raft算法回顾
最近在做一个项目,简单multi-raft结构,项目的实现是将数据分布到多个group上,每个group中有多台机器,使用raft协议保证group中数据的一致性,数据的写入扩展使用增加group的方式承载,读取扩展使用增加group中集群数量承载,提升项目的容量伸缩能力,这里面用到了raft协议,简单复习记录一下,基础流程不在这里介绍。
Raft协议保证:
1 在2n+1的集群中,容忍n台机器失效
2 当client收到请求已经被commit的消息之后,数据绝对已经持久化,不会丢失。
3 当client没有收到commit消息,但是收到leader崩溃的消息,那么数据有可能被持久化,也有可能没有被持久化(这一点需要客户端和复制状态机保持幂等性)
Raft协议主要分为三部分,第一部分是数据的复制,使用复制状态机实现。第二部分是leader选举,第三部分是安全性。
数据的复制:
此时集群处于正常接受请求,处理数据的状态,此时集群只有两种状态的节点,leader节点和follower节点,leader节点接受请求,并且将请求分发到follower节点中。
过程
1 leader节点接到请求,写入本机器log,发送给follower机器。
2 follower机器写入log,返回给leader机器ack
3 leader机器接受到集群中大多数机器返回的ack,commit此条请求,并向follower节点发送commit信息。
4 follower节点接受到commit信息,commit请求。
关键点:
Raft保证
- 如果在不同的日志中的两个条目拥有相同的索引和任期号,那么他们存储了相同的指令。
- 如果在不同的日志中的两个条目拥有相同的索引和任期号,那么他们之前的所有日志条目也全部相同。
如何保证:
在第一个任期内,Leader向follower发送请求时,会将上一个请求的log_index,上一个请求的任期号一起发送过去,这里起作用的是log_index,follower接受到请求,按照log_index存放日志,所以在第一个任期内,leader和follower的log顺序一致,并且,如果任期号一致,那么相同log_index存储了相同的指令。
当任期切换的时候(leader崩溃重新选举),
如果是有最新的数据(不管是不是已经commit)的节点当选为leader,则继续向follower append entry,一致性能够保证。
如果是没有最新数据的节点当选为leader(有的节点拥有没有commit的日志),直接将follower中没有commit的日志覆盖掉,一致性也能保证。
如果出现新当选的leader已经经过了一系列的leader选举崩溃后才当选,那么在向follower append entry的时候,就会出现问题,follwoer已经在这个位置上有别的entry了,这时候任期号就出现作用了,如果follower任期号和leader的不一样,那么数据绝对不一致,follower主动向前探索任期号相同的log_index,并且从这个log_index向后进行日志的覆盖。
这样就保证了如果任期号和索引一致,那么前面所有的日志条目也全部相同。
Leader选举
Leader选举需要的三个属性:
Log的last_index,last_lndex 所属的log_term,候选人当前current_term。
选举选择current_term更大,log_term更大,last_index更大的那个。
不同于paxos算法一轮中需要经过两次确认的逻辑,raft算法一轮选举每个节点只能接受一个候选者,不能接受两个,候选者通过差异化选举开始时间保证选举leader的快速有效性。
正常leader统治依靠与follower的心跳维持,leader的心跳必须在follower选举检查周期失效前送到follower面前,否则follower会变为选举者,term+1,发送vote。
当由于网络问题,少于等于n的follower机器和leader机器网络分区后,形成小集群,小集群内部无法获得多数选票,所以不会选举出leader,网络分区恢复后,接受到leader的心跳,则重新变为follower。
当由于网络问题,大于等于n的follower机器和leader机器网络分区后,形成大集群,leader所接受到的所有的请求都无法得到多数派同意,leader不能够正常接受请求,大集群选出新的leader,并能够正常接受请求,当网络分区消失后,由于term和last_index都比小集群大,所有小集群机器全部变成新leader的follower。
安全性。
安全性即如何处理已经commit又被覆盖的问题(即已经向客户端保证数据已经commit,不会丢了,然后还丢了的情况)。
Leader崩溃后,通过多数派同意,能拿到多数派的选票的才能够成为新leader,但是leader重复崩溃这种极端情况,会出现已经commit的数据被覆盖掉的情况,这里拿算法上的一个图来表示。
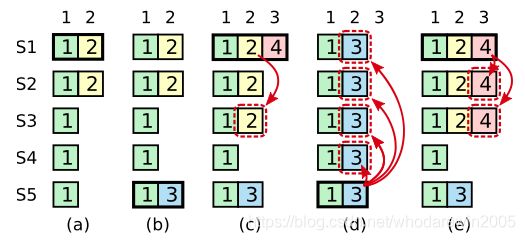
上图表示了leader重复崩溃的情况下,数据的不一致问题
图中的小方块里面的数字,说的是任期term。
在a中,任期2的leader S1崩溃,
在b中,任期3开始,并且S5当选任期3的leader,接受了一个请求后,不幸的是,S5又崩溃了。
在C中,任期4开始,S1重新当选为leader,并且同步任期2的日志到S3中,形成多数派。还接受了新的任期4中的请求。
在d中,任期5开始,s1又崩溃了,s5又重新当选为leader,这时,他先同步任期三中的数据到s1,s2,s3,s4中,再接受新的请求,已经达成多数派的任期2的数据被覆盖。
怎样解决:
这个地方的关键问题在于
1 主的log日志不能回退
2 已经commit的不能被再次覆盖
2 新任期内的主帮助旧任期内的主进行了commit操作。
那怎么办?
本任期的leader不能commit上一个任期内的记录,直到本任期内有数据需要commit,连带着上一个任期内的一起commit掉。
那么当到c的时候,2并没有被commit,到d被覆盖,没有问题,
到e,2已经被commit了,这时候S5已经无法成为leader了,也没问题。
客户端:
客户端要实现幂等,因为在leader还没来得及回应就崩溃了,我们不清楚这条数据是否已经commit了。
实现是客户端对每个请求都增加一个唯一的id,leader先检查这个id是否已经提交了,如果已经提交了,则直接返回,如果没有提交,则等待提交后再返回。