嵌入式系统开发-麦子学院(9)——arm基础知识
1. 前铺知识
1.1 电路符号

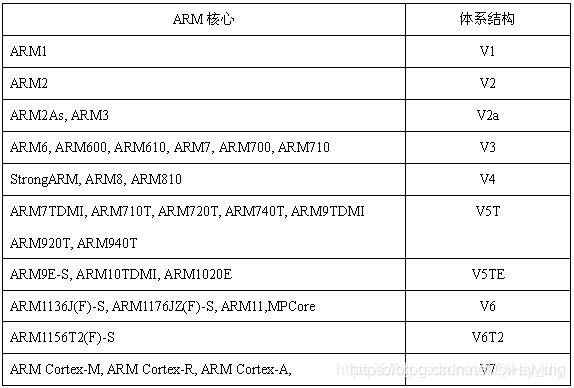
1.2 ARM cores 家族成员表
参考博文:https://blog.csdn.net/thisway_diy/article/details/84100076
ARM公司简介
ARM是Advanced RISC Machines的缩写,它是一家微处理器行业的知名企业,该企业设计了大量高性能、廉价、耗能低的RISC (精简指令集)处理器。 1985年第一个ARM原型在英国剑桥诞生。
公司的特点是只设计芯片,而不生产。它提供ARM技术知识产权(IP)核,将技术授权给世界上许多著名的半导体、软件和OEM厂商,并提供服务。有ARM7/ARM9等多个版本。除了一些Unix图形工作站外,大多数ARM核心的处理器都使用在嵌入领域。
ARM,既可以认为是一个公司的名字,也可以认为是对一类微处理器的通称,还可以认为是一种技术的名字。
ARM版本Ⅰ: V1版架构
该版架构只在原型机ARM1出现过,只有26位的寻址空间,没有用于商业产品。
其基本性能有:
- 基本的数据处理指令(无乘法);
- 基于字节、半字和字的Load/Store指令;
- 转移指令,包括子程序调用及链接指令;
供操作系统使用的软件中断指令SWI;
寻址空间:64MB(226)。
ARM版本Ⅱ: V2版架构
该版架构对V1版进行了扩展,例如ARM2和ARM3(V2a)架构。包含了对32位乘法指令和协处理器指令的支持。 版本2a是版本2的变种,ARM3芯片采用了版本2a,是第一片采用片上Cache的ARM处理器。同样为26位寻址空间,现在已经废弃不再使用。
V2版架构与版本V1相比,增加了以下功能:
- 乘法和乘加指令;
- 支持协处理器操作指令;
- 快速中断模式;
- SWP/SWPB的最基本存储器与寄存器交换指令;
- 寻址空间:64MB。
ARM版本Ⅲ : V3版架构
ARM作为独立的公司,在1990年设计的第一个微处理器采用的是版本3的ARM6。它作为IP核、独立的处理器、具有片上高速缓存、MMU和写缓冲的集成CPU。 变种版本有3G和3M。版本3G是不与版本2a向前兼容的版本3,版本3M引入了有符号和无符号数乘法和乘加指令,这些指令产生全部64位结果。
V3版架构( 目前已废弃 )对ARM体系结构作了较大的改动:
- 寻址空间增至32位(4GB);
- 当前程序状态信息从原来的R15寄存器移到当前程序状态寄存器CPSR中(Current Program Status Register);
- 增加了程序状态保存寄存器SPSR(Saved Program Status Register);
- 增加了两种异常模式,使操作系统代码可方便地使用数据访问中止异常、指令预- - 取中止异常和未定义指令异常。;
- 增加了MRS/MSR指令,以访问新增的CPSR/SPSR寄存器;
- 增加了从异常处理返回的指令功能。
ARM版本Ⅳ : V4版架构
V4版架构在V3版上作了进一步扩充,V4版架构是目前应用最广的ARM体系结构,ARM7、ARM8、ARM9和StrongARM都采用该架构。 V4不再强制要求与26位地址空间兼容,而且还明确了哪些指令会引起未定义指令异常。
指令集中增加了以下功能:
- 符号化和非符号化半字及符号化字节的存/取指令;
- 增加了T变种,处理器可工作在Thumb状态,增加了16位Thumb指令集;
- 完善了软件中断SWI指令的功能;
- 处理器系统模式引进特权方式时使用用户寄存器操作;
- 把一些未使用的指令空间捕获为未定义指令
ARM版本Ⅴ : V5版架构
V5版架构是在V4版基础上增加了一些新的指令,ARM10和Xscale都采用该版架构。
这些新增命令有:
- 带有链接和交换的转移BLX指令;
- 计数前导零CLZ指令; BRK中断指令;
- 增加了数字信号处理指令(V5TE版);
- 为协处理器增加更多可选择的指令;
- 改进了ARM/Thumb状态之间的切换效率;
- E—增强型DSP指令集,包括全部算法操作和16位乘法操作;
- J----支持新的JAVA,提供字节代码执行的硬件和优化软件加速功能。
ARM版本Ⅵ : V6版架构
V6版架构是2001年发布的,首先在2002年春季发布的ARM11处理器中使用。在降低耗电量地同时,还强化了图形处理性能。通过追加有效进行多媒体处理的SIMD(Single Instruction, Multiple Data,单指令多数据 )功能,将语音及图像的处理功能提高到了原型机的4倍。
此架构在V5版基础上增加了以下功能:
- THUMBTM:35%代码压缩;
- DSP扩充:高性能定点DSP功能;
- JazelleTM:Java性能优化,可提高8倍;
- Media扩充:音/视频性能优化,可提高4倍
ARM版本ⅤⅡ: V7版架构
V7架构是在ARMv6架构的基础上诞生的。该架构采用了Thumb-2技术,它是在ARM的Thumb代码压缩技术的基础上发展起来的, 并且保持了对现存ARM解决方案的完整的代码兼容性。Thumb-2技术比纯32位代码少使用31%的内存,减小了系统开销。同时能够提供比已有的基于Thumb技术的解决方案高出38%的性能。
ARMv7架构还采用了NEON技术,将DSP和媒体处理能力提高了近4倍,并支持改良的浮点运算,满足下一代3D图形、游戏物理应用以及传统嵌入式控制应用的需求。此外,ARMv7还支持改良的运行环境,以迎合不断增加的JIT(Just In Time)和DAC(DynamicAdaptive Compilation)技术的使用。
ARM版本ⅤⅢ: V8版架构
v8架构是在32位ARM架构上进行开发的,将被首先用于对扩展虚拟地址和64位数据处理技术有更高要求的产品领域,如企业应用、高档消费电子产品。ARMv8架构包含两个执行状态:AArch64和AArch32。AArch64执行状态针对64位处理技术,引入了一个全新指令集A64;而AArch32执行状态将支持现有的ARM指令集。目前的ARMv7架构的主要特性都将在ARMv8架构中得以保留或进一步拓展,如:TrustZone技术、虚拟化技术及NEON advanced SIMD技术等。
ARM微处理器核心以及体系结构的发展历史
1)ARM7处理器
ARM7处理器采用了ARMV4T(冯·诺依曼)体系结构,这种体系结构将程序指令存储器和数据存储器合并在 一起。主要特点就是程序和数据共用一个存储空间,程序指令存储地址和数据存储地址指向同一个存储器的不同物理位置,采用单一的地址及数据总线,程序指令和 数据的宽度相同。这样,处理器在执行指令时,必须先从存储器中取出指令进行译码,再取操作数执行运算。
总体来说ARM7体系结构具有三级流水、空间统一的 指令与数据Cache、平均功耗为0.6mW/MHz、时钟速度为66MHz、每条指令平均执行1.9个时钟周期等特性。其中的ARM710、ARM720和ARM740为内带Cache的ARM核。
ARM7指令集同Thumb指令集扩展组合在一起,可以减少内存容量和系统成本。同时,它还利用嵌入式ICE调试技术来简化系统设计,并用一个DSP增强扩展来改进性能。ARM7体系结构是小型、快速、低能耗、集成式的RISC内核结构。该产品的典型用途是数字蜂窝电话和硬盘驱动器等,目前主流的ARM7内核是ARM7TDMI、ARM7TDMI-S、ARM7EJ-S、ARM720T。
现在市场上 用得最多的ARM7处理器有Samsung公司的S3C44BOX与S3C4510处理器、Atmel公司的AT91FR40162系列处理器、Cirrus公司的EP73xx系列等。通常来说前两三年大部分手机基带部分的应用处理器基本上都以ARM7为主。还有很多的通信模块,如CDMA模块、GPRS模块和GPS模块中都含有ARM7处理器。
2)ARM9、ARM9E处理器
ARM9处理器采用ARMV4T(哈佛)体系结构。这种体系结构是一种将程序指令存储和数据存储分开的存储器 结构,是一种并行体系结构。其主要特点是程序和数据存储在不同的存储空间中,即程序存储器和数据存储器。它们是两个相互独立的存储器,每个存储器独立编 址、独立访问。与两个存储器相对应的是系统中的4套总线,程序的数据总线和地址总线,数据的数据总线和地址总线。这种分离的程序总线和数据总线可允许在一 个机器周期内同时获取指令字和操作数,从而提高了执行速度,使数据的吞吐量提高了一倍。又由于程序和数据存储器在两个分开的物理空间中,因而取指和执行能 完全重叠。
ARM9采用五级流水处理及分离的Cache结构,平均功耗为0.7mW/MHz。时钟速度为120MHz~200MHz,每条指令平均执行1.5个时钟周期。与ARM7处理器系列相似,其中的ARM920、ARM940和ARM9E处理器均为含有Cache的CPU核,性能为132MIPS(120MHz时钟,3.3V供电)或220MIPS(200MHz时钟)。
ARM9处理器同时也配备Thumb指令扩展、调试和Harvard总线。在生产工艺相同的情况下,性能是ARM7TDMI处理器的两倍之多。常用于无线设备、仪器仪表、联网设备、机顶盒设备、高端打印机及 数码相机应用中。
ARM9E内核是在ARM9内核的基础上增加了紧密耦合存储器TCM及DSP部分。目前主流的ARM9内核是ARM920T、ARM922T、ARM940。相关的处理器芯片有Samsung公司的S3C2510、Cirrus公司的EP93xx系列等。主流的ARM9E内核是ARM926EJ-S、ARM946E-S、ARM966E-S等。目前市场上常见的PDA,比如说PocketPC中一般都是用ARM9处理器,其中以Samsung公司的S3C2410处理器居多。
3)ARM10E处理器
ARM10E处理器采用ARMVST体系结构,可以分为六级流水处理,采用指令与数据分离的Cache结构, 平均功耗1000mW,时钟速度为300MHz,每条指令平均执行1.2个时钟周期。ARM10TDMI与所有ARM核在二进制级代码中兼容,内带高速32×16 MAC,预留DSP协处理器接口。其中的VFP10(向量浮点单元)为七级流水结构。其中的ARM1020T处理器则是由ARMl0TDMI、32KB指 令、数据Caches及MMU部分构成的。其系统时钟高达300MHz时钟,指令Cache和数据Cache分别为32KB,数据宽度为64位,能够支持 多种商用操作系统,适用于下一代高性能手持式因特网设备及数字式消费类应用。主流的ARM10内核是ARM1020E、ARM1022E、ARM1026EJ-S等。
4)SecurCore处理器
SecurCore系列处理器提供了基于高性能的32位RISC技术的安全解决方案,该系列处理器具有体积 小、功耗低、代码密度大和性能高等特点。另外最为特别的就是该系列处理器提供了安全解决方案的支持。采用软内核技术,以提供最大限度的灵活性,以及防止外 部对其进行扫描探测,提供面向智能卡的和低成本的存储保护单元MPU,可以灵活地集成用户自己的安全特性和其他的协处理器,目前含有SC100、SC110、SC200、SC210 4种产品。
5)StrongARM处理器
StrongARM处理器采用ARMV4T的五级流水体系结构。目前有SA110、SA1100、SA1110等3个版本。另外Intel公司的基于ARMv5TE体系结构的XScale PXA27x系列处理器,与StrongARM相比增加了I/D Cache,并且加入了部分DSP功能,更适合于移动多媒体应用。目前市场上的大部分智能手机的核心处理器就是XScale系列处理器。
6)ARM11处理器
ARM11系列微处理器是ARM公司近年推出的新一代RISC处理器,它是ARM新指令架构——ARMv6的第一代设计实现。该系列主要有ARM1136J,ARM1156T2和ARM1176JZ三个内核型号,分别针对不同应用领域。
ARM11处理器系列可以在使用130nm代工厂技术、小至2.2mm2芯片面积和低 至0.24mW/MHz的前提下达到高达500MHz的性能表现。ARM11处理器系列以众多消费产品市场为目标,推出了许多新的技术,包括针对媒体处理 的SIMD,用以提高安全性能的TrustZone技术,智能能源管理(IEM),以及需要非常高的、可升级的超过2600 Dhrystone 2.1 MIPS性能的系统多处理技术。主要的ARM11处理器有ARM1136JF-S、ARM1156T2F-S、ARM1176JZF-S、ARM11 MCORE等多种。
7)Cortex系列处理器
ARM Cortex-M系列支持Thumb-2指令集(Thumb指令集的扩展集),可以执行所有已存的为早期处理器编写的代码。通过一个前向的转换方式, 为ARM Cortex-M系列处理器所写的用户代码可以与ARM Cortex-R系列微处理器完全兼容。
ARMCortex-M系列系统代码(如实时操作系统)可以很容易地移植到基于ARM Cortex-R系列的系统上。ARMCortex-A和Cortex-R系列处理器还支持ARM 32位指令集,向后完全兼容早期的ARM处理器,包括从1995年发布的ARM7TDMI处理器到2002年发布的ARMll处理器系列。
1.3 arm相关术语
1)流水线
原文:https://blog.csdn.net/hudieping/article/details/5044859
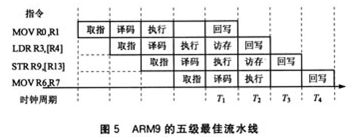
流水线技术通过多个功能部件并行工作来缩短程序执行时间,提高处理器的效率和吞吐率。ARM7是冯·诺依曼结构,采用了典型的三级流水线,而ARM9则是哈佛结构,采用五级流水线技术,而ARM11则更是使用了7级流水线。通过增加流水线级数,简化了流水线的各级逻辑,进一步提高了处理器的性能。
在ARM7中,执行单元完成了大量的工作,包括与操作数相关的寄存器和存储器的读写操作、ALU操作和相关器件之间的数据传输,因此占用了多个时钟周期。ARM9增加了两个功能部件,分别访问存储器并写回结果,同时,ARM9将读寄存器的操作转移到译码部件上,使得流水线各部件的功能更平衡。
三级流水线的最佳运行图

五级流水线的最佳运行图
在执行的过程中,通过R15寄存器直接访问PC的时候,必须考虑此事流水线执行过程的真实情况。程序计数器R15(PC)总是指向取指的指令,而不是指向正在执行的指令或者正在译码的指令。一般情况下,人们总是习惯把正在执行的指令作为参考点,称之为当前第1条指令,因此PC总是指向第3条指令。
对于ARM状态下指令,PC值=当前程序执行位置+8;对与Thumb指令,则PC值=当前程序执行位置+4.
三级流水线有它的缺点,当出现多周期指令、跳转分支指令和中断发生的时候,流水线都会发生阻塞,而且相邻指令之间也可能因为寄存器冲突导致流水线阻塞,降低流水线效率。
带分支情况下:
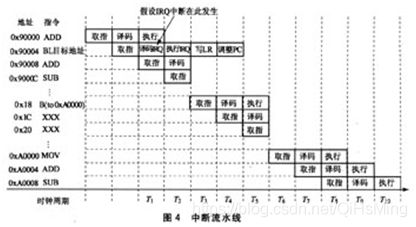
当指令序列中含有具有分支功能的指令(如BL等)时,流水线也会被阻断,如图3所示。分支指令在执行时,其后第1条指令被译码,其后第2条指令进行取指,但是这两步操作的指令并不被执行。因为分支指令执行完毕后,程序应该转到跳转的目标地址处执行,因此在流水线上需要丢弃这两条指令,同时程序计数器就会转移到新的位置接着进行取指、译码和执行。此外还有一些特殊的转移指令需要在跳转完成的同时进行写链接寄存器、程序计数寄存器,如BL执行过程中包括两个附加操作——写链接寄存器和调整程序指针。这两个操作仍然占用执行单元,这时处于译码和取指的流水线被阻断了。
中断流水线
处理器中断的发生具有不确定性,与当前所执行的指令没有任何关系。在中断发生时,处理器总是会执行完当前正被执行的指令,然后去响应中断。如图4所示,在Ox90000处的指令ADD执行期间IRQ中断发生,这时要等待ADD指令执行完毕,IRQ才获得执行单元,处理器开始处理IRQ中断,保存程序返回地址并调整程序指针指向Oxl8内存单元。在Oxl8处有IRO中断向量(也就是跳向IRQ中断服务的指令),接下来执行跳转指令转向中断服务程序,流水线又被阻断,执行0x18处指令的过程同带有分支指令的流水线。
五级流水线也有它的缺点,即使存在一种互锁,即寄存器冲突。读寄存器是在译码阶段,写寄存器是在回写阶段。如果当前指令(A)的目的操作数寄存器和下一条指令(B)的源操作数寄存器一致,B指令就需要等A回写之后才能译码。这就是五级流水线中的寄存器冲突。
虽然流水线互锁会增加代码执行时间,但是为初期的设计者提供了巨大的方便,可以不必考虑使用的寄存器会不会造成冲突;而且编译器以及汇编程序员可以通过重新设计代码的顺序或者其他方法来减少互锁的数量。另外分支指令和中断的发生仍然会阻断五级流水线。
2 )DSP
DSP(digital signal processor)是一种独特的微处理器,有自己的完整指令系统,是以数字信号来处理大量信息的器件。其最大特点是内部有专用的硬件乘法器和哈佛总线结构对大量的数字信号处理的速度快。一个数字信号处理器在一块不大的芯片内包括有控制单元、运算单元、各种寄存器以及一定数量的存储单元等等,在其外围还可以连接若干存储器,并可以与一定数量的外部设备互相通信,有软、硬件的全面功能,本身就是一个微型计算机。DSP采用的是哈佛设计,即数据总线和地址总线分开,使程序和数据分别存储在两个分开的 空间,允许取指令和执行指令完全重叠。
DSP芯片一般具有如下主要特点:
(1)在一个指令周期内可完成一次乘法和一次加法;
(2)程序和数据空间分开,可以同时访问指令和数据;
(3)片内具有快速RAM,通常可通过独立的数据总线在两块中同时访问;
(4)具有低开销或无开销循环及跳转的硬件支持;
(5)快速的中断处理和硬件I/O支持;
(6)具有在单周期内操作的多个硬件地址产生器;
(7)可以并行执行多个操作;
(8)支持流水线操作,使取指、译码和执行等操作可以重叠执行。
3)Jazelle
Jazelle是ARM体系结构的一种相关技术,用于在处理器指令层次对JAVA加速。
Jazelle 技术是 ARM 提供的组合型硬件和软件解决方案。ARM Jazelle 技术软件是功能丰富的多任务 Java 虚拟机 (JVM),经过高度优化,可利用许多 ARM 处理器内核中提供的 Jazelle 技术架构扩展。
可从 50 多个 ARM 芯片合作伙伴那里获取 ARM Jazelle 技术硬件扩展。ARM Jazelle 技术软件预先集成在一系列 ARM 软件合作伙伴提供的完整 Java 平台中。
高性能
- Jazelle DBX 广泛用于为移动设备和其他消费类设备提供高性能 Java,同时不会影响内存消耗、电池寿命或用户体验。
- Jazelle RCT 可显著降低与 AOT 和 JIT 编译关联的代码膨胀,从而使 AOT 技术能够应用于大众市场设备。
- 此外,Jazelle RCT 还可用于支持 Java 之外的执行环境,例如 Microsoft .NET Compact Framework、Python 和其他环境。
卓越的用户体验
- 由于 JIT 编译开销而导致应用程序在执行中暂停或启动慢的影响对用户来说可能会非常显著,如果游戏暂停 1 秒钟,则表明设备不可用。
- 在使用 JIT 时,可通过 Jazelle DBX 来改善用户体验和启动时间,并减少内存开销,方法是减少运行时编译量或彻底替换该 JIT。
- 使用 Jazelle RCT 可使 AOT 编译得到更广泛地应用,还可在超高频率的平台上结合使用 Jazelle RCT 与 JIT 技术,以缩短启动时间和减少流畅问题
系统成本低,并在行业内得到广泛采用
- Jazelle DBX 和 Jazelle RCT 解决方案可提供高效的高速缓存和内存,从而可在维持低功耗的同时通过高效内存和高速缓存利用率维持较低的系统成本。
- Jazelle DBX 是一种经证实的强大解决方案,可与领先的第三方软件供应商提供的 Java 平台集成,并整合到全世界大多数领先手机供应商提供的解决方案以及非移动消费类设备(如蓝光播放器)中。
- Jazelle DBX 易于集成,不需要花费时间来针对不同平台和应用领域进行编译器调节。多数 Java 平台供应商均支持该产品。
- Jazelle RCT 为所有运行时编译技术(包括 .NET MSIL 的 JIT 和 AOT、Python 和 Perl 以及 Java)提供卓越的应用目标。ARM 正在与领先的软件提供商合作,以准备向市场推出 Jazelle RCT 解决方案。
提供选择
通过开发 ARM 架构扩展、我们的软件产品以及发展行业合作,ARM 使我们的合作伙伴能够为执行环境提供最佳解决方案。
例如,对于 Java 平台,开发人员可以选择:
- 对资源受限设备单独实现 Jazelle DBX,在这些设备中,编译器的可用内存或 JIT 编译时间开销平均值 AOT 或 JIT 不适合。
- 在支持 Jazelle DBX 和 Jazelle RCT 的中型平台上,同时使用这两种解决方案(其中 Jazelle DBX 针对解释的
Java 执行,Jazelle RCT 针对对用户体验问题(如启动时间)敏感的平台上的选择性 AOT)。 - 将 Jazelle RCT 用于 JIT 和 AOT,以及使用 Jazelle DBX 减少对用户体验问题(如启动时间)敏感的平台上有关
JIT 的启动时间和用户体验问题。 - 在高端平台上,将 Jazelle RCT 单独用于 JIT 和 AOT(因为平台可能以 GHz 的频率运行),这样会减少启动时间等问题。
4)ARM Thumb Thumb-2 Thumb-2EE指令集
概念
Thumb 指令
为以 Thumb 状态运行的、基于 ARM 体系结构的处理器的操作进行编码的一个半字或两个半字。 Thumb 指令必须为半字对齐。
Thumb 状态
执行 Thumb 指令的处理器工作在 Thumb 状态。 当直接通过 BX、BLX 等指令完成时,处理器可切换到 ARM 状态(以识别 ARM 指令)。
Thumb-2 指令
Thumb-2 是 Thumb 指令集的一项主要增强功能,并且由 ARMv6T2 和 ARMv7M体系结构定义。 Thumb-2 提供了几乎与 ARM 指令集完全一样的功能。 它兼有16 位和 32 位指令,并可检索与 ARM 类似的性能,但其代码密度与 Thumb 代码类似。
Thumb-2EE 指令
Thumb-2 执行环境 (Thumb-2EE) 由 ARMv7 体系结构定义。 Thumb-2EE 指令集基于 Thumb-2,前者进行了一些更改和添加,使得动态生成的代码具有更好的目标,也就是说,就在执行之前或在执行过程中即可在该设备上编译代码。Thumb-2EE是专为一些语言如Limbo、Java、C#、Perl和Python,并能让实时编译器能够输出更小的编译码却不会影响到性能。
ThumbEE所提供的新功能,包括在每次访问指令时自动检查是否有无效指针,以及一种可以运行数组范围检查的指令,并能够分支到分类器,其包含一小部份经常调用的编码,通常用于高级语言功能的实现,例如对一个新对象做存储器配置。
ThumbEE 状态
执行 Thumb-2EE 指令的处理器正在以 ThumbEE 状态运行。 在此状态下,该指令集几乎与 Thumb 指令集相同。 不过,有些指令已经修改了行为,有些原有的指令已不再提供,另外还新添了一些指令。
说明
- 在ARM体系结构中,ARM指令集中的指令是32位的指令,其执行效率非常高。
- 对于存储系统数据总线为16位的应用系统,ARM体系提供了Thumb指令集。
- Thumb指令集是对ARM指令集的一个子集重新编码得到的,指令长度为16位。
- 通常在处理器执行ARM程式时,称处理器处于ARM状态;当处理器执行Thumb程式时,称处理器处于Thumb状态。
- Thumb指令集并没有改动ARM体系地层的程式设计模型,只是在该模型上加上了一些限制条件。
- Thumb指令集中的数据处理指令的操作数仍然为32位,指令寻址地址也是32位的。
5) TrustZone
TrustZone是ARM针对消费电子设备设计的一种硬件架构,其目的是为消费电子产品构建一个安全框架来抵御各种可能的攻击。
TrustZone在概念上将SoC的硬件和软件资源划分为安全(Secure World)和非安全(Normal World)两个世界,所有需要保密的操作在安全世界执行(如指纹识别、密码处理、数据加解密、安全认证等),其余操作在非安全世界执行(如用户操作系统、各种应用程序等),安全世界和非安全世界通过一个名为Monitor Mode的模式进行转换,如图1:
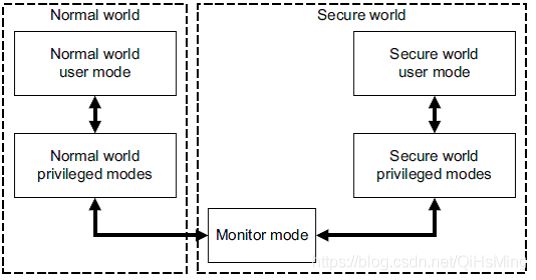
图1. ARM的安全世界和非安全世界
处理器架构上,TrustZone将每个物理核虚拟为两个核,一个非安全核(Non-secure Core, NS Core),运行非安全世界的代码;和另一个安全核(Secure Core),运行安全世界的代码。
两个虚拟的核以基于时间片的方式运行,根据需要实时占用物理核,并通过Monitor Mode在安全世界和非安全世界之间切换,类似同一CPU下的多应用程序环境,不同的是多应用程序环境下操作系统实现的是进程间切换,而Trustzone下的Monitor Mode实现了同一CPU上两个操作系统间的切换。
AMBA3 AXI(AMBA3
Advanced eXtensble Interface)系统总线作为TrustZone的基础架构设施,提供了安全世界和非安全世界的隔离机制,确保非安全核只能访问非安全世界的系统资源,而安全核能访问所有资源,因此安全世界的资源不会被非安全世界(或普通世界)所访问。
设计上,TrustZone并不是采用一刀切的方式让每个芯片厂家都使用同样的实现。总体上以AMBA3 AXI总线为基础,针对不同的应用场景设计了各种安全组件,芯片厂商根据具体的安全需求,选择不同的安全组件来构建他们的TrustZone实现。
其中主要的组件有:
必选组件
AMBA3 AXI总线,安全机制的基础设施
虚拟化的ARM Core,虚拟安全和非安全核
TZPC (TrustZone Protection Controller),根据需要控制外设的安全特性
TZASC (TrustZone Address Space Controller),对内存进行安全和非安全区域划分和保护
可选组件
TZMA (TrustZone Memory Adapter),片上ROM或RAM安全区域和非安全区域的划分和保护
AXI-to-APB bridge,桥接APB总线,配合TZPC使APB总线外设支持TrustZone安全特性
除了以上列出的组件外,还有诸如 Level 2 Cache Controller, DMA Controller, Generic Interrupt Controller等。
逻辑上,安全世界中,安全系统的OS提供统一的服务,针对不同的安全需求加载不同的安全应用TA(Trusted Application)。 例如:针对某具体DRM的TA,针对DTCP-IP的TA,针对HDCP 2.0验证的TA等。
图2是一个ARM官网对TrustZone介绍的应用示意图:
 图2. 基于TrustZone的应用示意图
图2. 基于TrustZone的应用示意图
图中左边蓝色部分Rich OS Application Environment(REE)表示用户操作环境,可以运行各种应用,例如电视或手机的用户操作系统,图中右边绿色部分Trusted Execution Envrionment(TEE)表示系统的安全环境,运行Trusted OS,在此基础上执行可信任应用,包括身份验证、授权管理、DRM认证等,这部分隐藏在用户界面背后,独立于用户操作环境,为用户操作环境提供安全服务。
6) VFP(Vector Floating Point)
ARM的vector float-point遵循IEEE754-1985的标准。
单精度浮点数用32位表示

双精度浮点数用2个32位数表示

VFP有32个32位的通用寄存器S0S31,用于单精度浮点数存储。D0D15用于表示双精度浮点数,Sx和Dx是叠加的寄存器,也就是说D0就是S0、S1。

7) NEON
Neon (ARM架构处理器扩展结构)
ARM NEON 是适用于ARM Cortex-A和Cortex-R52系列处理器的一种128位SIMD(single instruction multiple data, 单指令多数据)扩展结构。
ARM CPU最开始只有普通的寄存器,可以进行基本数据类型的基本运算。自ARMv5开始引入了VFP(Vector Floating Point)指令,该指令用于向量化加速浮点运算。自ARMv7开始正式引入NEON指令,NEON性能远超VFP,因此VFP指令被废弃。类似于Intel CPU下的MMX/SSE/AVX/FMA指令,ARM CPU的NEON指令同样是通过向量化来进行速度优化。使用场景包含但不局限于:
-
灵活的视频转码(Flexible video transcoding)
-
声音识别、先进的语音处理(Speech Recognition,Advanced audio processing)
-
视频捕获增强(Enhanced captured video)
-
计算机视觉AR/VR(Computer Vision)
-
机器学习及深度学习(Machine and deep learning)
-
游戏及先进的人机交互界面(Gaming, Advanced user interface)
关于SIMD(单指令多数据)和SISD(单指令单数据)。以加法指令为例,单指令单数据(SISD)的CPU对加法指令译码后,执行部件先访问内存,取得第一个操作数;之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。这个特点使SIMD特别适合于多媒体应用等数据密集型运算:
NEON技术是从ARMv7-A和ARMv7-R指令集引入的,目前已经扩展到了ARMv8-A和ARMv8-R指令集。
NEON技术旨在通过加速多媒体(video/audio)编解码,用户界面,2D/3D图形及游戏来提高人对多媒体的体验度。
NEON也可以通过加速信号处理算法和函数来加快应用程序,比如音频和视频处理,语音和面部识别,计算机视觉和深度学习。
如何使用
OpenMAX DL 库: 加速 AV 编解码器的建议方法
以源格式释放的库,在 ARM 网站上免费提供 支持以下格式:MPEG-4 简单配置文件、H.264 基准、JPEG、MP3、AAC
支持以下功能:FIR、IIR、FFT、点积、色彩空间转换、de-blocking、de-ringing、旋转、缩放、合成
矢量化编译器
使用现有源代码自动搜索 NEON SIMD 受 ARM RealView 开发套件(v3.1 Pro 及更高版本)支持 在 2007q3及更高版本中受 gcc 支持
内部函数
C 函数调用接口至 NEON 操作
支持 NEON 支持的所有数据类型和操作
在 ARM RealView 开发套件(3.1 及更高版本)和 gcc 2007q3 及更高版本中受支持
汇编器
针对确实需要在最低级别进行优化的用户 在 ARM 的 RealView 开发套件(3.1 及更高版本)和 gcc 2007q3 及更高版本中受支持
开源社区中的 NEON 支持
当前,在以下开源项目中支持 NEON:
Android – NEON 优化 使用 NEON,Skia 库 S32A_D565_Opaque 的速度加快了 5 倍
Ubuntu 09.04 支持 NEON: 关键共享库的 NEON 版本
Bluez – 官方 Linux 蓝牙协议堆栈 NEON SBC 音频编码器
Pixman(Cairo 2D 图形库的一部分) 合成/alpha 混合Mozilla Firefox、Fennec 和 Webkit 浏览器
例如,使用 NEON 后,fbCompositeSolidMask_nx8x0565neon 的速度提高了 8 倍 ffmpeg -> libavcodec 用于众多 Linux 分发版的 LGPL 媒体播放器
视频:MPEG-2、MPEG-4ASP、H.264 (AVC)、VC1
音频:Ogg Vorbis x264 – Google 2009 年度编程之夏 GPL h.264 编码器 –
例如,针对视频会议
工具
1. busybox
BusyBox 是一个集成了三百多个最常用Linux命令和工具的软件。BusyBox 包含了一些简单的工具,例如ls、cat和echo等等,还包含了一些更大、更复杂的工具,例grep、find、mount以及telnet。有些人将 BusyBox 称为 Linux 工具里的瑞士军刀。简单的说BusyBox就好像是个大工具箱,它集成压缩了 Linux 的许多工具和命令,也包含了 Android 系统的自带的shell。
Busybox在编写过程中对文件大小进行了优化,并考虑了系统资源有限(比如内存等)的情况。与一般的GNU工具集动辄几M的体积相比,动态链接的Busybox只有几百K,即使是采用静态链接也只有1M左右。Busybox按模块设计,可以很容易地加入、去除某些命令,或增减命令的某些选项。
在创建根文件系统的时候,如果使用Busybox的话,只需要在/dev目录下创建必要的设备节点,在/etc目录下增加一些配置文件即可,当然,如果Busybox使用动态链接,那么还需要再/lib目录下包含库文件。
Busybox目录结构简介
下面是Busybox源码目录结构图,接下来说说各个目录的作用,方便以后对Busybox做裁剪的时候参考。
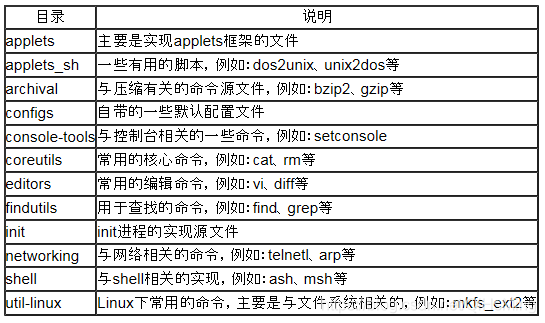
更多介绍 :https://blog.csdn.net/sunxiaopengsun/article/details/79446813
2. 交叉编译模拟环境sbox2
scratchbox2(简称sbox2)是一个交叉编译模拟器,可以模拟ARM、X86、MIPS等平台。scratchbox2是scratchbox1的第二版。但是第二版完全舍弃的第一版,在使用上第二版比第一版方便、易用很多。
2009年4月,Scratchbox2正式发布,2010年3月,Nokia正式接手scratchbox2 的维护工作。Nokia接手Scratchbox2的目的很明显,就是为Maemo手机平台提供一个模拟的软件开发环境。
Scratchbox2的使用要配合qemu、交叉工具链和目标平台的根文件系统来使用。qemu是目标平台的CPU虚拟机,如ARM的虚拟机是qemu-arm。交叉工具链可以是自己制作的,或者从CodeSourcery网站等下载的交叉编译工具链。根文件系统是目标平台的根文件系统。
更多:https://blog.csdn.net/langxing0508/article/details/5861574
3. 交叉编译工具简介
① addr2line: 把程序地址转换为文件名和行号。
② ar: 建立、修改、提取归档文件。
③ as: 用来编译gcc输出的汇编文件。
④ ld: GNU链接器。
⑤ nm: 列出目标文件中的符号。
⑥ objcopy: 文件格式转换。
⑦objdump: 显示一个或者多个目标文件的信息,主要用来反编译的。
⑧ranlib: 产生归档文件索引,并生成归档文件。
⑨readelf: 显示elf格式可执行文件的信息。
a.size: 列出目标文件每一段的大小以及总体的大小。
b.strings: 打印某个文件的可打印字符串。
c.strip: 丢弃目标文件中的全部或者特定符号,减小文件体积。