第3章 大数据kafka采集数据(Dstream创建)
上篇:第2章 Dstream入门
Spark Streaming原生支持一些不同的数据源。一些“核心”数据源已经被打包到Spark Streaming 的 Maven
工件中,而其他的一些则可以通过 spark-streaming-kafka 等附加工件获取。每个接收器都以 Spark
执行器程序中一个长期运行的任务的形式运行,因此会占据分配给应用的 CPU 核心。此外,我们还需要有可用的 CPU
核心来处理数据。这意味着如果要运行多个接收器,就必须至少有和接收器数目相同的核心数,还要加上用来完成计算所需要的核心数。例如,如果我们想要在流计算应用中运行
10 个接收器,那么至少需要为应用分配 11 个 CPU 核心。所以如果在本地模式运行,不要使用local[1]。
1、文件数据源
用法及说明
文件数据流:能够读取所有HDFS API兼容的文件系统文件,通过fileStream方法进行读取,Spark Streaming 将会监控 dataDirectory 目录并不断处理移动进来的文件,记住目前不支持嵌套目录。
代码实现:
package com.study.bigdatabase.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming02_FoleDataSource {
def main(args: Array[String]): Unit = {
//使用SparkStreaming完成WordCount
//Sprak配置对象
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming01_WordCount")
//实时数据分析环境对象
//采集周期:以指定的时间为周期采集实时数据
val streamingContext = new StreamingContext(sparkConf,Seconds(5))
//从指定文件夹中采集数据
val fileDStream: DStream[String] = streamingContext.textFileStream("test")
//将采集的数据进行分解(扁平化)
val wordDStream: DStream[String] = fileDStream.flatMap(line => line.split(" "))
//将数据进行结构的转换方便统计分析
val mapDStream: DStream[(String, Int)] = wordDStream.map((_, 1))
//将转换结构后的数据进行聚合处理
val wordToSumDStream: DStream[(String, Int)] = mapDStream.reduceByKey(_ + _)
//将结果 打印出来
wordToSumDStream.print()
//注意:不能停止采集功能
//streamingContext.stop()
//启动采集器
streamingContext.start()
//Drvier等待采集器的执行:
streamingContext.awaitTermination()
}
}
注意事项:
1)文件需要有相同的数据格式;
2)文件进入 dataDirectory的方式需要通过移动或者重命名来实现;
3)一旦文件移动进目录,则不能再修改,即便修改了也不会读取新数据;
2、案例实操
具体代码实现:
package com.study.bigdatabase.streaming
import java.io.{BufferedReader, InputStreamReader}
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
//自定义采集器
object SparkStreaming03_MyReceiver {
def main(args: Array[String]): Unit = {
//使用SparkStreaming完成WordCount
//Sprak配置对象
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming01_WordCount")
//实时数据分析环境对象
//采集周期:以指定的时间为周期采集实时数据
val streamingContext = new StreamingContext(sparkConf,Seconds(5))
//从指定文件夹中采集数据
val receiverDStream: ReceiverInputDStream[String] = streamingContext.receiverStream(new MyReceiver("hadoop105", 9999))
//将采集的数据进行分解(扁平化)
val wordDStream: DStream[String] = receiverDStream.flatMap(line => line.split(" "))
//将数据进行结构的转换方便统计分析
val mapDStream: DStream[(String, Int)] = wordDStream.map((_, 1))
//将转换结构后的数据进行聚合处理
val wordToSumDStream: DStream[(String, Int)] = mapDStream.reduceByKey(_ + _)
//将结果 打印出来
wordToSumDStream.print()
//注意:不能停止采集功能
//streamingContext.stop()
//启动采集器
streamingContext.start()
//Drvier等待采集器的执行:
streamingContext.awaitTermination()
}
}
//声明采集器
//(1)继承Receiver
class MyReceiver(host:String,port:Int) extends Receiver[String](StorageLevel.MEMORY_ONLY) {
var socket: java.net.Socket = null
def receive(): Unit = {
socket = new java.net.Socket(host, port)
val reader: BufferedReader = new BufferedReader(new InputStreamReader(socket.getInputStream, "utf-8"))
var line: String = null
while ((line = reader.readLine()) != null) {
//将采集的数据存储到采集器的内部进行转换
if ("END".equals(line)) {
return
} else{
this.store(line)
}
}
}
override def onStart(): Unit = {
new Thread(new Runnable {
override def run(): Unit = {
receive()
}
}).start()
}
override def onStop(): Unit = {
if(socket !=null){
socket.close()
socket =null
}
}
}
(1)启动三台集群
[root@hadoop105 spark-2.1.1-bin-hadoop2.7]# start-all.sh
//查看进程
[root@hadoop105 spark-2.1.1-bin-hadoop2.7]# jps
13056 DataNode
13221 SecondaryNameNode
12135 SparkSubmit
13511 NodeManager
12952 NameNode
13820 Jps
13405 ResourceManager
(2)发送采集数据
//发送数据
[root@hadoop105 spark-2.1.1-bin-hadoop2.7]# nc -lk 9999
//打印数据内容
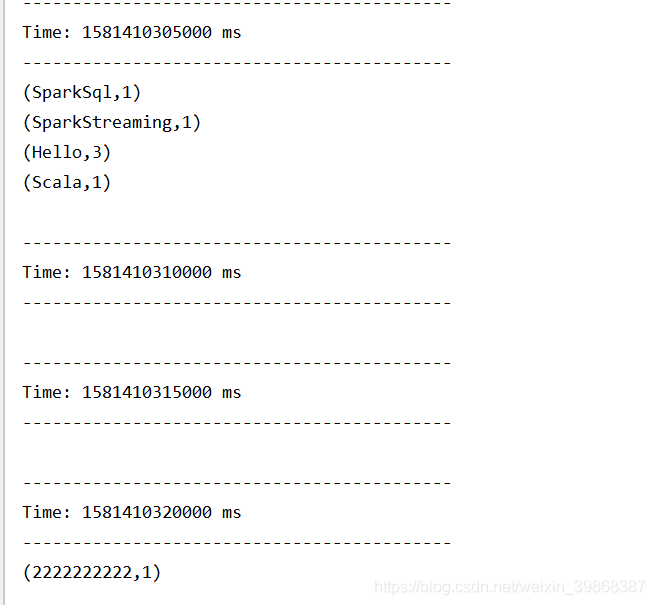
Hello Scala
Hello SparkSql
Hello SparkStreaming
2222222222
启动程序,打印数据
3、Kafka数据源(重点)
用法及说明
在工程中需要引入 Maven 工件 spark- streaming-kafka_2.10 来使用它。包内提供的 KafkaUtils
对象可以在 StreamingContext 和 JavaStreamingContext 中以你的 Kafka 消息创建出
DStream。由于 KafkaUtils 可以订阅多个主题,因此它创建出的 DStream
由成对的主题和消息组成。要创建出一个流数据,需要使用 StreamingContext 实例、一个由逗号隔开的 ZooKeeper
主机列表字符串、消费者组的名字(唯一名字),以及一个从主题到针对这个主题的接收器线程数的映射表来调用 createStream() 方法。
案例实操
需求:通过SparkStreaming从Kafka读取数据,并将读取过来的数据做简单计算(WordCount),最终打印到控制台。
(1)导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.2</version>
</dependency>
(2)启动zookeeper
//启动zookeeper
[root@hadoop105 zookeeper-3.4.5]# bin/zkServer.sh start
[root@hadoop106 zookeeper-3.4.5]# bin/zkServer.sh start
[root@hadoop107 zookeeper-3.4.5]# bin/zkServer.sh start
//查看zookeeper状态
[root@hadoop105 zookeeper-3.4.5]# bin/zkServer.sh status
JMX enabled by default
Using config: /usr/local/hadoop/module/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: follower
(4)启动kafka(shell操作)
//启动kafka
[root@hadoop105 kafka]# bin/kafka-server-start.sh config/server.properties &
[root@hadoop106 kafka]# bin/kafka-server-start.sh config/server.properties &
[root@hadoop107 kafka]# bin/kafka-server-start.sh config/server.properties &
//查看详细进程
[root@hadoop105 ~]# jps -l
13221 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
12135 org.apache.spark.deploy.SparkSubmit
13511 org.apache.hadoop.yarn.server.nodemanager.NodeManager
12952 org.apache.hadoop.hdfs.server.namenode.NameNode
14233 org.apache.zookeeper.server.quorum.QuorumPeerMain
14297 kafka.Kafka
13405 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
14877 sun.tools.jps.Jps
//显示当前topics
[root@hadoop105 kafka]# bin/kafka-topics.sh --zookeeper hadoop105:2181 --list
//创建atguigu
[root@hadoop105 kafka]# bin/kafka-topics.sh --create --zookeeper hadoop105:2181 --partitions 3 --replication-factor 2 --topic bigdata
Created topic "bigdata".
//生产者生产数据
[root@hadoop105 kafka]# bin/kafka-console-producer.sh --broker-list hadoop105:2181 --topic bigdata
//删除topic
[root@hadoop105 kafka]# bin/kafka-topics.sh --delete --zookeeper hadoop105 --topic bigdata
(5)具体代码实现:
package com.study.bigdatabase.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
//自定义采集器
object SparkStreaming04_KafkaSource {
def main(args: Array[String]): Unit = {
//使用SparkStreaming完成WordCount
//Sprak配置对象
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming01_WordCount")
//实时数据分析环境对象
//采集周期:以指定的时间为周期采集实时数据
val streamingContext = new StreamingContext(sparkConf,Seconds(5))
//从kafka中采集数据
val kafkaDStream: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(
streamingContext,
"hadoop105:2181",
"atguigu",
Map("atguigu" -> 3) //分为三个分区
)
//将采集的数据进行分解(扁平化)
val wordDStream: DStream[String] = kafkaDStream.flatMap(t=>t._2.split(" "))
//将数据进行结构的转换方便统计分析
val mapDStream: DStream[(String, Int)] = wordDStream.map((_, 1))
//将转换结构后的数据进行聚合处理
val wordToSumDStream: DStream[(String, Int)] = mapDStream.reduceByKey(_ + _)
//将结果 打印出来
wordToSumDStream.print()
//注意:不能停止采集功能
//streamingContext.stop()
//启动采集器
streamingContext.start()
//Drvier等待采集器的执行:
streamingContext.awaitTermination()
}
}
启动程序,控制台打印:
执行过程中,可能会出错:
[2020-02-11 23:00:30,172] ERROR Error when sending message to topic bigdata with key: null, value: 6 bytes with error: (org.apache.kafka.clients.producer.internals.ErrorLoggingCallback)
org.apache.kafka.common.errors.TimeoutException: Failed to update metadata after 60000 ms.
详细看错误…