNode、NodeManager | slave |
| osdserver1 | 192.168.202.31 | DataNode、NodeManager | slave |
| osdserver2 | 192.168.202.32 | DataNode、NodeManager | slave |
| osdserver3 | 192.168.202.35 | DataNode、NodeManager | slave |
2. 设置静态IP以及修改主机名(每个节点均需要)
① 设置静态IP
请查看以前的博客Ubuntu16.04安装DCE2.6(开发者版本)
② 修改主机名
修改/etc/hostname,修改为对应的节点hostname:
$ sudo gedit /etc/hostname
修改/etc/hosts,将其他节点的hostname添加到hosts中。删除127.0.1.1这一条配置,直接在127.0.0.1 localhost中添以下信息:
192.168.202.34 adminserver
192.168.202.33 monserver
192.168.202.31 osdserver1
192.168.202.32 osdserver2
192.168.202.35 osdserver3
注意: 各个节点的hostname一定不能带有下划线,否则执行start-dfs.sh 时会报错:
Incorrect configuration: namenode address dfs.namenode.servicerpc-address or dfs.namenode.rpc-addres
3. 设置ssh免密登录
① 添加hadoop用户(所有节点)
这里使用已经配置好的cephlee用户,不再重新添加hadoop用户。添加hadoop用户的命令如下:
$ sudo useradd -d /home/hadoop -m hadoop
$ sudo passwd hadoop
$ echo "hadoop ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/hadoop
$ sudo chmod 0440 /etc/sudoers.d/hadoop
② 安装ssh(所有节点)
$ sudo apt-get install openssh-server
③ 配置ssh免密登录(均在master节点)
on master:
生成公钥、私钥,输入命令后一直敲击enter键,直至秘钥生成:
$ ssh-keygen -t rsa -P ""
实现localhost本地访问:
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ sudo chmod 600 ~/.ssh/authorized_keys
此时master已经可以对localhost免密访问了
$ ssh localhost
为了使master能免密访问slave(以monserver为例):
$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@monserver
$ ssh monserver
4. 安装jdk1.8(所有节点)
JDK1.7+的安装,可以查看Ubuntu 16.04配置JDK1.8.0_77教程
5. 安装Hadoop(所有节点)
① 下载hadoop-2.7.2安装包
下载地址:https://archive.apache.org/dist/hadoop/core/hadoop-2.7.2/ ,选择hadoop-2.7.2.tar.gz 点击下载。
也可以同时下载 hadoop-2.7.2.tar.gz.mds,以检验下载的安装的完整性。参考链接:检验haoop的MD5
② 解压并安装hadoop-2.7.2
将hadoop-2.7.2解压以后,复制到/usr/local目录下:
$ sudo tar -zxvf hadoop-2.7.2.tar.gz
$ sudo cp -rf hadoop-2.7.2 /usr/local
③ 配置hadoop的相关环境变量
在/etc/profile和~/.bashrc的末尾,加入以下内容:
export HADOOP_HOME=/usr/local/hadoop-2.7.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
使用source命令使配置生效:
$ source /etc/profile
$ source ~/.bashrc
以后执行任何跟hadooop有关命令,都不需要再进入Hadoop的安装目录了!
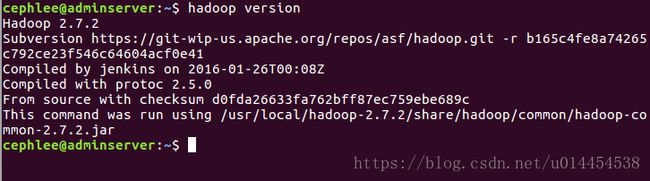
④ 查看hadoop安装是否成功
输入以下命令查看hadoop安装是否成功:
$ hadoop version
6. 配置分布式环境(所有节点)
- 配置hdoop2.x完全分布式环境,需要修改
/hadoop-2.7.2/etc/hadoop目录下的hadoop-env.sh、yarn-env.sh、slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml。 - 现在这之前需要在
/hadoop-2.7.2下创建tmp文件夹及其子目录:
$ sudo mkdir tmp
$ cd tmp
$ sudo mkdir dfs
$ cd dfs
$ sudo mkdir data
$ sudo mkdir name
可以使用以下两种命令实现对文件的修改:
$ sudo gedit filename
$ sudo vim filename
① 添加Java-home到hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk18
② 添加Java-home到yarn-env.sh
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/usr/local/jdk18
③ 添加slave主机名到slaves
monserver
osdserver1
osdserver2
osdserver3
④ 修改 core-site.xml
fs.defaultFS
hdfs://adminserver:8020
hadoop.tmp.dir
file:/usr/local/hadoop-2.7.2/tmp
Abase for other temporary directories.
注意: A. hdfs://adminserver:8020 的adminserver是主机名,和之前的hostname对应。8020是端口号,注意不要占用已用端口就可以。
B. file:/usr/local/hadoop-2.7.2/tmp 指定到刚刚创建的tmp文件夹.
C. 所有的配置文件< name >和< value >节点处不要有空格,否则会报错!!
以下几个xml文件的配置都需要注意以上几点!
⑤ 修改 hdfs-site.xml
dfs.namenode.secondary.http-address
adminserver:50090
dfs.namenode.name.dir
file:/usr/local/hadoop-2.7.2/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop-2.7.2/tmp/dfs/data
dfs.replication
3
dfs.webhdfs.enabled
true
⑥ 修改 mapred-site.xml
如果文件夹下没有这个文件,需要先执行sudo cp mapred-site.xml.template mapred-site.xml复制一份,然后再执行sudo vim mapred-site.xml命令进行修改。
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
adminserver:10020
mapreduce.jobhistory.webapp.address
adminserver:19888
⑦ 修改yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.scheduler.address
adminserver:8030
yarn.resourcemanager.address
adminserver:8032
yarn.resourcemanager.resource-tracker.address
adminserver:8031
yarn.resourcemanager.admin.address
adminserver:8033
yarn.resourcemanager.webapp.address
adminserver:8088
注意: 为了方便,第5步和第6步置只在master上进行操作,容纳后将配置好的hadoop安装包,通过scp命令拷贝到其他主机。
$ scp -r /usr/local/hadoop-2.7.2 hadoop@monserver:~/
#不能直接拷贝到 /usr/local,权限问题。需要通过ssh登陆monserver,再自行将~/文件夹下的hadoop文件拷贝到/usr/local
$ ssh monserver
$ sudo cp -rf hadoop-2.7.2 /usr/local/hadoop-2.7.2
7. 启动hadoop集群
- 由于上面的步骤中配置了hadoop的相关环境变量,下面的命令直接输入,无需进入/bin或者/sbin目录下。
- 在这之前,需要设置所有节点
hadoop-2.7.2的文件夹权限为0777:
$ sudo chmod -R 0777 /usr/local/hadoop-2.7.2
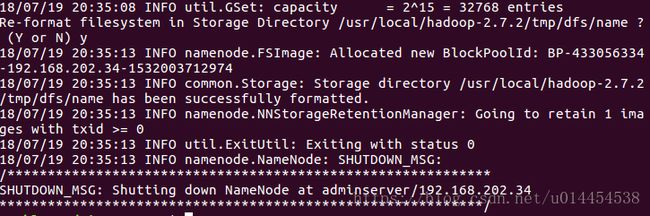
① 初始化namenode
# On Master
$ hadoop namenode -format
注意:首次运行需要执行初始化,之后不需要。
成功运行,应该返回Exitting with status 0,提示Shuting down Namenode at adminserver/xxx.xxx.xxx.xx(adminserver的IP地址),具体结果如下图所示:
② 启动Hadoop的守护进程(NameNode, DataNode, ResourceManager和NodeManager等)
- 首先启动NameNode、SecondaryNameNode、DataNode
# On Master
$ start-dfs.sh
# 此时master节点上面运行的进程有:NameNode、SecondaryNameNode
# 此时slave节点上面运行的进程有:DataNode
运行start-dfs.sh 的结果如下,可以发现NameNode、SecondaryNameNode、DataNode均已按照集群最初的设计,在相应的主机上启动 :

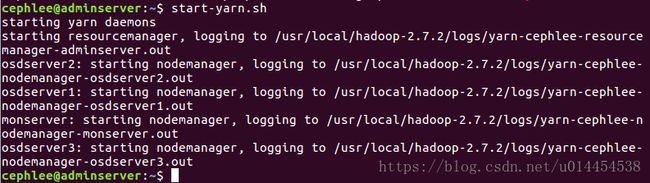
- 启动ResourceManager、NodeManager
# On Master
$ start-yarn.sh
# YARN 是从 MapReduce 中分离出来的,负责资源管理与任务调度。YARN 运行于 MapReduce 之上,提供了高可用性、高扩展性
# 此时master节点上面运行的进程有:NameNode、SecondaryNameNode、ResourceManager
# slave节点上上面运行的进程有:DataNode、NodeManager
运行start-yarn.sh 的结果如下,可以发现ResourceManager、NodeManager均已按照集群最初的设计,在相应的主机上启动 :
- 启动JobHistoryServer
# On Master
$ mr-jobhistory-daemon.sh start historyserver
# master节点将会增加一个JobHistoryServer 进程
运行mr-jobhistory-daemon.sh start historyserver 的结果如下,可以发现JobHistoryServer在master主机(adminserver)上启动 :

注意:多次重启以后,一定要删除每个节点上的logs、tmp目录,并重新创建tmp目录
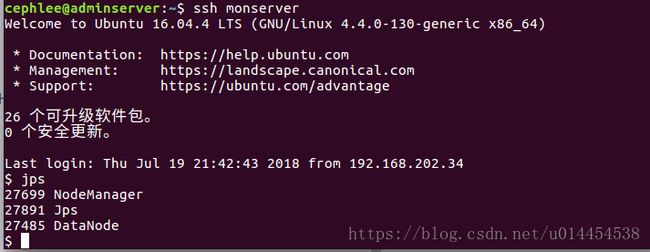
③ 查看mater和slave主机上进程
- 通过在命令行运行jps指令,可以看到当前运行在adminserve节点上的守护进程:

- 通过在命令行运行jps指令,查看在monserver、osdserver1、osdserver2和osdserver3节点上的守护进程:
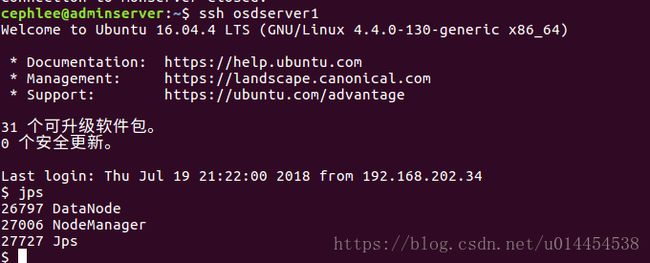
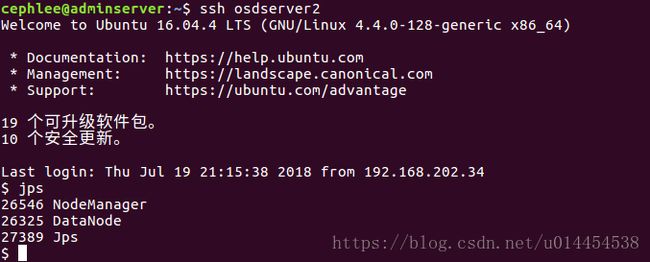
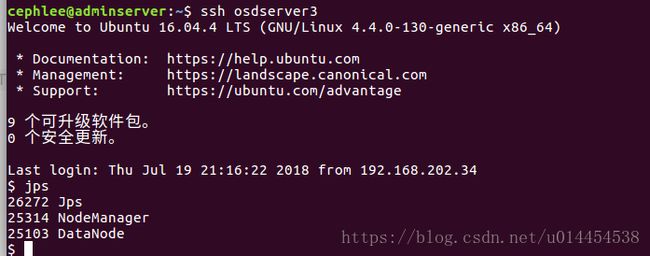
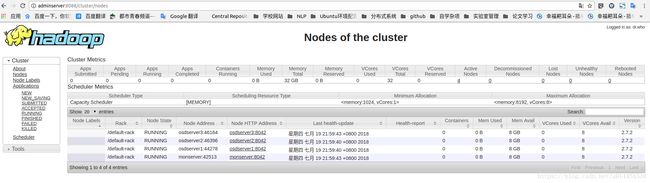
④ 通过web页面查看hadoop集群的各信息
- 查看集群信息:http://adminserver:8088/cluster/nodes
- 查看 namenode 信息:http://adminserver:50070/dfshealth.html

关于配置中出现的各种问题,请参考下一篇博客:Ubuntu16.04安装hadoop2.7.2分布式集群遇到的各种问题总结。
参考过的链接:
Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS
Ubuntu 16.04上构建分布式Hadoop-2.7.3集群
完全分布式Hadoop集群搭建(Ubuntu16.04+hadoop2.6.5)
Ubuntu16.04上构建分布式Hadoop2.7.3集群