0.目录
- 浮点数的表示
- 加减
- 存储格式
- 特殊的数
1.浮点数的表示
1.1 表示格式
浮点数,顾名思义,是小数点不固定的数。计算机中,根据小数点位置是否固定,分为两种数据格式,一种小数点不固定,另一种是定点数,小数点固定。
书上科学地对浮点数表示法的定义是,以适当的形式将比例因子表示在数据中,让小数点的位置根据需要而浮动。我们计算机的容量有限,不可能对每个数都用特别多的位数来表示,如2×10^99,这种非常大的数不可能用定点数来表示,所以利用浮点数可以在位数有限的情况下扩大数的表示范围,同时保持一定的有效精度。
通常情况下,浮点数表示为:N = r ^ E × M
- r 是浮点数阶码的底,在计算机中是隐含的,通常情况下r=2
- E叫做阶码,是带符号的定点数,E的大小越大,能表示的数范围越大
- M叫做尾数,是带符号的定点数,M的位数越大,数的有效精度越高
如1.111×2100,1.111是尾数,100是阶码,阶码位数为3位,尾数位数是4位。若阶码位数有4位,尾数位数是3位(总占位数不变),那这个数表示为1.11×20100,能表示的数的范围变大,原来尾数1.111转变为1.11损失了0.001,这就是精度的损失。
浮点数的一般格式:

这里J是阶符,表示阶码的符号,S是数符,表示浮点数的符号,阶符J和阶码的m位合起来表示浮点数的表示范围和小数点的实际位置,n位尾数反映了浮点数的精度。
1.2 规格化
同一个浮点数可以有很多表现形式,如1.111×23,可以表示为0.1111×24或11.11×22。如果尾数位数只有4位,表示同一个数1111可以采取两种方法, 0.0111x25 和 0.1111×24(二者最高为是数符位S),可以很清晰地看到,如果采用阶码为5的方法,我们损失了一位精度,阶码为4的方法表示这个数更为精确。
所以,为了提高运算精度,就要充分利用尾数的有效数位,也就是浮点数的规格化,即规定尾数的最高数位必须是一个有效值。非规格化数转变为规格化数,转变过程就是通过调整尾数和阶码的大小,使尾数最高位保证是一个有效值。通常有两种规格化操作:
- 左规:当浮点数运算结果是非规格化数的时候,要进行规格化操作,将尾数算术左移一位,阶码减1(基数为2时),左规操作可能要进行多次。
- 右规:当浮点数运算结果尾数出现溢出的时候,将尾数算术右移一位,阶码加1。需要右规操作的时候只需要操作一次。
规格化浮点数的尾数M的绝对值应该满足这样的关系:1/r ≤ |M| ≤ 1(r就是我们的阶码的底,也是基数)。
以r=2为例:
- 原码尾数规格化后:正数为0.1xxxxxx形式,最大值为0.11......1;最小值为0.100......0。负数为1.1xxxxxx形式,最大值表示为1.10......0;最小值表示为1.11......1。
- 补码尾数规格化后:正数同原码正数。负数为1.0xxxxxx形式,最大值表示为1.01......1;最小值表示为1.00......0。
需要注意的是基数,刚刚是以基数为2时的规格化形式,补码规格化数的尾数最高位一定与尾数符号位相反。基数不同的时候,规格化的形式不同,当基数为4时,原码规格化形式的尾数最高两位不全为0;基数为8时,原码规格化形式的尾数最高三位不全为0。
如何判断一个浮点数是否是规格化数:规格化浮点数的尾数小数点后的第一位一定是个非零的数。因此对于原码编码的尾数来说,只要看尾数的第一位是否为1就行;对于补码表示的尾数,只要看符号位和尾数最高位是否相反。(IEEE 754标准的浮点数尾数是用原码编码的)
2.加减
浮点数运算的特点是阶码运算和尾数运算分开来算。加减运算一律采用补码。具体运算分为以下几步。
- 对阶:目的是让两个数小数点的位置看齐,使两个数的阶码相等。显然1.1×23 和1.1×24 是不能直接相加减的。原则是小阶向大阶看齐,像这个例子,就是1.1×23 的尾数右移一位,阶码加一,直到两个数的阶码相等
- 尾数求和:阶码对齐之后直接按照定点数的加减法则运算尾数
- 规格化:尾数求和后的结果如果不是规格化数需要规格化,以双符号位运算为例,如果运算结果为正数,规格化的形式应该是00.1xxx......x,如果运算结果为负数,规格化后的形式应该是11.0xxx......x,不符合这种形式的数要进行左规或者右规的操作让其变成这种形式。(在尾数没有溢出的情况下,即尾数结果的双符号为不是10或01的时候,操作都是左规操作,左规操作可能不止进行一次,倘若双符号位为01或10则表明尾数已经溢出了,就要进行右规操作,右规只需要进行一次)
- 舍入:在对阶和右规的操作中都是将尾数右移,阶码加一,由于位数是有限的,在右移的操作过程中很有可能就将低位的尾数丢失,引起误差和精度问题。常用的减小误差的方法有“0”舍“1”入法:即在尾数右移时,被移去的最高数值位为0则舍去,如果被移去的最高数值位为1则在尾数末位加1,如果加1之后又产生溢出则再右规操作一次。恒置“1”法:看名字就可以知道,无论丢掉的最高数值位是1还是0,都使右移后的尾数末位置1。这种方法可能使尾数变大或者变小。
- 溢出判断:既然定点数运算可能溢出,浮点数同样也会溢出,我们已经知道浮点数的表示方法和加减运算规则,既然是溢出,那么肯定是超出了浮点数能表示的范围,浮点数的范围主要是由阶码决定的,如果运算结果规格化后阶码产生了溢出,那才是浮点数的溢出。浮点数的溢出与否是由阶码的符号决定的。以双符号位的补码为例,如果阶码的符号位出现01或10则说明阶码溢出了,01表示阶码大于最大阶码,上溢,进入中断处理;10表示阶码小于最下阶码,下溢,按机器零处理。(溢出时真值的符号位和高位符号位保持一致)还要注意的一点是尾数之和(差)可能会造成尾数的溢出,这并不代表整个的溢出,需要右规一次看阶码是否溢出才能判断。
3.存储格式
IEEE754标准规定,浮点数由“符号”、“指数”和“尾数”3部分构成:
下表列出C++中不同精度浮点数内存布局:
| 精度 | C++类型 | 长度 | 符号位数 | 指数位数 | 尾数位数 | 有效位数 | 指数偏移 | 隐含位 |
|---|---|---|---|---|---|---|---|---|
| 单精度浮点数 | float | 32 | 1 | 8 | 23 | 24 | 127 | 1个隐含位 |
| 双精度浮点数 | double | 64 | 1 | 11 | 52 | 53 | 1023 | 1个隐含位 |
| 扩展双精度浮点数 | long double | 80 | 1 | 15 | 64 | 64 | 16383 | 无隐含位 |
float的规格化表示为:±1.f×2E−127,f是尾数,E是指数。以float为例:

比如十进制数123.125,其二进制表示为:1111011.001,规格化表示为:1.111011001×26,也就是1.111011001×2133−127,f = 111011001,E = 133,二进制为10000101,图示如下:
规格化表示的浮点数,整数位固定为1,可以省略,所以用23位可以存储24位的尾数。这里可以得出一个结论:任意一个int值(二进制表示),只要存在这样的序列:从最低位开始找到第一个1,然后从这个1向高位数移动24位停下,如果更高的位上不再有1,那么该int值即可被float精确表示,否则就不行。简单说,就是第一个1开始到最后一个1为止的总位数超过24,那么该int值就不能被float类型精确表示,例:

图中能被丢弃的0,在指数上体现出来,丢弃一个0,指数就加1,丢弃n个0,指数就加n,并没有损失精度。
很容易得出,从1开始的连续整数里面第一个不能被float精确表示的整数,其二进制形式为:1 00000000 00000000 00000001,即16777217:1.00000000 00000000 00000001×224,f有24位,最后一个1只能舍弃,也就是 1.00000000 00000000 0000000×224,即1.0×224,这个数实际上是16777216。也就是说16777217和16777216的内存表示是一样的:
那么16777217之后的下一个可以被float精确表示的int值是多少呢?很简单,向16777217上不断的加1,直到满足“第一个1开始到最后一个1为止的总位数为24位”:

1 00000000 00000000 00000010就是16777218,规格化表示为:
1.00000000 00000000 0000001×224=1.00000000 00000000 0000001×2151−127
其f是23位(最后一位是1)。
2.原理
二进制的浮点数,其科学记数法的形式为:
其中只能是0或1。规格化表示为:
即约定小数点位于最高位的1之后,因此不能是0。既然整数位只能是1,那么这一位可以不用存储,称之为隐含位。好处是可以多存储一位小数部分,但是在作浮点运算时需要特殊处理,运算之前要补齐这一位,运算之后又得略去这一位,会有一点性能损耗;如果有效位本来就足够多,省去整数位也赚不了多少便宜,这可能是扩展双精度浮点数不采用这种方案的原因。
指数n是一个普通的整数,可正可负(负指数表示纯小数),在计算机科学,整数编码一般采用补码(负数是其正数的反码+1),最高位是符号位(0表示正数,1表示负数),但IEEE754标准中,浮点数的指数使用了“真值 + 偏移值”的编码方式,将原码空间分成两部分,小的部分表示负数,大的部分表示正数。一般的,全0和全1都有特殊用途,以float为例,其指数部分有8位,原码空间就是0 ~ 255,不算0和255(全0和全1),剩下254个数,对半分即127,则N位指数的编码和原值有下列关系:
其中,E:指数编码;e:指数真值 。float类型的指数编码就是:E=e+127,[ 1,127 ) 是负数, [ 127, 254 ] 是正数,0和255有特殊用途。
3.分类
IEEE标准定义了6类浮点数:
| 指数 | 分类 | 隐含位 | 尾数 | 说明 |
|---|---|---|---|---|
| xx…xx | 有限数 | 1 | xx…xx | 指数非全0,非全1,有隐含位 |
| 00…00 | 0 | 0 | 0 | 尾数为0 |
| 00…00 | 弱规范数 | 无 | xx…xx | 尾数不是0 |
| 11…11 | ±∞ | 1 | 0 | 尾数不为0 |
| 11…11 | QNaN | 1 | 1xx…xx | 尾数高位为1,但尾数不为0 |
| 11…11 | SNaN | 1 | 0xx…xx | 尾数高位为0,但尾数不为0 |
3.1 有限数
有限数就是遵循规格化的常规数,其指数在最小数和最大数之间,且整数位恒为1,其形式为:
例如float,其指数E有8位,取值范围为 ( 0, 255 ) 也就是 [ 1, 254 ] 。有限数在运算过程中最常见的问题就是溢出,即运算结果无法用有限数表示。
3.2 零
0,有一位隐含位(为0),除符号位可能不为0外,其它所有位都为0,也就是说存在正0和负0,其形式为:
数学上,0没有正负之说,但按IEEE754标准,却有正负0之分(由符号位标识),注意:正0应该和负0相等,而不应正0大于负0。
3.3 弱规范数
弱规范数的指数和0一样,都是全0,但没有隐含位,尾数部分不为0,其形式为:
弱规范数的整数位是尾数的最高位。由于弱规范数没有隐含位,在向有限数转换时,要向高位移一位,以产生隐含位,但指数不变(不减1);从有限数形式转换成弱规范数形式时,正好相反,向低位移1位,指数仍不变。
在计算过程中,如果中间结果小于最小的有限数却不是0,即出现下溢,如果当做0处理,可能会导致计算终止,引入“弱规范数”之后,在0和最小的有限数之间有相当一部分数可以表示为“弱规范数”,从而提高了计算能力。
3.4 无穷大
±∞,指数部分为全1(即最大值),整数位是1(是隐含位),尾数是0,其形式为:
float类型即:
产生∞的情形一般有:
- 自身运算,例如∞+1.0=∞
- 被0除,例如1/0=∞,1/−0=−∞
- 上溢,即计算结果超出了类型范围
3.5 NaN
NaN,即Not a Number,和∞一样,指数部分为全1(最大值),整数位是1(是隐含位),但尾数部分不为0,其形式为:
其中,f不为0。NaN有SNaN(Signal NaN)和QNaN(Quiet NaN)之分,IEEE标准要求:SNaN参与运算要触发异常,而QNaN则不触发异常。两者的区别在于,SNaN的尾数最高位是0,而QNaN的尾数最高位是1。
IEEE标准只规定NaN的尾数不为0,并没有限定应该是什么,这就给予具体实现一定的空间。比如可以在计算出问题时,在尾数部分设置一些特殊的值,有利于调试。
NaN有一些晦涩的运算规则:
- 0×∞=NaN,因此“0乘任何数都是0”不是恒成立的
- NaN参与的所有逻辑运算,只有NaN!=NaN为真,其它的都不为真,即使NaN==NaN的结果也为false,因此在浮点数的逻辑运算中,编译器没有办法做积极的优化,因为如果有NaN参与逻辑运算,比如x=NaN,那么!(x
令人无语的是,编译器不一定遵循IEEE标准的规定,可想而知,浮点运算有多难搞。
4.特殊的数
4.1 最小的正float有限数
根据有限数的规格化形式,指数取最小值1,隐含位是1,尾数取最小值0(23位都是0):
如果浮点运算的结果小于这个数,就出现下溢,一般将其结果转换为最小的有限数,或者弱规范数,如果弱规范数也不能表示,那么将转换成0。
4.2 最大的float有限数
根据有限数的规格化形式,指数取最大值254,隐含位是1,尾数取最大值(23位都是1):
如果浮点运算的结果超过这个数,就出现上溢,一般将其结果转换为最近的有限数或∞。
4.3 最小的正float弱规范数
根据弱规范数的规格化形式,尾数取最小值:
f是23位,且最高位是整数位,因此小数点之后只有22位,最后一位为1,即可得出该数。
4.4 FLT_EPSILON
FLT_EPSILON是C++定义的一个float数,该数是满足1.0+FLT_EPSILON!=1.0的最小的float有限数,比该数还小的float有限数会有:1.0+x=1.0。根据这个定义,从比1.0大的最小float有限数开始推导:
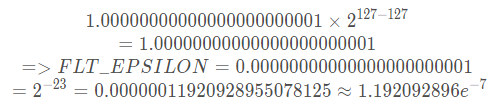
它的规格化表示:1.0×2e(104−127),E = 104,f = 0。注意,该数远不是最小的正float有限数,它比最小的正float有限数还要“大很多”,它的指数是-23,而最小的正float有限数的指数是-126。这个数并没有什么特别的意义,在代码中无条件的使用 fabs (x − y) < FLT_EPSILON判断两个浮点数是否相等,可能会导致问题。如果你的系统中浮点数很小,极端来说,甚至小于FLT_EPSILON,那你用fabs (x − y) < FLT_EPSILON来判断相等,显然是错误的,你应该自己定义一个可以接受的误差范围来辅助判断相等问题。