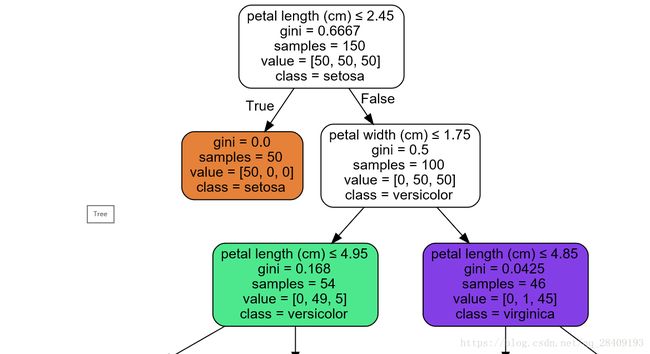
- 【Python-ML】SKlearn库性能指标ROC-AUC
fjssharpsword
Bigdatapython专栏
#-*-coding:utf-8-*-'''Createdon2018年1月19日@author:Jason.F@summary:ROC(receiveroperatorcharacteristic,基于模型真正率和假正率等性能指标评估分类模型'''importpandasaspdfromsklearn.preprocessingimportLabelEncoderfromsklearn.cros
- 【python 机器学习】sklearn ROC曲线与AUC指标
人才程序员
杂谈机器学习pythonsklearn人工智能深度学习神经网络目标检测
文章目录sklearnROC曲线与AUC指标1.什么是ROC曲线与AUC?通俗介绍:学术解释:2.在`sklearn`中绘制ROC曲线与计算AUC2.1导入库和数据2.2加载数据集2.3训练模型2.4预测概率2.5计算FPR、TPR和AUC2.6绘制ROC曲线3.解析ROC曲线和AUC值4.总结sklearnROC曲线与AUC指标在机器学习中,评估分类模型的性能不仅仅依赖于准确率,还需要使用一些更
- AI探索笔记:线性回归
安意诚Matrix
机器学习笔记人工智能笔记线性回归
前言写这篇博客,主要是自己来练练手。网络上教程已经是数不胜数,也都讲得非常清楚了。但自己不动手,知识和能力还是别人的。下面分别用传统方法(sklearn)和神经网络(pytorch)来解决线性回归问题。内容什么是线性回归线性回归(LinearRegression)是统计学和机器学习中最基础且广泛使用的预测模型,用于建立**自变量(输入特征)与因变量(输出目标)**之间的线性关系模型。其核心思想是通
- AI人工智能机器学习之聚类分析
rockfeng0
人工智能机器学习sklearn
1、概要 本篇学习AI人工智能机器学习之聚类分析,以KMeans、AgglomerativeClustering、DBSCAN为例,从代码层面讲述机器学习中的聚类分析。2、聚类分析-简介聚类分析是一种无监督学习的方法,用于将数据集中的样本划分为不同的组(簇),使得同一组中的样本相似度较高,而不同组之间的样本相似度较低。sklearn.cluster提供了多种聚类算法K均值聚类(K-MeansCl
- 基于KNN的鸢尾花分类预测模型
溪海莘
分类数据挖掘人工智能
基于KNN的鸢尾花分类预测模型.让机器实现对鸢尾花的分类分析,它会怎么做呢?我们首先列举出可能需要的要素:数据,模型和算法,效果评估。机器学习,它也是需要对自己的学习效果进行评估,因为它需要根据结果来调整参数。大多数情况需要人来介入这个过程,人们需要根据自身的经验来选取一些合适的参数,但是“爱偷懒”的数据科学家同时也提出一些自动化的程序来实现这一步骤。一、鸢尾花数据集1.1利用sklearn库导入
- (一)基于车险案例的多模型预测评估、箱线图绘制
renshixinghuo
python机器学习开发语言
一、案例引入(一)问题提出回访问卷是一种常用的、用于评估客户质量的手段,基于回访问卷所得数据,我们一定程度上能够推断具有什么样特征的用户可能更具有产品依赖性。因此,基于某车险回访问卷,我们利用sklearn库中各类模型对其进行预测,并展示此案例中各模型预测的表现情况。(二)原始数据原始数据包含用户ID、性别、年龄、所在地区代码、年保费、沟通渠道、是否有驾照、是否购买过车辆、车龄、是否发生过车祸、是
- 使用Scikit-Learn决策树:分类问题解决方案指南
范范0825
scikit-learn决策树分类
如何用scikit-learn的决策树分类器解决分类问题1.引言在本教程中,我们将探讨如何使用scikit-learn(sklearn)库中的决策树分类器解决分类问题。决策树是一种强大的机器学习算法,能够根据输入数据的特征属性学习决策规则,并用于预测新数据的分类标签。2.理论基础与算法介绍2.1决策树算法概述决策树是一种树形结构,每个非叶节点表示一个特征属性上的决策,每个分支代表一个决策结果的可能
- 朴素贝叶斯原理及sklearn中代码实战
Lewis@
sklearn概率论机器学习
朴素贝叶斯(NaiveBayes)是一类基于贝叶斯定理的简单而有效的分类算法。它假设特征之间是相互独立的,即在给定目标变量的情况下,每个特征都不依赖于其他特征。尽管这个假设在实际中很难成立,朴素贝叶斯在许多场景下仍表现得非常好,特别是对于文本分类等高维数据的应用。1.贝叶斯定理贝叶斯定理表明给定一个事件发生的条件下另一个事件发生的概率:P(A∣B)=P(B∣A)⋅P(A)P(B){P(A|B)=\
- sklearn TfidfVectorizer使用教程
Cachel wood
python机器学习和数据挖掘sklearnpython机器学习开发语言django人工智能数据挖掘
文章目录TfidfVectorizer代码解释:TfidfVectorizer得到较长的“词汇”代码解释TfidfVectorizerTfidfVectorizer是scikit-learn库中用于将文本数据转换为TF-IDF(词频-逆文档频率)特征矩阵的强大工具。下面为你提供一个详细的使用教程,涵盖基本使用、参数设置、中文处理等方面。安装依赖库确保你已经安装了scikit-learn和panda
- sklearn.ConfusionMatrixDisplay可视化混淆矩阵
Cachel wood
python机器学习和数据挖掘sklearn矩阵人工智能python机器学习vue.jsjava
文章目录ConfusionMatrixDisplay详细解释更多定制化ConfusionMatrixDisplayConfusionMatrixDisplay是scikit-learn库中用于可视化混淆矩阵的一个实用工具。混淆矩阵是一种常用的评估分类模型性能的工具,它可以直观地展示模型在各个类别上的预测结果与真实标签之间的关系。下面详细介绍如何使用ConfusionMatrixDisplay进行混
- 吴恩达-机器学习-多元线性回归模型代码
StrawBerryTreea
机器学习机器学习线性回归python吴恩达
吴恩达《机器学习》2022版第一节第二周多元线性回归房价预测简单实现以下以下共两个实验,都是通过调用sklearn函数,分别实现了一元线性回归和多元线性回归的房价预测。一、一元线性回归importnumpyasnpnp.set_printoptions(precision=2)fromsklearn.linear_modelimportLinearRegression#输入数据X_train=np
- 【机器学习】多元线性回归
T0uken
Python全栈开发1024程序员节机器学习算法线性回归
在实际应用中,许多问题都包含多个特征(输入变量),而不仅仅是单个输入变量。多元线性回归是线性回归的扩展,它能够处理多个输入特征并建立它们与目标变量的线性关系。本教程将系统性推演多元线性回归,包括向量化处理、特征放缩、梯度下降的收敛性和学习率选择等,并使用numpy实现。最后,我们会通过sklearn快速实现多元线性回归模型。多元线性回归模型简介多元线性回归的模型公式为:y=X⋅w+by=X\cdo
- Python:第三方库
衍生星球
python第三方库
1.第三方Python库库名用途pip安装指令NumPy矩阵运算pipinstallnumpyMatplotlib产品级2D图形绘制pipinstallmatplotlibPIL图像处理pipinstallpillowsklearn机器学习和数据挖掘pipinstallsklearnRequestsHTTP协议访问pipinstallrequestsJieba中文分词pipinstalljieba
- 字节跳动实习生和校招生内推
飞300
pythonjavascriptphp业界资讯算法
机器学习算法实习生-平台治理1、2026届硕士及以上学位在读,计算机等相关专业优先;2、有扎实的代码能力,熟悉深度学习/图神经网络/机器学习框架,如Pytorch、Tensorflow、DGL、Pyg、Sklearn等;3、熟悉机器学习/图学习/序列学习算法中的一项或者多项,如图建模、时序信号建模、节点/子图分类、社区挖掘、表征学习、自监督/半监督学习等,有一定深度和广度;4、熟悉相关算法在数据挖
- 第三章 回归训练实战(以预测新冠感染人数为例)
不吃香菜(扣1复活版)
深度学习入门笔记深度学习人工智能
完整项目代码(预测第三天的新冠感染人数)fromsklearn.feature_selectionimportSelectKBestfromsklearn.feature_selectionimportchi2importcsv#读CSVimportnumpyasnpimporttimeimportmatplotlib.pyplotaspltimportpandasaspdfromtorchimp
- Python中的决策树算法探索
Soft_Leader
算法python决策树
在Python中,决策树算法是一种常用的机器学习技术,用于分类和回归问题。下面我们将探索如何使用Python中的scikit-learn库来实现决策树算法,并简要介绍其基本概念和用法。1.安装必要的库如果你还没有安装scikit-learn库,你可以使用pip来安装它:bash复制代码pipinstall-Uscikit-learn2.导入必要的库和模块python复制代码fromsklearn.
- sklearn_pandas.DataFrameMapper的用法
zoujiahui_2018
#Pytorchsklearnpandas人工智能
文章目录介绍主要作用基本用法示例对不同列应用不同的转换器对多列应用相同的转换器输出为PandasDataFrame注意事项转换器的适用性:输出格式:与scikit-learn的兼容性:介绍DataFrameMapper是sklearn-pandas库中的一个工具,主要用于将PandasDataFrame与scikit-learn的预处理工具无缝结合。它的作用是将DataFrame的列映射到特定的特
- 【python 机器学习】sklearn转换器与预估器
人才程序员
杂谈python机器学习sklearn人工智能目标检测深度学习神经网络
文章目录sklearn转换器与预估器1.什么是转换器(Transformer)?通俗介绍:学术解释:2.什么是预估器(Estimator)?通俗介绍:学术解释:3.转换器与预估器的共同点4.转换器与预估器的区别5.使用`sklearn`中的转换器与预估器5.1示例:数据标准化(转换器)5.2示例:模型训练与预测(预估器)6.使用`Pipeline`结合转换器与预估器7.总结sklearn转换器与预
- 自主学习ai 版本0.01
pps-key
人工智能AI写作python算法大数据机器学习
以下是一个简单的自主学习AI示例代码框架,使用Python和在线学习机制实现。这个示例包含基础的数据处理、模型更新和知识存储功能:pythonimportnumpyasnpfromsklearn.linear_modelimportSGDClassifierfromsklearn.feature_extraction.textimportTfidfVectorizerimportpickleimp
- Python与R机器学习(1)支持向量机
宠物与不尤编程
左手python右手R支持向量机机器学习pythonr语言
以下是对Python与R在支持向量机(SVM)实现上的核心区别分析及完整示例代码:一、核心差异对比特征Python(scikit-learn)R(e1071/kernlab)核心库sklearn.svm.SVC/SVRe1071::svm()或kernlab::ksvm()语法范式面向对象(先初始化模型后拟合)函数式+公式接口(y~x1+x2)核函数支持linear,poly,rbf,sigmoi
- 牛掰的算法系列:K折交叉验证(KFold)常见使用方法
羽蒙等风来
机器学习算法机器学习python
讲解了交叉验证的基本思想之后,接下来将学习几个常用的交叉迭代器及其使用方法。1.K折交叉验证K折交叉验证(KFold)会将数据集划分为k个分组,成为折叠(fold)。如果k的值等于数据集实例的个数,那么每次的测试集就只有一个,这种处理方式称为“留一”。Scikit中提供了KFold方法进行分组。#导入相关模块In[1]:fromsklearn.model_selectionimportKFold#
- KMeans聚类实战2
浊酒南街
#kmeans聚类python
目录NBA球员聚类--未知k值的情况NBA球员聚类–未知k值的情况#导入第三方模块importpandasaspdimportnumpyasnpimportmatplotlib.pyplotaspltfromsklearn.clusterimportKMeansfromsklearnimportmetricsimportseabornassnsfromsklearnimportpreprocess
- KMeans聚类实战1
浊酒南街
#kmeans聚类算法
目录iris聚类--已知k值的情况iris聚类–已知k值的情况#导入第三方模块importpandasaspdimportnumpyasnpimportmatplotlib.pyplotaspltfromsklearn.clusterimportKMeansfromsklearnimportmetricsimportseabornassns#读取iris数据集iris=pd.read_csv(r'
- 3D数据可视化与SVM分类
t0_54coder
编程问题解决手册3d信息可视化支持向量机个人开发
在数据科学和机器学习中,数据可视化是理解数据分布和模型表现的关键环节。本文将通过一个实例展示如何使用Python的Matplotlib库来绘制3D数据点和SVM分类面的可视化,解决我在编程中遇到的问题。问题背景最近,我在完成一项作业时尝试重现一个3D数据的SVM分类图,但结果只得到了一个空白窗口,这让我很困惑。以下是原始代码:importnumpyasnpfromsklearn.datasetsi
- KNN算法:从思想到实现(附代码)
lihuayong
人工智能机器学习算法KNN算法分类问题回归问题
引言K最近邻算法(KNearestNeighbors,KNN)是一种简单而有效的机器学习算法,用于分类和回归问题。其核心思想基于“近朱者赤,近墨者黑”,即通过测量不同特征值之间的距离来进行分类或预测数值。本文将详细介绍KNN的核心概念、使用方法及其在sklearn中的实现,并展示如何自己动手编写一个简单的KNN算法。新样本寻找K个最近邻分类问题:多数表决回归问题:均值计算KNN核心思想如何做一个样
- TfidfVectorizer 和 word2vec
SpiritYzw
sklearnpython机器学习
一、TfidfVectorizer简单使用例子,可以统计子变量的频次类特征fromsklearn.feature_extraction.textimportTfidfVectorizertext_list=['aaa,bbb,ccc,aaa','bbb,aaa,aaa,ccc']vectorizer=TfidfVectorizer(stop_words=[',',':','','.','-'],m
- Python模型上线pmml以及自定义函数转换(1)
jin_tmac
机器学习与数据挖掘pythonpythonsklearn
通常xgb或lgb模型通过pmml上线都比较简单,但是逻辑回归模型因为涉及到woe的转换,就要通过自定义转换函数的方式来实现。1、常规转换-模型训练好之后立即转换importjoblibfromsklearn2pmmlimportPMMLPipeline,sklearn2pmml#保存模型python可读入defdump(clf,fp='clf'):joblib.dump(feature_name
- java调用ONNX模型
jason.zeng@1502207
java开发语言
一、导出一个onnx模型这里训练了一个简单的线性回归模型通过SerializeToString完成导出。fromsklearn.linear_modelimportLinearRegressionimportnumpyasnpimportonnxfromskl2onnximportconvert_sklearnfromskl2onnx.common.data_typesimportFloatTen
- Python-机器学习(二)-K近邻算法的原理与鸢尾花数据集实现详解
2401_84009679
程序员机器学习python近邻算法
fromsklearn.neighborsimportKNeighborsClassifierk=5#对模型训练clf=KNeighborsClassifier(n_neighbors=k)clf.fit(x,y)#对样本进行预测x_sample=[[0,2]]neighbors=clf.kneighbors(x_sample)neighbors[1]plt.figure(figsize=(16,
- 自定义数据集 使用scikit-learn中svm的包实现svm分类
灵封~
机器学习人工智能
引入必要的库importnumpyasnpfromsklearn.datasetsimportmake_classificationfromsklearn.model_selectionimporttrain_test_splitfromsklearn.svmimportSVCfromsklearn.metricsimportaccuracy_score,classification_report
- github中多个平台共存
jackyrong
github
在个人电脑上,如何分别链接比如oschina,github等库呢,一般教程之列的,默认
ssh链接一个托管的而已,下面讲解如何放两个文件
1) 设置用户名和邮件地址
$ git config --global user.name "xx"
$ git config --global user.email "
[email protected]"
- ip地址与整数的相互转换(javascript)
alxw4616
JavaScript
//IP转成整型
function ip2int(ip){
var num = 0;
ip = ip.split(".");
num = Number(ip[0]) * 256 * 256 * 256 + Number(ip[1]) * 256 * 256 + Number(ip[2]) * 256 + Number(ip[3]);
n
- 读书笔记-jquey+数据库+css
chengxuyuancsdn
htmljqueryoracle
1、grouping ,group by rollup, GROUP BY GROUPING SETS区别
2、$("#totalTable tbody>tr td:nth-child(" + i + ")").css({"width":tdWidth, "margin":"0px", &q
- javaSE javaEE javaME == API下载
Array_06
java
oracle下载各种API文档:
http://www.oracle.com/technetwork/java/embedded/javame/embed-me/documentation/javame-embedded-apis-2181154.html
JavaSE文档:
http://docs.oracle.com/javase/8/docs/api/
JavaEE文档:
ht
- shiro入门学习
cugfy
javaWeb框架
声明本文只适合初学者,本人也是刚接触而已,经过一段时间的研究小有收获,特来分享下希望和大家互相交流学习。
首先配置我们的web.xml代码如下,固定格式,记死就成
<filter>
<filter-name>shiroFilter</filter-name>
&nbs
- Array添加删除方法
357029540
js
刚才做项目前台删除数组的固定下标值时,删除得不是很完整,所以在网上查了下,发现一个不错的方法,也提供给需要的同学。
//给数组添加删除
Array.prototype.del = function(n){
- navigation bar 更改颜色
张亚雄
IO
今天郁闷了一下午,就因为objective-c默认语言是英文,我写的中文全是一些乱七八糟的样子,到不是乱码,但是,前两个自字是粗体,后两个字正常体,这可郁闷死我了,问了问大牛,人家告诉我说更改一下字体就好啦,比如改成黑体,哇塞,茅塞顿开。
翻书看,发现,书上有介绍怎么更改表格中文字字体的,代码如下
- unicode转换成中文
adminjun
unicode编码转换
在Java程序中总会出现\u6b22\u8fce\u63d0\u4ea4\u5fae\u535a\u641c\u7d22\u4f7f\u7528\u53cd\u9988\uff0c\u8bf7\u76f4\u63a5这个的字符,这是unicode编码,使用时有时候不会自动转换成中文就需要自己转换了使用下面的方法转换一下即可。
/**
* unicode 转换成 中文
- 一站式 Java Web 框架 firefly
aijuans
Java Web
Firefly是一个高性能一站式Web框架。 涵盖了web开发的主要技术栈。 包含Template engine、IOC、MVC framework、HTTP Server、Common tools、Log、Json parser等模块。
firefly-2.0_07修复了模版压缩对javascript单行注释的影响,并新增了自定义错误页面功能。
更新日志:
增加自定义系统错误页面功能
- 设计模式——单例模式
ayaoxinchao
设计模式
定义
Java中单例模式定义:“一个类有且仅有一个实例,并且自行实例化向整个系统提供。”
分析
从定义中可以看出单例的要点有三个:一是某个类只能有一个实例;二是必须自行创建这个实例;三是必须自行向系统提供这个实例。
&nb
- Javascript 多浏览器兼容性问题及解决方案
BigBird2012
JavaScript
不论是网站应用还是学习js,大家很注重ie与firefox等浏览器的兼容性问题,毕竟这两中浏览器是占了绝大多数。
一、document.formName.item(”itemName”) 问题
问题说明:IE下,可以使用 document.formName.item(”itemName”) 或 document.formName.elements ["elementName&quo
- JUnit-4.11使用报java.lang.NoClassDefFoundError: org/hamcrest/SelfDescribing错误
bijian1013
junit4.11单元测试
下载了最新的JUnit版本,是4.11,结果尝试使用发现总是报java.lang.NoClassDefFoundError: org/hamcrest/SelfDescribing这样的错误,上网查了一下,一般的解决方案是,换一个低一点的版本就好了。还有人说,是缺少hamcrest的包。去官网看了一下,如下发现:
- [Zookeeper学习笔记之二]Zookeeper部署脚本
bit1129
zookeeper
Zookeeper伪分布式安装脚本(此脚本在一台机器上创建Zookeeper三个进程,即创建具有三个节点的Zookeeper集群。这个脚本和zookeeper的tar包放在同一个目录下,脚本中指定的名字是zookeeper的3.4.6版本,需要根据实际情况修改):
#!/bin/bash
#!!!Change the name!!!
#The zookeepe
- 【Spark八十】Spark RDD API二
bit1129
spark
coGroup
package spark.examples.rddapi
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.SparkContext._
object CoGroupTest_05 {
def main(args: Array[String]) {
v
- Linux中编译apache服务器modules文件夹缺少模块(.so)的问题
ronin47
modules
在modules目录中只有httpd.exp,那些so文件呢?
我尝试在fedora core 3中安装apache 2. 当我解压了apache 2.0.54后使用configure工具并且加入了 --enable-so 或者 --enable-modules=so (两个我都试过了)
去make并且make install了。我希望在/apache2/modules/目录里有各种模块,
- Java基础-克隆
BrokenDreams
java基础
Java中怎么拷贝一个对象呢?可以通过调用这个对象类型的构造器构造一个新对象,然后将要拷贝对象的属性设置到新对象里面。Java中也有另一种不通过构造器来拷贝对象的方式,这种方式称为
克隆。
Java提供了java.lang.
- 读《研磨设计模式》-代码笔记-适配器模式-Adapter
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
package design.pattern;
/*
* 适配器模式解决的主要问题是,现有的方法接口与客户要求的方法接口不一致
* 可以这样想,我们要写这样一个类(Adapter):
* 1.这个类要符合客户的要求 ---> 那显然要
- HDR图像PS教程集锦&心得
cherishLC
PS
HDR是指高动态范围的图像,主要原理为提高图像的局部对比度。
软件有photomatix和nik hdr efex。
一、教程
叶明在知乎上的回答:
http://www.zhihu.com/question/27418267/answer/37317792
大意是修完后直方图最好是等值直方图,方法是HDR软件调一遍,再结合不透明度和蒙版细调。
二、心得
1、去除阴影部分的
- maven-3.3.3 mvn archetype 列表
crabdave
ArcheType
maven-3.3.3 mvn archetype 列表
可以参考最新的:http://repo1.maven.org/maven2/archetype-catalog.xml
[INFO] Scanning for projects...
[INFO]
- linux shell 中文件编码查看及转换方法
daizj
shell中文乱码vim文件编码
一、查看文件编码。
在打开文件的时候输入:set fileencoding
即可显示文件编码格式。
二、文件编码转换
1、在Vim中直接进行转换文件编码,比如将一个文件转换成utf-8格式
&
- MySQL--binlog日志恢复数据
dcj3sjt126com
binlog
恢复数据的重要命令如下 mysql> flush logs; 默认的日志是mysql-bin.000001,现在刷新了重新开启一个就多了一个mysql-bin.000002
- 数据库中数据表数据迁移方法
dcj3sjt126com
sql
刚开始想想好像挺麻烦的,后来找到一种方法了,就SQL中的 INSERT 语句,不过内容是现从另外的表中查出来的,其实就是 MySQL中INSERT INTO SELECT的使用
下面看看如何使用
语法:MySQL中INSERT INTO SELECT的使用
1. 语法介绍
有三张表a、b、c,现在需要从表b
- Java反转字符串
dyy_gusi
java反转字符串
前几天看见一篇文章,说使用Java能用几种方式反转一个字符串。首先要明白什么叫反转字符串,就是将一个字符串到过来啦,比如"倒过来念的是小狗"反转过来就是”狗小是的念来过倒“。接下来就把自己能想到的所有方式记录下来了。
1、第一个念头就是直接使用String类的反转方法,对不起,这样是不行的,因为Stri
- UI设计中我们为什么需要设计动效
gcq511120594
UIlinux
随着国际大品牌苹果和谷歌的引领,最近越来越多的国内公司开始关注动效设计了,越来越多的团队已经意识到动效在产品用户体验中的重要性了,更多的UI设计师们也开始投身动效设计领域。
但是说到底,我们到底为什么需要动效设计?或者说我们到底需要什么样的动效?做动效设计也有段时间了,于是尝试用一些案例,从产品本身出发来说说我所思考的动效设计。
一、加强体验舒适度
嗯,就是让用户更加爽更加爽的用
- JBOSS服务部署端口冲突问题
HogwartsRow
java应用服务器jbossserverEJB3
服务端口冲突问题的解决方法,一般修改如下三个文件中的部分端口就可以了。
1、jboss5/server/default/conf/bindingservice.beans/META-INF/bindings-jboss-beans.xml
2、./server/default/deploy/jbossweb.sar/server.xml
3、.
- 第三章 Redis/SSDB+Twemproxy安装与使用
jinnianshilongnian
ssdbreidstwemproxy
目前对于互联网公司不使用Redis的很少,Redis不仅仅可以作为key-value缓存,而且提供了丰富的数据结果如set、list、map等,可以实现很多复杂的功能;但是Redis本身主要用作内存缓存,不适合做持久化存储,因此目前有如SSDB、ARDB等,还有如京东的JIMDB,它们都支持Redis协议,可以支持Redis客户端直接访问;而这些持久化存储大多数使用了如LevelDB、RocksD
- ZooKeeper原理及使用
liyonghui160com
ZooKeeper是Hadoop Ecosystem中非常重要的组件,它的主要功能是为分布式系统提供一致性协调(Coordination)服务,与之对应的Google的类似服务叫Chubby。今天这篇文章分为三个部分来介绍ZooKeeper,第一部分介绍ZooKeeper的基本原理,第二部分介绍ZooKeeper
- 程序员解决问题的60个策略
pda158
框架工作单元测试
根本的指导方针
1. 首先写代码的时候最好不要有缺陷。最好的修复方法就是让 bug 胎死腹中。
良好的单元测试
强制数据库约束
使用输入验证框架
避免未实现的“else”条件
在应用到主程序之前知道如何在孤立的情况下使用
日志
2. print 语句。往往额外输出个一两行将有助于隔离问题。
3. 切换至详细的日志记录。详细的日
- Create the Google Play Account
sillycat
Google
Create the Google Play Account
Having a Google account, pay 25$, then you get your google developer account.
References:
http://developer.android.com/distribute/googleplay/start.html
https://p
- JSP三大指令
vikingwei
jsp
JSP三大指令
一个jsp页面中,可以有0~N个指令的定义!
1. page --> 最复杂:<%@page language="java" info="xxx"...%>
* pageEncoding和contentType:
> pageEncoding:它