Rust: duckdb和polars读csv文件比较
duckdb在数据分析上,有非常多不错的特质。1、快;2、客户体验好,特别是可以同时批量读csv(在一个目录下的csv等文件)。polars的性能比pandas有非常多的超越。但背后的一些基于arrow的技术栈有很多相同之类。今天想比较一下两者在csv数据读写的情况。
一、文件准备
csv样本内容,是N行9列的csv标准格式,有字符串,有浮点数,有整型。具体如下:
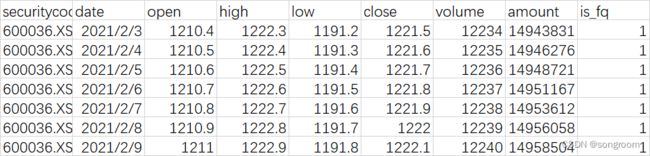 本次准备了两个csv文件,一个大约是2.1万行、9列;一个是64万行、9列;模式完全一样。更大的类似百万行或千万行的数据目前暂不比较。这种数据量级较少。
本次准备了两个csv文件,一个大约是2.1万行、9列;一个是64万行、9列;模式完全一样。更大的类似百万行或千万行的数据目前暂不比较。这种数据量级较少。
二、toml文件
[package]
name = "my_duckdb"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
duckdb = { version = "0.10.2", features = ["bundled"] }
polars = { version = "0.26.1", features = ["lazy"] } # 注意这个version号!
polars的设置也可以是:
polars = { version = "*", features = ["lazy"] }
三、main.rs
在polars中,有两种模式,即lazy(延迟)和eager(即时)。通常的话,lazy模式效率更高,更为推荐!特别是进行特定数据过滤filter等操作时。
use duckdb::{
arrow::{record_batch::RecordBatch, util::pretty::print_batches},
Connection, Result,
};
use polars::prelude::*;
use std::time::Instant;
use std::fs::File;
fn main() {
let time0 = Instant::now();
// //test.csv:2w行;test2.csv:64w行
let csvs = ["test.csv","test2.csv"];
for csv in csvs{
println!("-----------{:?}-------------",csv);
duckdb_read_csv(csv).unwrap();
polars_eager_read_csv(csv);
polars_lazy_read_csv(csv);
println!("-----------{:?}-------------",csv);
}
println!("duckdb和polars读文件共花:{:?}秒!",time0.elapsed().as_secs_f32()
}
fn duckdb_read_csv(filepath:&str) ->Result<()> {
let duckdb_csv_time = Instant::now();
let db = Connection::open_in_memory()?;
let sql_format = format!("SELECT * from read_csv('{}');",filepath);
let rbs: Vec<RecordBatch> = db
.prepare(&sql_format)?
.query_arrow([])?
.collect();
// 批量打印
//print_batches(&rbs).unwrap();
assert!(rbs.len()>0);
println!("duckdb取出的行数:{:?} 列数:{:?}",rbs[0].num_rows(),rbs[0].num_columns());
println!("duckdb 读csv花时: {:?} 秒!", duckdb_csv_time.elapsed().as_secs_f32());
let _ = db.close();
Ok(())
}
//eager 模式
fn polars_eager_read_csv(filepath:&str){
let polars_eager_csv_time = Instant::now();
let df = CsvReader::from_path(filepath)
.unwrap()
.has_header(true)
.finish()
.unwrap();
println!("polars eager 读出csv的行和列数:{:?}",df.shape());
println!("polars eager 读csv 花时: {:?} 秒!", polars_eager_csv_time.elapsed().as_secs_f32());
}
// lazy 模式
fn polars_lazy_read_csv(filepath:&str){
let polars_lazy_csv_time = Instant::now();
let p = LazyCsvReader::new(filepath)
.has_header(true)
.finish().unwrap();
let mut df = p.collect().expect("error to dataframe!");
println!("polars lazy 读出csv的行和列数:{:?}",df.shape());
println!("polars lazy 读csv 花时: {:?} 秒!", polars_lazy_csv_time.elapsed().as_secs_f32());
polars_write_csv(&mut df,&format!("polars_{}",filepath))
}
fn polars_write_csv(df: &mut DataFrame,pathfile:&str){
let polars_write_csv_time =Instant::now();
let mut file = File::create(pathfile).expect("could not create file");
CsvWriter::new(&mut file)
.has_header(true)
.with_delimiter(b' ')
.finish(df).expect("error!");
println!("polars write csv 花时: {:?} 秒!", polars_write_csv_time.elapsed().as_secs_f32());
}
四、输出
-----------"test.csv"-------------
duckdb取出的行数:2048 列数:9
duckdb 读csv花时: 0.03224426 秒!
polars eager 读出csv的行和列数:(21357, 9)
polars eager 读csv 花时: 0.007638709 秒!
polars lazy 读出csv的行和列数:(21357, 9)
polars lazy 读csv 花时: 0.002562615 秒!
polars write csv 花时: 0.004541633 秒!
-----------"test.csv"-------------
-----------"test2.csv"-------------
duckdb取出的行数:2048 列数:9
duckdb 读csv花时: 0.14970613 秒!
polars eager 读出csv的行和列数:(640710, 9)
polars eager 读csv 花时: 0.026194088 秒!
polars lazy 读出csv的行和列数:(640710, 9)
polars lazy 读csv 花时: 0.020053046 秒!
polars write csv 花时: 0.06960724 秒!
-----------"test2.csv"-------------
duckdb和polars读文件共花:0.31616783秒!
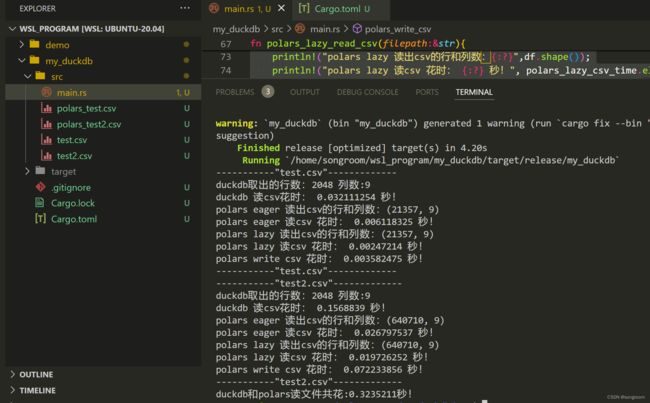
结论:
1、从上面的样本来看,分别用duckdb和polars来读csv两个不同大小的文件,polars有优势。
当然,也可能是duckdb库封装的问题,也可能是文件大小不同,测试代表性还不全。谨供参考!
2、lazy模式较eager模式更有优势。
此外,polars的csv写的效率也不错。
五、问题
从输出可以明显看出,duckdb库读出来的num_rows是有问题的。这个问题还待查实。从print_batches(&rbs).unwrap(),打印出来的内容来看,并没有少。