生成模型和生成对抗网络是何方神圣?计算机视觉的魔力
全文共4413字,预计学习时长13分钟

来源:Pexels
概述
· 生成模型和生成对抗网络(GANs)是计算机视觉应用最新进展的核心。本文将介绍GANs及其不同的组件。有一些激动人心的GANs用例,快来探索!
引言
你能辨别出下列图片中的奇怪之处吗?

这幅图片呢?

图中所有的实物和动物都由GANs这种计算机视觉模型生成!它是目前深度学习中最流行的一类,可以激发人类潜藏的创造力。
GANs无疑是笔者在深度学习中最喜欢的话题之一,这些模型创造出的各种程序我都喜欢,比如生成新的人脸图像或创造图画,还有修复旧画中遗失的部分!
这篇文章将介绍生成网络和GANs,了解其各种程序,并进一步探索工作机制(组件)。
目录
1. 什么是生成模型?
2. 生成模型的应用程序
3. 生成模型的种类
1.显性密度
2.隐性密度
4. 了解显性密度模型
5. GANs概况
6. 训练GANs步骤详解
1. 什么是生成模型?
在放眼看这些应用程序之前先来理解生成模型的理念,可以帮助可视化不同的用例,而且随后在探讨GANs时也会有所涉及。
运用机器学习或深度学习时通常会遇到两大问题——监督学习和无监督学习。
在监督学习中,会遇到自变量x和目标标签y。目标是学习映射x、y的映射函数。
![]()
监督学习的例子有分类、回归、目标检测、图像分割等。
无监督学习的问题是只有自变量x但无目标标签。目标是通过数据学习一些潜在的模式。无监督学习的例子有聚类、降维等。
所以,生成模型适合用于何处?
有了训练数据,生成模型会从训练集分布中生成新的样本。假如有一个拥有分布 pdata(x)的训练集,想生成一些样本,使样本pmodel(x)的分布与pdata(x)相似。简单点说:
使用生成模型,先学习训练集的分布,再利用所学的分布结合一些变量生成新的观察和数据点。
现在,有多种方法可以学习模型分布和数据真实分布之间的映射,在那之前,先给大家看几个超酷的生成式应用,也许会让你对生成模型产生兴趣。
2. 生成模型的应用
为什么首先需要生成模型?甚至笔者一开始就有这个疑问,但看的应用越多,就越相信生成模型的能力。
且让我解释一些用例回答这个问题。
生成数据
你曾经试过从零开始建立深度学习模型吗?大多数人最常遇到的一个难题就是缺少训练数据,即便数据再多。我肯定你不介意更多的数据!谁不爱呢?
某些产业需要更多的数据来训练更加深度的模型。医疗产业就是个合适的例子。生成模型在该领域可以发挥重要的作用,因为其可用于生成新数据。而生成的图像将有助于扩大数据集的规模。
生成模型可用于生成新面孔图像。本文阐述了真实面孔图像的生成。有很多类似的用例可使用生成模型来生成数据,例如卡通人物和名人图像等。
Image to Image Translation模型
笔者尤为喜欢这个生成模型。通过它可以实现一些有趣的操作,把卫星图像传递给谷歌地图,将白天的图片转为夜间模式,黑白照片变为彩色的,改变季节(如夏天到冬天)。


以上都是由该模型得出的。
Face Agingand De-Aging模型
该过程对人脸进行自然老化和去老化,绘制面部图像。
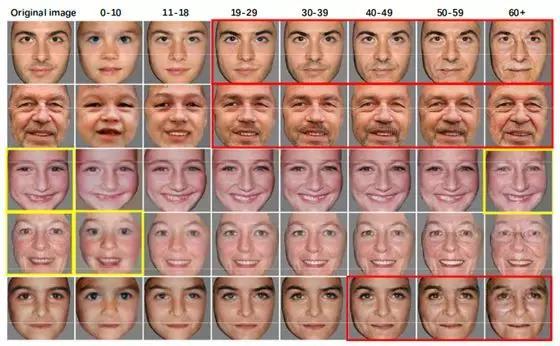
这可以用于识别各年龄段的面孔,也可用于娱乐。
还有更多生成模型比如3D目标检测、注意力预测、文本转图像等等。蠢蠢欲动吗?一起了解各种生成模型吧。
3. 生成模型的种类
有两种生成模型:
1. 显性密度模型
2. 隐性密度模型
了解二者不同之前先浏览下方的表格:
显性密度 隐性密度
假设数据存在一些先验分布 规定直接生成数据的随机程序
例子: 最大可能性 例子: 生成对抗网络(GANs)
显性密度模型定义了明确的密度函数pmodel(x;Ө),而隐性密度模型定义了直接生成数据的随机程序。
这里有一个可视图,Ian Goodfellow展示了不同的生成模型:
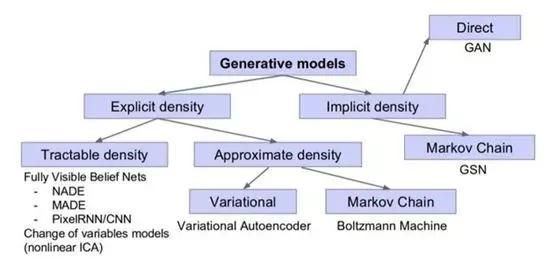
4.了解显性密度模型
我们知道显性目睹模型定义了明确的密度函数,会在训练数据上将最大化该函数的可能性。根据这些模型是否易于操作,可进一步分为子部分:
· 可牵引密度
· 近似密度
易操作意味着能够规定一个参数函数,可以有效捕捉分布。但多数分布,像图像分布或声波分布都很复杂也难于设计相应的参数函数。不具有捕捉分布的参数函数的模型要弱于近似密度模型。
为了定义密度函数,将图像x的可能性拆分为1-d分布,借助链式法则。

这里的p(x)代表图像x的可能性,右半部分代表第i个像素值的可能性。确定函数后,最大化训练数据的可能性。这便是易于操控的显性密度模型的工作原理。
Pixel RNN和Pixel CNN是最常见的易操作密度模型,下面会讲更多细节。
Pixel RNN
Pixel RNN是深度神经网络,会依序生成图像像素。从一角开始生成到生成两个连续的像素,举个例子来阐述。
如果要生成5×5的图像,将是如下图的25像素值:

模型会从一角开始生成像素:

然后,借助该像素值生成相邻的两个像素:

该过程一直持续到最后一个像素值的生成:
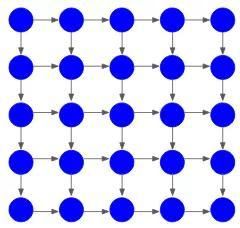
像素的生成依靠所有先前的像素值,通过RNN或LSTM将依赖性形成模式。
其缺点是因为生成是依序的,所以慢一些,这就是为什么要介绍 Pixel CNN。
Pixel CNN
Pixel CNN与Pixel RNN的理念相似,不用RNN对先前的像素建模,而是在上下文区域利用CNN。从一角开始,跟Pixel RNN的程序一样,再生成两个连续的像素。
要生成像素xi,模型只能利用之前的像素即x1、x2……xi-1,借助掩膜过滤确保这个发生:

已生成的像素值为1,剩下的分配为0,这将只考虑生成像素。PixelCNN的训练比Pixel RNN快,但像素仍是依序生成,所以过程不快。
总的来说,二者都能准确计算p(x)的可能性,从而给模型性能的测量提供适合的评估标准。上述的生成样本都是好的。另一方面,这些模型生成的过程与依序生成的一样慢。
截至目前,我们已经见到易操作的密度函数,可以在训练数据上直接优化这些函数的可能性。现在,再说一个生成模型——变分编码器(VariationalAutoencoders ,VA)
自编码器运行概况
快速理解它是什么,然后讨论其概念以及如何用其生成图像。
自编码器是一种学习低纬度呈现物的无监督方法。
由两个相连的神经网络组成——编码器和解码器。编码器中输入x得到特征图(z)。
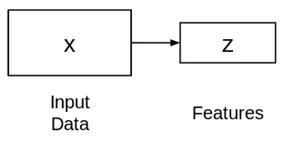
z比x的图小,你认为原因是什么?
因为只想让z获取变量的有价值因素,这些因素可以描述输入的数据,z的形状通常小于x。现在,问题是如何学习这个特征呈现z?如何训练该模型?出于此考虑,可以在提取的特征顶层添加一个解码器网络,使用L2loss训练模型。

这就是自编码器网络的构造,如此训练,z可用于重构原始输入数据x。如果输出X不同于输入x,L2 loss会处理问题帮助重构输入数据。
现在该如何通过这些自编码器生成新的图像呢?
变分编码器模型
这就是变分自动编码器的用处所在。人们假设训练数据是由一些潜在的未被观察到的呈现体z生成的。
简单的自编码器与变化的自编码之间的主要差异在于我们尝试建立训练数据的概率分布,而不是直接从输入数据中提取特征。
所以,我们没有让编码器输出1个n大小的编码向量,而是2个,一个是均值向量另一个是标准差向量。
整个网络构架就像这样:
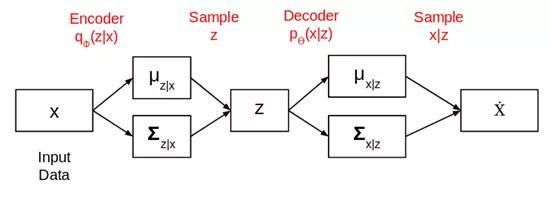
均值向量控制着输入数据的编码应处的中心位置,标准差向量控制均值编码的变化。遗失的可训练变分编码器的函数为Kullback-Leiblerdivergence(也称KLdivergence,相对熵),它测量概率分布的差异程度:
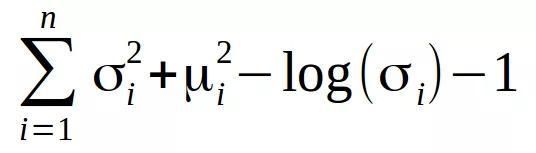
我们需要将相对熵最小化,这会优化概率分布的参数(均值和标准差)。一旦模型接受训练,就可以生成新的图像,给大家展示一下。
如何通过变分编码器生成图像?
模型训练完成后,移除编码器,得到下图的网络:
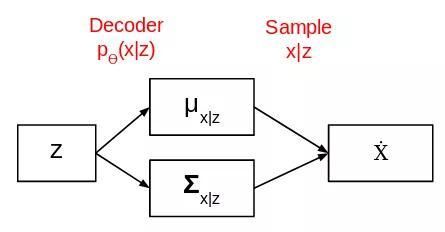
现在选一个均值为0标准差为1的概率分布,放入上图的网络,会得到输出。这就是变分编码器如何帮助生成图像的。
尽管这对于生成图像有所帮助,但其仍存在缺点。最主要的缺点是生成的样本图像相较于领先的GANs来说模糊,质量不高。这也是研究的一个方向,共同期望不久的进步!
截至目前,所有的生成模型都定义明确的密度函数。假如不想对密度精确建模只是为了获得从训练集中生成不明确样本的能力?就要用GANs了。它们拥有从训练集中获取不明确样本的函数。
5. GANs概况
容许我先阐述一下结构,这会让GANs理解起来更容易一些:
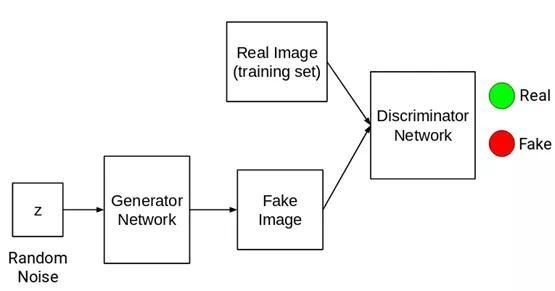
GANs由两个不同的网络组成:
1. 生成器网络(Generator Network)
2. 判别器网络(Discriminator Network)
笔者将一一阐述。
1. 生成器网络
该网络在有一些随机噪音后会生成图像。
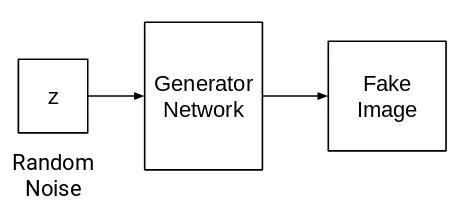
生成器网络指的是神经网络或者是卷积神经网络。输入一些随机噪音,该网络会借助声音生成图像。
2. 判别器网络
该网络的任务十分简单,需要判定输入的是否为真:

所有由训练集得到的图像都被标记为真的(1),所有源自生成器网络的图像被标记为假的(0)。现在,判别器网络的任务就是执行二进制分类。需要将输入的内容按照真或假(1或0)进行分类。
该模型的优点在于极易辨识。因为生成器网络与判别器网络皆为神经网络(或卷积神经网络),是一个完全不同的网络。
训练模型,在判别器网络末端计算遗失的函数,并反传递给判别器和生成器模型。
两种网络的参数都会更新,结果大大提升。在极大极小值计算中两个模型都会接受训练:
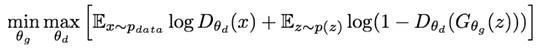
这里:
· P(data)代表来自训练集的数据分布
· D(x)代表x出自训练数据的可能性
· P(z)代表输入的声音变量
判别器网络(D)想要实现目标函数的最大化,这样D(x)就会接近1,D(z)接近0。就是说判别器应该将所有来自训练集的图像分为1(真实),将生成的图像分为0(虚假)。
生成器网络(G)想要实现目标函数的最小化,这样D(G(z))就为1。意味着生成器会试图生成类别为1(真实)的图像,真实类由判别器网络选出。
6.训练GANs步骤详解
训练过程如下:
1. 首先,从随机分布中取一声音样本,将其输入生成器网络(G),生成一些图像(虚假,标签为0):
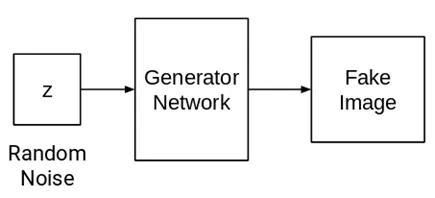
2. 接着从生成器网络生成的图像中提取虚假图像(0)以及从训练集中提取真实图像(1),将成对的图像放入判别器网络中(D)中,进行分类:
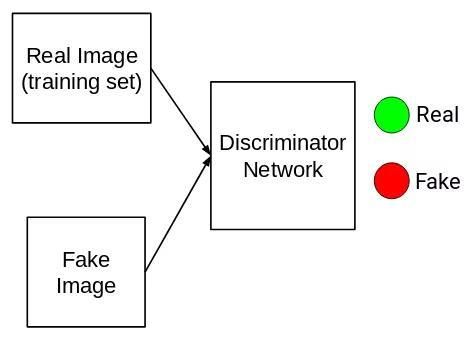
3. 正如所观察的,所以判别器是二元分类器,用来计算损失(可以为二元交叉熵)。
4. 然后将损失反向传递给判别器网络和生成器网络,更新权重。该过程可利用Adam或其他任何优化器。
这就是GAN的训练过程。希望能对大家有帮助。

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)