JUC集合类 SynchronousQueue源码解析 JDK8
文章目录
- 前言
- Transferer抽象类
- TransferStack
- 节点成员
- 节点类型
- TransferStack成员
- transfer方法
- awaitFulfill
- clean
- TransferQueue
- 节点成员
- 节点类型
- TransferQueue成员
- transfer方法
- awaitFulfill
- clean
- 无效操作
- 总结
前言
SynchronousQueue其实就是LinkedTransferQueue的升级版,相同的是它们都作为生产者和消费者交互的通道,可以直接让生产者和消费者打交道。不同的是,SynchronousQueue做的更彻底,不去支持无关的共有操作(比如size()),只提供必要的入队出队方法。并且,SynchronousQueue提供了两种逻辑结构,栈和队列。
理解LinkedTransferQueue是搞懂SynchronousQueue的前提。
JUC框架 系列文章目录
Transferer抽象类
abstract static class Transferer<E> {
abstract E transfer(E e, boolean timed, long nanos);
}
这里的transfer方法与LinkedTransferQueue的不同。按照LinkedTransferQueue的话,不管是data node还是request node,如果transfer成功返回的是创建节点时的item的相反值,如果transfer失败返回的是创建节点时的item的相同值(比如创建了data node的线程,data node的item初始是非null的,如果交易成功,则返回null;如果交易失败,则返回非null),相反相同指的是 null 或 非null。
但SynchronousQueue的transfer方法则不一样,不管是data node还是request node,如果transfer成功返回的是非null,如果transfer失败返回的是null。从子类实现中,我们可以看到这一点。
TransferStack
内部逻辑是栈的形式,让节点入队出队都从链表的同一端操作。
节点成员
static final class SNode {
volatile SNode next; // 单链表的next指针
volatile SNode match; // 如果交易成功,那么交易先到的node的match成员,会指向交易后到的node
volatile Thread waiter; // 阻塞前保存当前线程,用来被unpark
Object item; // data node为非null;request node为null
int mode; // 有四种情况,下面介绍
item不需要是volatile的,因为创建节点之后总是会有CAS操作。
节点类型
根据mode的值,有四种节点。
static final int REQUEST = 0;
static final int DATA = 1;
static final int FULFILLING = 2;
mode == REQUEST即0b00。交易先到的request node。mode == DATA即0b01。交易先到的data node。mode == FULFILLING | REQUEST即0b10。交易后到的request node。交易后到的都属于fulfilling node。mode == FULFILLING | DATA即0b11。交易后到的data node。交易后到的都属于fulfilling node。
我们称request node和data node是两个相反模式的节点。
TransferStack成员
volatile SNode head; // 因为是栈结构,所以只需要用一个指针来保存栈顶
没有找到构造器,所以是默认构造器。初始时head为null。
transfer方法
E transfer(E e, boolean timed, long nanos) {
SNode s = null; // constructed/reused as needed
int mode = (e == null) ? REQUEST : DATA;
for (;;) {
SNode h = head;
// 队列为空或队首模式相同(这说明队列中只有模式相同的节点)
// 注意,h.mode == mode已经排除掉了两种fulfilling node(data的、或request的)
if (h == null || h.mode == mode) {
//如果是计时操作,且传入时间参数<=0(一次尝试)
if (timed && nanos <= 0) { // 非计时操作或计时操作已经超时
if (h != null && h.isCancelled())
casHead(h, h.next); // 通过修改head出队取消节点
else
return null;
//1. 如果不是计时操作(同步操作)
//2. 如果是计时操作,且传入时间参数>0(同步带超时操作)
} else if (casHead(h, s = snode(s, e, h, mode))) {
SNode m = awaitFulfill(s, timed, nanos);//返回的是s的匹配对象
if (m == s) { // 如果匹配对象指向自身,说明当前线程被取消(中断或超时)
clean(s); // 尝试将s从栈中移除
return null;
}
// 如果匹配对象不是指向自身,说明当前线程等到了匹配对象的到来
if ((h = head) != null && h.next == s)
casHead(h, s.next); // 将匹配的一对节点出队
return (E) ((mode == REQUEST) ? m.item : s.item);
}
//队首为相反模式节点、或两种fulfilling node
//如果不是fulfilling node,那么队首为相反模式节点
} else if (!isFulfilling(h.mode)) { // 那么进行配对
if (h.isCancelled()) // 如果是取消节点
casHead(h, h.next); // 移除取消节点
else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) {//尝试入栈用来匹配的fulfill节点
for (;;) { // loop until matched or waiters disappear
SNode m = s.next;
if (m == null) { // 如果发现没有匹配对象
casHead(s, null); // 清空整个栈
s = null; // 清空s因为旧s的成员不对
break; // 下一次循环将作为普通节点再入队
}
SNode mn = m.next; //链表结构s -> m -> mn
if (m.tryMatch(s)) {//匹配成功
casHead(s, mn); // 将匹配的一对节点出队
return (E) ((mode == REQUEST) ? m.item : s.item);
} else // 如果m是个取消节点
s.casNext(m, mn); // 移除这个取消节点
}
}
//剩下的情况都是fulfilling node
} else { // 那么帮忙出队匹配的一对
SNode m = h.next;
if (m == null) // 如果发现没有匹配对象
casHead(h, null); // 清空整个栈
else {
SNode mn = m.next;
if (m.tryMatch(h)) // 进行匹配
casHead(h, mn); // 将匹配的一对节点出队
else // 如果m是个取消节点
h.casNext(m, mn); // 移除这个取消节点
}
}
}
}
之前讲过节点有4种mode,现在transfer方法就根据这4种mode分为了三种处理情况:
- 队列为空,或者队首是一个相同模式的节点(非fulfilling节点)。当前线程是交易先到的一方。接下来根据调用参数做不同处理:
timed == true && nanos <= 0。从字面意思就是这是个计时操作但却等0纳秒,其实就是只做一次尝试,如果只能找到相同模式节点的话,那么当前线程就不可能匹配成功,那就只能返回null代表失败了。timed == false。不是计时操作,那就是一个同步操作。这种情况,如果只能找到相同模式节点的话,那么让当前线程创建节点入队,阻塞等待匹配的对方到来。从awaitFulfill函数返回只能因为 匹配成功、被中断。timed == true && nanos > 0。从字面意思就是一个正常的计时操作。这种情况,如果只能找到相同模式节点的话,那么让当前线程创建节点入队,等待匹配的对方到来。从awaitFulfill函数返回只能因为 匹配成功、被中断、超时。
- 队首是一个相反模式的节点(非fulfilling节点)。当前线程是交易后到的一方。那么进行匹配,匹配如果成功,那么出队匹配的一对节点。
- 队首是一个fulfilling节点。那么帮忙出队匹配的一对节点。
这种加入fulfilling节点的手法类似于ConcurrentSkipListMap源码中的marker。在ConcurrentSkipListMap中,要删除链表中一个节点,不是直接将其移除,而是在被删除节点之前插入一个marker,当marker插入成功后,才将marker和被删除节点一起从链表中移除,这种做法保证了无锁实现能正确执行。而fulfilling节点的作用其实和marker是一样的。
整个执行过程能够保证链表中的非fulfilling节点肯定只有一种,要么是request node,要么是data node。
之前提到transfer方法的返回值是成功返回非null,失败返回null。但是不管当前线程在交易中先到还是后到,执行的总是return (E) ((mode == REQUEST) ? m.item : s.item),这里我解释一下为什么。

从上图可知,其实是因为不管哪种情况,s总是指向当前线程创建的节点,m总是指向匹配对方创建的节点,而这两个节点一个是request node一个是data node,既然是这样的话,根据s的模式就能知道这一对节点中哪个是data node,然后返回data node的item即可。所以永远执行return (E) ((mode == REQUEST) ? m.item : s.item)。
在交易成功后,双方线程在尝试出栈时其实是做的同一个操作,先到线程执行的casHead(h, s.next),和后到线程执行的casHead(s, mn),从上图也可知,这两个CAS操作的两个参数其实是一模一样的,所以这两个CAS操作只有一个能成功,另一个直接失败就好。这种类似的,互相帮忙式的操作很多,比如clean(s)和s.casNext(m, mn),都是在移除取消节点,前者被移除节点s就是当前线程创建的,后者被移除节点m不是当前线程创建的,而这后者就属于在帮忙。
另外,我们的移除操作是这样的。

static SNode snode(SNode s, Object e, SNode next, int mode) {
if (s == null) s = new SNode(e);
s.mode = mode;
s.next = next;
return s;
}
当前线程在创建节点时使用snode,这个函数可以使得创建出来的节点可以被重复利用。
awaitFulfill
此函数返回当前线程创建节点的匹配节点。不过也可能返回的是自身节点,如果当前线程被中断或超时。总之,此函数只会返回 非null值。
SNode awaitFulfill(SNode s, boolean timed, long nanos) {//s肯定是当前线程创建的节点
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
//计算出自旋次数
int spins = (shouldSpin(s) ?//当head还是s,或head是一个fulfiller节点时,shouldSpin返回true
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
if (w.isInterrupted())//如果被中断,则取消自身
s.tryCancel();
SNode m = s.match;
if (m != null)
return m; //有可能是正常被匹配到了,也有可能因为自身被取消。
if (timed) {// 如果是超时操作
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {//如果剩余时间没有了
s.tryCancel();//取消自身
continue;//下一次循环退出函数
}
}
if (spins > 0)//如果自旋次数还有,那么减一。如果发现没必要自旋了,那么归零
spins = shouldSpin(s) ? (spins-1) : 0;
else if (s.waiter == null)//自旋次数为0后,这次循环先放置当前线程
s.waiter = w;
//自旋次数为0,且当前线程已经放置好了
else if (!timed)//如果是非超时操作,无限阻塞
LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold)//如果是超时操作,执行超时版本阻塞
LockSupport.parkNanos(this, nanos);
//如果是超时操作,但时间太短,那么即使spins为0,也不停自旋直到时间消耗完
}
}
- 在有必要自旋时(
shouldSpin),先进行自旋,因为当前线程可能在自旋过程中就发现自己被匹配了。 - 自旋结束前,设置
Thread成员。 - 根据参数,调用不同版本的
park进行阻塞。 - 当从阻塞中唤醒时,检查被唤醒的原因。
- 如果是因为当前线程被中断,那么取消自身节点,返回自身。
- 如果是因为被正常匹配,那么返回匹配到的节点。
- 如果是因为超时,那么取消自身节点,返回自身。
自旋次数为0后,当前循环先放置当前线程作为s成员,下一次循环再检查一次if (m != null)看看是否被匹配了,尽可能避免不必要的阻塞,尽量在自旋过程中就发现自身节点被匹配到了。
boolean shouldSpin(SNode s) {
SNode h = head;
//中间的h == null只是严谨的防止空指针异常
return (h == s || h == null || isFulfilling(h.mode));
}
shouldSpin函数返回真说明当前线程有必要自旋。
- 第一种情况
h == s说明当前线程还在栈顶,那么继续自旋等待。 - 第二种情况h是个fulfill节点,这说明有可能是
s正在被匹配当前,那么也继续自旋等待。 - 第三章情况
h != s且不是fulfill节点,这说明没有必要等了,因为要匹配也是先匹配栈顶节点。
clean
此函数尝试从栈中移除掉s节点,就算s节点就是head,也会将其移除。
void clean(SNode s) {//s肯定是个取消节点
s.item = null; // forget item
s.waiter = null; // forget thread
SNode past = s.next;//找到一个s的后继
if (past != null && past.isCancelled())//如果后继是取消节点
past = past.next;//则获得后继的后继
// 从head开始清除取消节点,直到遇到非取消节点或者past
SNode p;
while ((p = head) != null && p != past && p.isCancelled())
casHead(p, p.next);
//结束循环时,p可能为:
//1. null
//2. past(这说明past之前都是取消节点)
//3. 第一个非取消节点
// 这个循环遇到past就停止,过程中一直在移除取消节点,当遇到past说明s已经被移除了
// 注意这个循环只能清除p以后的取消节点,p本身如果是取消节点则无能为力
while (p != null && p != past) {
SNode n = p.next;
if (n != null && n.isCancelled())
p.casNext(n, n.next);
else
p = n;
}
}
- 找到一个s的后继past。
- 找到一个遍历起点
p,这个p可能就是past,也可能是非past的一个非取消节点。 - 从遍历起点
p进行遍历直到遇到past,遍历过程一直在移除取消节点。原理就是,如果遍历已经遇到了past,那么作为取消节点的s就一定已经被移除掉了。
最坏情况下,s处于栈底,那么需要遍历整个链表。
之前提到,在并发情况下,有可能别的线程已经帮忙把s移除了,所以遍历过程中如果以s作为寻找标准,有可能永远也找不着。根据上图可知,如果在遍历过程中发现了s的后继,那么也说明了s被移除了。所以此函数使用了past这种东西。
TransferQueue
内部逻辑是队列的形式,让节点入队出队从链表的各自两端操作。
整体上和LinkedTransferQueue很像,交易后到的一方不会真正加入fulfill节点,而是直接修改交易先到的节点的item域。但本队列初始时有dummy node。
节点成员
static final class QNode {
volatile QNode next; // 单链表的next指针
volatile Object item; // 创建的是request node,为null;创建的是data node,为非null
volatile Thread waiter; // 阻塞前保存当前线程,用来被unpark
final boolean isData; // 两种模式,request node或data node
注意,不再需要match成员了,因为TransferQueue实际操作中并没有fulfill节点存在,而是直接修改匹配对方节点的item。
节点类型
节点只有两种:
- data node:
isData为true。 - request node:
isData为false。
称上面两种节点模式相反。
节点的item域各个时期不同:
data node:
- 刚创建时:
item域为非null。 - 被交易后到的一方匹配到:
item域为null。 - 自身取消:
item域指向自身。
request node:
- 刚创建时:
item域为null。 - 被交易后到的一方匹配到:
item域为非null。 - 自身取消:
item域指向自身。
TransferQueue成员
transient volatile QNode head;//队首
transient volatile QNode tail;//队尾
transient volatile QNode cleanMe;//clean方法中使用,用来保存 需要延后移除的节点的前驱
TransferQueue() {
QNode h = new QNode(null, false); // initialize to dummy node.
head = h;
tail = h;
}
构造器创建一个dummy node,虽然它和一个正常的request node一样,但执行过程通过head == tail来判断队列为空,所以不必担心。
队列为空时,head和tail指向同一个节点。真正的节点永远是head后继。
transfer方法
同样的,transfer方法在匹配成功时返回非null值,匹配失败时返回null值。
E transfer(E e, boolean timed, long nanos) {
QNode s = null; // constructed/reused as needed
boolean isData = (e != null);
for (;;) {
QNode t = tail;
QNode h = head;
if (t == null || h == null) // 如果看到了队列未初始化的值
continue; // 继续循环
if (h == t || t.isData == isData) { // 因为有dummy node,所以h == t代表队列空;队尾是相同模式
QNode tn = t.next;
if (t != tail) // 发现tail已经更新,那么继续循环
continue; // 这里如果不继续,接下来的t.casNext(null, s)也会失败的
if (tn != null) { // 虽然t为tail但它却有后继,说明遇到了别的线程添加节点后还没
advanceTail(t, tn); // 更新tail的中间状态。帮忙更新tail。
continue;
}
if (timed && nanos <= 0) // 如果是一次尝试版本,且发现队尾都是相同模式
return null; // 说明尝试失败,返回null
//其他情况就是,同步版本和超时版本
if (s == null) // 节点只创建一次
s = new QNode(e, isData);
if (!t.casNext(null, s)) // 入队失败,被别的线程抢先了
continue;
//入队成功
advanceTail(t, s); // 更新tail为最新入队节点
Object x = awaitFulfill(s, e, timed, nanos);
if (x == s) { // 当前线程的节点被取消而唤醒(中断或超时)
clean(t, s);
return null;
}
// 当前线程的节点是正常匹配而唤醒
if (!s.isOffList()) { // 如果s还没有自链接
advanceHead(t, s); // 使head从t变成s
if (x != null) // 如果awaitFulfill返回非null,说明匹配对方是生产者
s.item = s; // s节点为消费者,但s的item已变成非null,所以要释放掉这个引用
s.waiter = null; // 线程对象的引用一定要释放
}
return (x != null) ? (E)x : e;
// 队尾是相反模式
} else {
QNode m = h.next; // 如果队尾是相反模式,说明head后继也是相反模式
if (t != tail || m == null || h != head) // 队列结构已经和刚才看到的不一样了
continue;
Object x = m.item;
if (isData == (x != null) || // 参数isData与匹配对方节点的item域情况相同,说明对方已经被匹配
x == m || // item域指向自身,说明匹配对方节点被取消
!m.casItem(x, e)) { // 修改匹配对方节点的item域失败,说明对方已经 被匹配或取消
advanceHead(h, m); // 由于真正节点在head之后,所以head移动到m相当于出队m
continue; // 以上三种情况,m节点都不能被当前线程匹配了,需要继续循环
}
//执行到这里,说明上面的m.casItem(x, e)成功了,即配对成功
advanceHead(h, m); // 匹配成功后,也使得m出队
LockSupport.unpark(m.waiter); // 唤醒交易先到的一方
return (x != null) ? (E)x : e;
}
}
}
处理过程更加简单,因为交易后到的一方不需要添加fulfill节点,而是直接匹配:
- 队列为空,或者队尾是一个相同模式的节点(这说明队列中只有相同模式的节点)。那么当前线程是交易先到的一方。接下来根据调用参数做不同处理:
timed == true && nanos <= 0。做一次尝试,但既然现在队列中只有相同模式节点,那么尝试匹配失败,直接返回null。timed == false。不是计时操作,那就是一个同步操作。虽然现在队列中只有相同模式节点,那么让当前线程创建节点入队,阻塞等待匹配的对方到来。从awaitFulfill函数返回只能因为 匹配成功、被中断。timed == true && nanos > 0。计时操作。那么让当前线程创建节点入队,有时间限制得阻塞等待匹配的对方到来。从awaitFulfill函数返回只能因为 匹配成功、被中断、超时。
- 队尾是一个相反模式的节点(这说明head后继也是相反模式的节点)。当前线程是交易后到的一方。尝试修改交易先到一方的节点(head后继)的item域,如果修改成功,代表匹配成功,那么唤醒交易先到一方线程。注意,交易后到的一方并没有创建节点。
整个执行过程能够保证链表中,属于刚创建状态的node肯定都是相同模式的。
上面两种情况,都是执行return (x != null) ? (E)x : e,这能保证总是返回 匹配一对中的data node的初始item域。
- 上两种情况中,
x都代表交易对方的初始item。- 如果当前线程进入的
if (h == t || t.isData == isData)的else分支。x就是交易对方节点的初始item域。另外,它会将交易对方节点的item域,修改为自己节点的item(虽然它并没有真正创建节点)。 - 如果当前线程进入的
if (h == t || t.isData == isData)分支。当匹配成功后从awaitFulfill唤醒,返回x是对方节点的item(上一条解释了)。当自身取消后从awaitFulfill唤醒,返回x是自己节点的this。
- 如果当前线程进入的
- 而
e就是自身的item。就是当初创建节点用的item。 - 既然,
x代表交易对方的初始item,e就是自身的item。那么二者中肯定有一个是data node的初始item,那么返回其中的非null就好了。
互相帮忙式的CAS操作也有,这些操作只有一次会成功:
if (h == t || t.isData == isData)分支里的advanceTail(t, tn)和advanceTail(t, s),这两个CAS都是帮忙把刚入队队尾但还没来得及更新tail的节点更新为tail。advanceHead(t, s)和advanceHead(h, m)。前者是,发现自己被正常匹配,然后更新head。后者是,发现head后继被正常匹配或取消,然后更新head。
不管是正常匹配还是取消自身,都不应该让item域再持有引用,以免内存泄漏。
- 如果是自身节点取消,执行的是
tryCancel(在awaitFulfill中执行的),item域指向自身,不管哪种节点(request or data),都释放了引用。 - 如果是正常匹配,执行的是
if (x != null) s.item = s,前面讲过x代表交易对方的初始item,说明交易对方是生产者,自身节点s是消费者,但由于正常匹配,自身节点s的item域已经从null变成非null,所以也需要释放引用。相反情况则不用执行。
void advanceHead(QNode h, QNode nh) {
if (h == head &&
UNSAFE.compareAndSwapObject(this, headOffset, h, nh))
h.next = h; // forget old next
}
如果因为正常匹配而从队首出队时,过程是这样的:
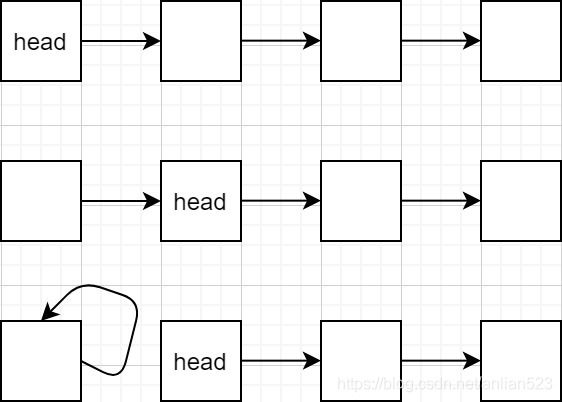
awaitFulfill
- 当因为正常匹配而返回时,此函数返回交易对方的初始item值(被唤醒之前,当前线程节点的item域就已经被修改为对方的item了)。
- 当因为自身取消时,此函数返回当前线程节点this。
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
/* 整体思想和TransferStack.awaitFulfill一样,只注释不一样的地方 */
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
int spins = ((head.next == s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
if (w.isInterrupted())
s.tryCancel(e);//尝试把item域从初始的e变成this
Object x = s.item;
if (x != e) //不管是因为取消,还是因为正常匹配,这个都成立
//如果是正常匹配,x肯定与e相反(这里指null 和 非null 相反)
return x;
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel(e);
continue;
}
}
if (spins > 0)//这里不用再检查head.next == s了,因为这是队列结构,后来的节点肯定在s的后面
--spins;
else if (s.waiter == null)
s.waiter = w;
else if (!timed)
LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
clean
此函数尝试从队列中移除s节点,但如果s是tail,此次调用函数不会执行移除动作,下次一定。
void clean(QNode pred, QNode s) {
s.waiter = null; // forget thread
while (pred.next == s) { // Return early if already unlinked
QNode h = head;
QNode hn = h.next; // 从head开始吸收后面的取消节点
if (hn != null && hn.isCancelled()) {
advanceHead(h, hn);
continue;
}
QNode t = tail; // 在使用前才读取tail,尽量保证读到最新
if (t == h) // 如果head == tail,那么队列为空
return;
QNode tn = t.next;
if (t != tail) // 发现tail已经更新
continue;
if (tn != null) { // tail没有更新,但tail有后继,这是个中间状态,帮忙更新tail
advanceTail(t, tn);
continue;
}
if (s != t) { // If not tail, try to unsplice
QNode sn = s.next;
// 如果s已经出队了(next指向自身)
// 如果将pred -> s -> sn结构修改为 pred -> sn
if (sn == s || pred.casNext(s, sn))
// 两种情况都说明s已经出队了
return;
}
//执行到这里,说明s就是tail,这次调用函数不能删除s节点了,下次一定
QNode dp = cleanMe;
if (dp != null) { // 发现cleanMe不为null,先移除cleanMe的后继
QNode d = dp.next; // d就是需要被移除的节点
QNode dn;
//结构为dp -> d -> dn
if (d == null || // d已经被移除
d == dp || // d已经被出队
!d.isCancelled() || // d应该是个取消节点的,但这里不是,说明已经被移除了
(d != t && // 接下来三行检查dp -> d -> dn的结构
(dn = d.next) != null &&
dn != d &&
dp.casNext(d, dn))) // 如果符合结构,那么尝试改成dp -> dn,即移除d节点
casCleanMe(dp, null); // 如果CAS成功,说明cleanMe后继移除成功
//一般情况下,下一次循环将执行casCleanMe(null, pred),保存好cleanMe后离开
if (dp == pred) // 上面过程只是帮上一次调用擦屁股,这一次因为不能删除s节点,
return; // 所以也需要保存好cleanMe再离开函数。如果发现dp就是pred,那说明cleanMe已经保存好了
} else if (casCleanMe(null, pred)) //如果cleanMe没被占领,占领它后直接return
return; // 之后再调这个函数会删除cleanMe的后继的
}
}
函数比较好理解,主要在于当发现s节点为tail时,此次调用不会移除掉它,而是留到下一次调用此函数再清理。因为下一次调用s就不再是队尾tail了。
- 当发现s是tail且cleanMe没被占领时,不执行移除动作,而是通过
casCleanMe(null, pred)把需要移除节点的前驱暂时保存起来。 - 当发现s是tail且cleanMe被占领时,先移除cleanMe的后继,然后再通过
casCleanMe(null, pred)把需要移除节点的前驱暂时保存起来。
之所以不移除tail的原因–concurrency-interest
这个原因concurrency-interest上面的大佬已经给予我解释了,比如说,如果当前链表为A -> B -> C(tail) -> null,而且C节点需要被移除,那么链表应该变成A -> B(tail) -> null。那么现在有几个问题:
- 直接变成
A -> B(tail) -> null,需要两个CAS操作,但这不可能是原子性的。 - 既然不可能是原子性,那么有的线程可能会看到
A -> B -> null和C(tail) -> null。而这又会带来两个问题:- 这破坏了只有一个节点的next为null的不变式。
- 别的线程可能会把新建节点加到C节点的后面。
总之,不移除tail可以避免很多问题,也可以说移除tail根本没法正确实现。
无效操作
SynchronousQueue完全没有容量的概念了,很多常用操作比如isEmpty()/size()/clear()/remove(Object)/contains(Object)/peek()都不支持了。可以用的公共方法只有:
- 入队:
put(E)/offer(E, long, TimeUnit)/offer(E) - 出队:
take()/poll(long, TimeUnit)/poll()
总结
- 同LinkedTransferQueue一样,队列中有两种节点data node和request node。
- 不同于LinkedTransferQueue,SynchronousQueue除了队列的逻辑结构,还提供了栈的逻辑结构。
- SynchronousQueue摒弃了与“线程交互通道”无关的操作。比如
size()总是返回0。 - 两种逻辑结构的
transfer方法,在返回值上:如果匹配成功,则返回非null值;如果匹配失败或自身取消,则返回null值。 - 栈结构的
TransferStack,fulfill节点会加入到链表中;队列结构的TransferQueue,fulfill节点不会加入链表中,而是直接修改交易先到节点的item,这和LinkedTransferQueue一样。