MapReduce面试题(一)
MapReduce核心思想?
MapReduce的思想核心是“分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。
Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
Reduce负责“合”,即对map阶段的结果进行全局汇总。
偏移量?
每个字符移动到当前文档的最前面需要移动的字符个数。
Shuffle包含哪些步骤?
Split 、 sort 、ComBiner 、Group
分割、排序、combiner、组合
MR从读取数据开始到将最终结果写入HDFS经过哪些步骤?
第1步:InputFormat
InputFormat 到hdfs上读取数据
将数据传给Split
第2步:Split
Split将数据进行逻辑切分,
将数据传给RR
第3步:RR(RecordReader)
RR:将传入的数据转换成一行一行的数据,输出行首字母偏移量和偏移量对应的数据
将数据传给MAP
第4步:MAP
MAP:根据业务需求实现自定义代码
将数据传给Shuffle的partition
第5步:partition(分区)
partition:按照一定的分区规则,将key value的list进行分区。
将数据传给Shuffle的Sort
第6步:Sort(排序)
Sort:对分区内的数据进行排序
将数据传给Shuffle的combiner
第7步:combiner(可选)
combiner:对数据进行局部聚合。
将数据传给Shuffle的Group
第8步:Group(分组)
Group:将相同key的key提取出来作为唯一的key,
将相同key对应的value获取出来作为value的list
将数据传给Reduce
第9步:Reduce
Reduce:根据业务需求进行最终的合并汇总。
将数据传给outputFormat
第10步:outputFormat
outputFormat:将数据写入HDFS
如何设置ReduceTask的数量?
job.setNumReduceTasks()
combiner的作用?
优化网络使用
combiner运行在MapReduce的哪一端?
map端
Maptask的数量是可以人为设置的吗?
不能
Shuffle阶段的Partition分区算法是什么?
Shuffle阶段接收到键值对列表,
1,对每个Key取一个hash值。
2,用key对设置的ReduceTask的数量取余
3,余几,这个键值对数据就放在哪个分区。
算法:对key 进行哈希,获取到一个哈希值,用这个哈希值与reducetask的数量取余。余几,这个数据就放在余数编号的partition中。
Split逻辑切分数据,节分大小是多大?
128MB
内存角度介绍Map的输出到Reduce的输入的过程。
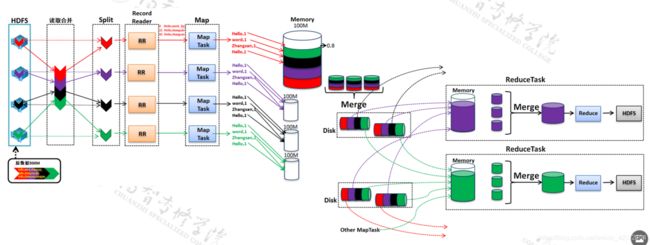
Map的输出先写入环形缓冲区(默认大小100M-可以认为调整)(可以再输出的同时写入数据),当缓冲区内的数据
达到阈值(默认0.8-可以人为调整)时,对数据进行flash。
flash 出去的数据的数量达到一定量(默认4个)时,进行数据的合并。
Map的输出先写入环形缓冲区(默认大小100M-可以认为调整)(可以在输出的同时写入数据),当缓冲区内的数据
达到阈值(默认0.8-可以人为调整)时,对数据进行flash。
flash 出去的数据的数量达到一定量(默认4个)时,进行数据的合并。
最优的Map效率是什么?
尽量减少环形缓冲区flush的次数(减少IO 的使用)
1、调大环形缓冲区的大小,将100M调更大。
2、调大环形缓冲区阈值大的大小。
3、对Map输出的数据进行压缩。(数据在压缩和解压的过程中会消耗CPU)
最优的reduce是什么?
尽量将所有的数据写入内存,在内存中进行计算。
在MR阶段,有哪些优化的点?
map
尽量减少环形缓冲区flush的次数(减少IO 的使用)
1、调大环形缓冲区的大小,将100M调更大。
2、调大环形缓冲区阈值大的大小。
3、对Map输出的数据进行压缩。(数据在压缩和解压的过程中会消耗CPU)
reduce
尽量将所有的数据写入内存,在内存中进行计算。
集群优化的核心思路是什么?
在网络带宽、磁盘IO是瓶颈的前提下
能不使用io 和网络,就不使用。
在必须使用的情况下,能少用IO 网络就少用,
所有的能够减少网络开销的、减少IO使用的可选项,都可以作为集群调优的可选项。
(软件层面(操作系统----集群层面),硬件层面,网络层面)