3.结构体与链表
转载请标明出处:http://blog.csdn.net/u012637501
一、结构体
struct Student *p:p是一个struct Student *类型的指针变量,
用于存放struct Student类型变量的地址
1.结构体:把一些基本类型数据组合在一起形参的一个新的复合数据类型,用来表示一些复杂的事物,即称为结构体。
2.定义结构体方法
(1)第一种方法:指定结构体名,不定义结构体变量
struct Student
{
int age;
float score;
char sex;
};
(2)第二种方法:指定结构体名,并同时定义一个结构体变量
struct Student2
{
.....
}st2;
(3)第三种方法:不指定结构体名,但定义一个结构体变量
struct
{
.....
}st3;
3.初始化(赋值)与成员变量引用
(1)定义的同时可以整体赋初值;
(2)如果定义完之后,则只能单个的赋初值;
(3)结构体成员引用
方法一:结构体变量名.成员名
方法二:指针变量名->成员名
注:"指针变量名->成员名"比较常用,其在计算机内部会被转化成(*指针变量名).成员名的方式来执行,这两种方式是等价的。如pst->age 会在计算机内部转化成 (*pst).age的方式来执行,没有为什么,这就是->的含义,这也是一种硬性规定。
§举例1:
/*结构体定义与引用*/
#include
struct Student
{
char name;
int age;
char sex;
};
void main()
{
struct Student stu1={'L',18,'g'},stu2; //声明结构体类型变量并初始化
printf("结构体成员所占字节数sizeof(结构体变量/结构体类型) = %d\n\n",sizeof(struct Student));
struct Student *p=&stu1;
//&stu1不能写成stu1,因为struct Student *p表示:p是一个struct Student *类型的指针变量,用于存放struct Student类型变量的地址
p->age=25;
printf("stu1.age=%d\n",stu1.age);
stu2=stu1;
printf("stu2.name=%c\nstu2.age=%d\nstu2.sex=%c\n",stu2.name,stu2.age,stu2.sex);
}
运行结果:

分析说明:
◇p->age的含义是:p指向结构体变量stu1中的age这个成员。p->age在计算机内部会被转换成
(*p).age=stu1.age,而p=&stu1,故p->age=(*p).age=stu1.age( *p=*&stu1=stu1 );
◇ struct Student *p=&stu1,等价于{ struct Student *p; p=&stu1},即将struct Student类型变量的地址
赋值给只能存放(struct Student * )类型的指针变量。
◇结构体变量不能相加,不能相减,也不能互相乘除,但结构体变量可以相互赋值。
◇pst->的含义:pst 所指向的那个结构体变量中的age这个成员。
◇结构体变量的大小略大于其内部成员类型所占字节数之和。
sizeof(struct Student)或sizeof(stud1),需要注意的是,这里计算得到结构体占12字节数据,是因为系统以占字节最大类型对齐(int占4字节最大),故4+4+4=12.
§举例2:通过函数完成对结构体变量的输入和输出
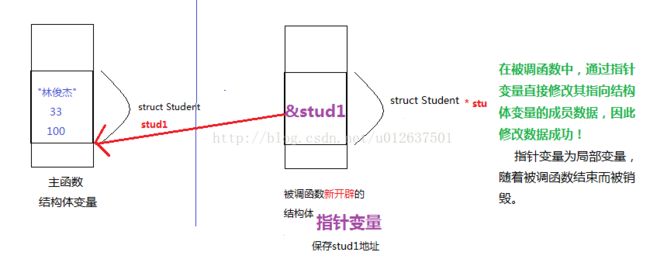
若想通过函数对主函数结构体变量进行修改,则①主函数必须发送地址,②外函数定义指针结构体变量,③通过外函数内部语句完成对变量的修改。 而仅想输出、读取操作,则不用传地址。
即:(1)对结构体变量输入(修改结构体成员),必须发送结构体变量的地址;
(2)对结构体变量输出,可以发送结构体变量,也可以发送结构体变量的地址;
/*举例二:通过函数完成对结构体变量的输入和输出*/
#include
# include
/*1.结构体*/
struct Student
{
char name[20];
int age;
int score;
};
/*2.修改主函数结构体变量成员值
伪算法:
(1)主函数传入结构体变量地址,作为实参;
(2)被调函数定义结构体指针变量,作为形参;
(3)在被调函数中,通过 (指针变量->成员) 或者 (*指针变量).成员 修改数据*/
void InputFunction(struct Student *stu)
{
stu->age = 20; //等价于(*stu).age
strcpy(stu->name,"小龙女"); //stu->name="钟显",会出现
stu->score=99;
}
/*3.输出传入变量的成员数据*/
void OutputFunction(struct Student stu)
{
printf("stud1修改前:name=%s,age=%d,score=%d\n\n",stu.name,stu.age,stu.score);
}
void main()
{
struct Student stud1={"林俊杰",33,100}; //声明一个结构体变量并初始化
OutputFunction(stud1); //输出:变量的成员数据
InputFunction(&stud1); //输入:修改变量的成员数据
printf("stud1修改后:name=%s,age=%d,score=%d\n\n",stud1.name,stud1.age,stud1.score);
}
运行结果:
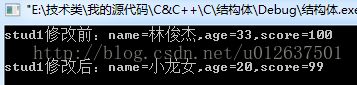
说明分析:
☆对于字符数组成员,如pstu->name = "张三丰"; 或(*pstu).name = "张三丰"; 都是error,
提示错误信息: cannot convert from 'char [5]' to 'char [100]' 。 strcpy(pstu->name,"张三丰"); // 用字符串拷贝命令解决问题
☆倘若希望传递的是结构体变量,而不是结构体变量的地址来修改变量的成员值
如:
void InputFunction(struct Student stu)
{
stu.age = 20; //等价于(*stu).age
strcpy(stu.name,"小龙女"); //stu->name="钟显",会出现
stu.score=99;
}
主函数调用:InputFunction(stud1)。
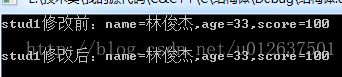
这种方法是不能够修改主函数结构体变量成员值的,因为被调函数中struct Student stu是一个局部变量,当被调函数结束后,stu会被系统回收,所以,最终主函数结构体变量成员值根本没有变化。
内存分析如下:
(2)传递变量

(2)传递地址
§举例3:通过函数完成对结构体变量的输入和输出
- /*举例三:动态构造存放学生信息的结构体数组,并排升序(高>低,反序)*/
- #include
- #include
- # include
- //1.结构体
- struct Student
- {
- char name[20];
- int age;
- int score;
- };
- /*动态一位数组
- * (1)声明一个struct Student *类型指针变量,用于接收malloc的返回值;
- (2)动态开辟一段空间,用于存储len个结构体类型变量;
- (3)结构体数组变量的所有元素赋值*/
- void main(void)
- {
- //a.确定变量个数
- int number,i,j;
- struct Student *pArray,temp;
- printf("请输入学生的个数:number= ");
- scanf("%d",&number);
- //b.动态开辟一段空间
- pArray=(struct Student *)malloc(number*sizeof(struct Student)); //开辟一段空间
- //c.给结构体数组变量赋值
- for(i=0;i
- {
- printf("请输入第%d个学生的信息:\n",i+1);
- printf("name=");
- scanf("%s",pArray[i].name);
- printf("age=");
- scanf("%d",&pArray[i].age);
- printf("score=");
- scanf("%d",&pArray[i].score);
- }
- //d.按学生成绩升序排序(冒泡算法)
- for(i=0;i
- {
- for(j=number-2;j>=i;j--) //number-2表示倒数第二个元素位置(下标)
- {
- if(pArray[j].score>pArray[j+1].score)
- {
- temp=pArray[j]; //注意:temp为struct Student类型
- pArray[j]=pArray[j+1];
- pArray[j+1]=temp;
- }
- }
- }
- //e.输出
- printf("\n\n学生的信息是:\n");
- for (i=0;i
- {
- printf("第%d个学生的信息是:\n", i+1);
- printf("name = %s\n", pArray[i].name);
- printf("age = %d\n", pArray[i].age);
- printf("score = %d\n", pArray[i].score);
- }
- }

二、链表
1.基本概念
(1)头结点:头结点是首结点前面的那个结点,其数据类型和首结点一样,但并不存放有效数
据,设置头结点的目的是为了方便对链表的操作(如头插法建单链表)。
(2)头指针:存放头结点地址的指针变量,确定一个链表必须要有头指针。
(3)首结点:存放第一个有效数据的结点。
(4)尾结点:存放最后一个有效数据的结点。

2.链表优缺点
(1) 数组
优点:存取速度快
缺点:需要一整块连续的空间
(对于庞大数据,往往没有一个适合的较大的连续的空间如a[30000000000000])
插入和删除元素效率很低 (插入和删除中间某个元素,其后的所有都要前后移动)
(2)链表
优点:插入删除元素效率高 ,无需一整块连续的空间
缺点:查找某个位置的元素效率低
(由于不是连续的,不同由下标直接找,必须由头至尾逐一比对查找)
两者各有所长,至今没有出现一个更优的存储方式,可集数组、链表优点于一身。
确定一个链表需要一个参数,头指针
对于每个链表元素,分为左右两部分,左边为数据单元,右边为下一元素地址。
例:
# include
# include
# include
struct Node
{
int data; //数据域
struct Node * pNext; //指针域
};
//函数声明
struct Node * create_list(void);
void traverse_list(struct Node *);
int main(void)
{
struct Node * pHead = NULL;
pHead = create_list();
//create_list():创建一个非循环单链表,并将该链表的头结点的地址付给pHead
traverse_list(pHead);
return 0;
}
struct Node * create_list(void)
{
int len; //用来存放有效节点的个数
int i;
int val; //用来临时存放用户输入的结点的值
//分配了一个不存放有效数据的头结点
struct Node * pHead = (struct Node *)malloc(sizeof(struct Node));
if (NULL == pHead)
{
printf("分配失败, 程序终止!\n");
exit(-1);
}
struct Node * pTail = pHead;
pTail->pNext = NULL;
printf("请输入您需要生成的链表节点的个数: len = ");
scanf("%d", &len);
for (i=0; idata = val;
pTail->pNext = pNew;
pNew->pNext = NULL;
pTail = pNew;
}
return pHead;
}
void traverse_list(struct Node * pHead)
{
struct Node * p = pHead->pNext;
while (NULL != p)
{
printf("%d ", p->data);
p = p->pNext;
}
printf("\n");
return;
}