ZooKeeper 基本介绍
Zookeeper 作为一个分布式的服务框架,主要用来解决分布式集群中应用系统的一致性问题,它能提供基于类似于文件系统的目录节点树方式的数据存储, Zookeeper 作用主要是用来维护和监控存储的数据的状态变化,通过监控这些数据状态的变化,从而达到基于数据的集群管理。
1 Zookeeper基本框架
Zookeeper集群主要角色有Leader,Learner(Follower,Observer(当服务器增加到一定程度,由于投票的压力增大从而使得吞吐量降低,所以增加了Observer。)以及client:
Leader:领导者,负责投票的发起和决议,以及更新系统状态
Follower:接受客户端的请求并返回结果给客户端,并参与投票
Observer:接受客户端的请求,将写的请求转发给leader,不参与投票。Observer目的是扩展系统,提高读的速度。
Client:客户端,想Zookeeper发起请求。
Zookeeper的基本框架图如下

Leader主要功能:
恢复数据;
维持与Learner的心跳,接收Learner请求并判断Learner的请求消息类型;Learner的消息类型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根据不同的消息类型,进行不同的处理。PING消息是指Learner的心跳信息;REQUEST消息是Follower发送的提议信息,包括写请求及同步请求;ACK消息是Follower的对提议的回复,超过半数的Follower通过,则commit该提议;REVALIDATE消息是用来延长SESSION有效时间。

Follower基本功能:
向Leader发送请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
接收Leader消息并进行处理;
接收Client的请求,如果为写请求,发送给Leader进行投票;
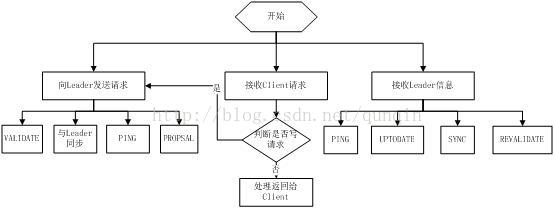
Observer主要功能同Follower的唯一不同的地方就是observer不会参加leader发起的投票。
Zookeeper配置介绍:

tickTime :基本事件单元,以毫秒为单位。这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
dataDir :存储内存中数据库快照的位置,顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
clientPort :这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
initLimit:这个配置项是用来配置 Zookeeper 接受客户端初始化连接时最长能忍受多少个心跳时间间隔数,当已经超过 5 个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒。
syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2*2000=4 秒
server.A = B:C:D : A表示这个是第几号服务器,B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader。
Zookeeper集群下的基本操作:
查看各Zookeeper服务角色:

基本命令操作:
./zookeeper/server004/zookeeper/bin/zkCli.sh
2 Zookeeper基本介绍
Zookeeper 的数据结构是一个树形结构 ,非常类似于一个标准的文件系统。每个子节点项都有唯一的路径标识,如 Server1 节点的标识为 /NameService/Server1。

1). Znode
Zookeeper数据结构中每个节点称为Znode,每个Znode都有唯一的路径,znode 可以有子节点目录,并且每个 znode 可以存储数据。znode是有版本的,每个 znode 中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据。
Znode 基本类型 :
PERSISTENT:持久化znode节点,一旦创建这个znode点存储的数据不会主动消失,除非是客户端主动的delete。
PERSISTENT|SEQUENTIAL:顺序自动编号的znode节点,这种znoe节点会根据当前已近存在的znode节点编号自动加 1,而且不会随session断开而消失。
EPHEMERAL:临时znode节点,Client连接到zk service的时候会建立一个session,之后用这个zk连接实例创建该类型的znode,一旦Client关闭了zk的连接,服务器就会清除session,然后这个session建立的znode节点都会从命名空间消失。总结就是,这个类型的znode的生命周期是和Client建立的连接一样的。
PHEMERAL|SEQUENTIAL:临时自动编号节点,znode节点编号会自动增加,但是会随session消失而消失。
Zookeeper它只负责协调数据,一般 Znode上的数据都比较小以Kb为测量单位。Zookeeper的client和server的实现类都会验证znode存储的数据是否小于1M。如果数据比较大时,Server之间进行数据同步会消耗比较长的时间,影响系统性能。
2).Watcher
Zookeeper中znode产生某种行为(事件)时,如何让客户端得到通知,进行相关操作?Zookeeper中使用Watcher机制,可以针对ZooKeeper服务的“操作”来设置观察,该服务的其他操作可以触发观察。
Zookeeper中的watcher机制类型:
Exists:在path上执行NodeCreated ,NodeDeleted ,NodeDataChanged .
getData Watcher: 在path上执行 NodeDataChanged ,NodeDeleted .
getChildrenWatcher:在paht上执行NodeDeleted .或在子path上执行NodeCreated ,NodeDeleted 。
Zookeeper中对于某个节点设置Watcher是一次性的,在Znode上watcher触发后会删除该Watcher,所以如果需要对某个Znode节点进行长期关注,在事件触发后,需要在该Znode上重置Watcher。
3).基本操作
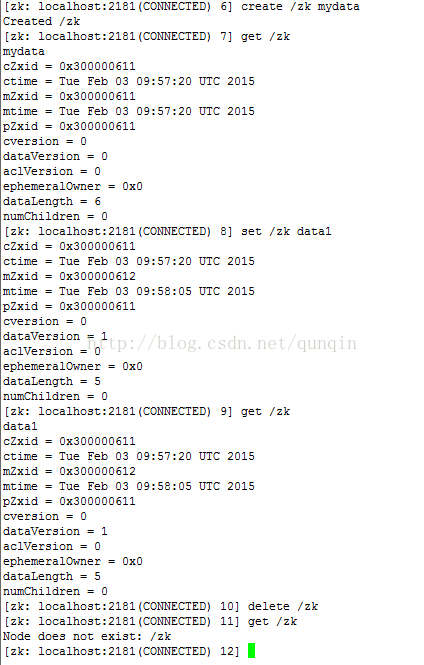
创建节点:
Stringcreate(String path,byte[] data, List
创建一个给定的目录节点 path, 并给它设置数据,CreateMode 标识有四种形式的目录节点
删除节点:
void delete(String path,int version)
删除 path 对应的目录节点,version 为 -1 可以匹配任何版本,也就删除了这个目录节点所有数据
查询节点是否存在:
Stat exists(String path,boolean watch/Watcher watcher)
判断某个 path 是否存在,并设置是否监控这个目录节点
获取节点数据:
byte[] getData(String path,boolean watch, Stat stat)
获取这个 path 对应的目录节点存储的数据,数据的版本等信息可以通过 stat 来指定,同时还可以设置是否监控这个目录节点数据的状态
设置节点数据:
Stat setData(String path,byte[] data, int version)
给 path 设置数据,可以指定这个数据的版本号,如果 version 为 -1 怎可以匹配任何版本
获取节点的子节点:
List
获取指定 path 下的所有子目录节点,同样 getChildren方法也有一个重载方法可以设置特定的 watcher 监控子节点的状态
3 Zookeeper的基本应用
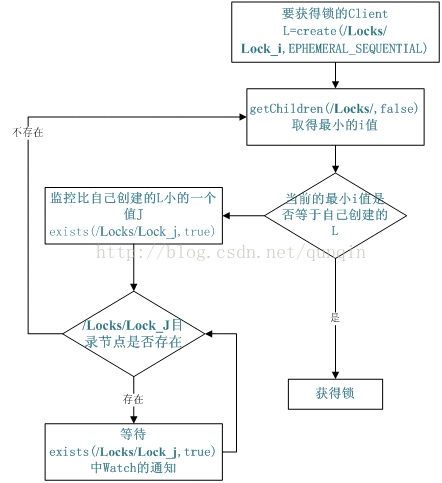
1. 分布式锁
基本思想:
1)首先创建一个作为锁目录(znode),通常用它来描述锁定的实体,称为:/lock_node
2)希望获得锁的客户端在锁目录下创建znode,作为锁/lock_node的子节点,并且节点类型为有序临时节点(EPHEMERAL_SEQUENTIAL);
3)当前客户端调用getChildren(/lock_node)得到锁目录所有子节点,不设置watch,接着获取小于自己的兄弟节点
4)获取小于自己的节点不存在,说明当前客户端顺序号最小,获得锁,结束。
5)若果存在,客户端监视(watch)相对自己次小的有序临时节点状态
6)如果监视的次小节点状态发生变化,则跳转到步骤3,继续后续操作,直到退出锁竞争。
基本代码:
try{
if(lockName.contains(splitStr)) {
thrownew Exception("lockName can not contains \\u000B");
}
mynode= zookeeper.create(lockRoot + "/" + lockName + splitStr,
newbyte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
List
List
for(String children : childrenList) {
String node =children.split(splitStr)[0];
if(node.equals(lockName)) {
childrenName.add(children);
}
}
Collections.sort(childrenName);
//查询自己是否为最小节点,为最小节点即可获得锁
if(mynode.equals(lockRoot + "/" + childrenName.get(0))) {
returntrue;
}
StringsubMyNode = mynode.substring(mynode.lastIndexOf("/") + 1);
/***
* 找自己的邻节点
*/
waitnode= childrenName.get(Collections.binarySearch(childrenName,
subMyNode)- 1);
2. 分布式队列:
一种是常规的先进先出队列;
另一种是要等到队列成员聚齐之后的才统一按序执行。
3. Zookeeper与Hbase
HRegionServer把自己以Ephedral方式注册到Zookeeper中,HMaster随时感知各个HRegionServer的健康状况
Zookeeper避免HMaster单点问题。
4. tbschedule/codis:配置管理
Zookeeper能够很容易的实现集群管理的功能,如有多台 Server 组成一个服务集群,那么必须要一个“总管”知道当前集群中每台机器的服务状态,一旦有机器不能提供服务,集群中其它集群必须知道,从而做出调整重新分配服 务策略。同样当增加集群的服务能力时,就会增加一台或多台 Server,同样也必须让“总管”知道。