mysql数据库入门教程(5):多表操作(连接查询,子查询,分页查询,联合查询)
前文介绍了单表查询:mysql数据库入门教程(4):查询讲解大全
今天介绍下多表查询
一.连接查询
含义:又称多表查询,当查询的字段来自于多个表时,就会用到连接查询
先送上下面所讲用到的sql脚本
https://download.csdn.net/download/KOBEYU652453/12699277
其中有数据库myemployees,girls
1笛卡尔乘积现象
笛卡尔乘积现象:表1 有m行,表2有n行,结果=m*n行
发生原因:没有有效的连接条件
如何避免:添加有效的连接条件
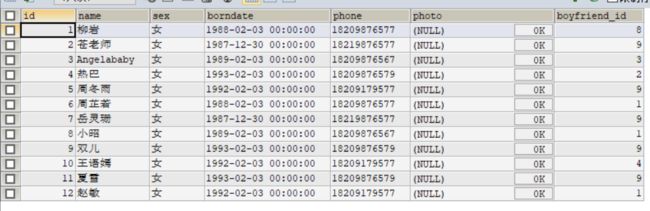
如图所示,beauty 表里有我们的女神,女神id,以及她的男朋友id
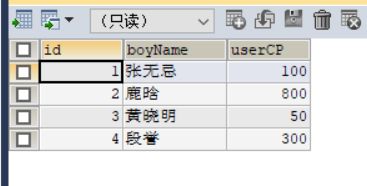
boys表结构
如果我们想要把女神以及和她的男朋友整合成一张表。
如果我们使用语句
SELECT NAME,boyName FROM beauty ,boys;
得到结果,是一个48行的表格,每个女神有多个男朋友?果然女神的世界,我们不懂。
这个表匹配出来的结果不是我们想要的。
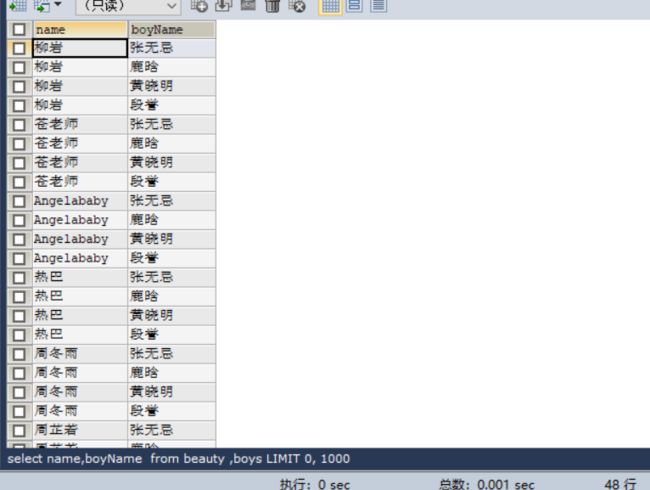
如何避免:添加有效的连接条件,如使第一张表的boyfriend_id 等于 第二张表的id
SELECT NAME,boyName FROM boys,beauty
WHERE beauty.boyfriend_id= boys.id;
2连接查询分类
内连接,外连接,交叉连接

3等值连接
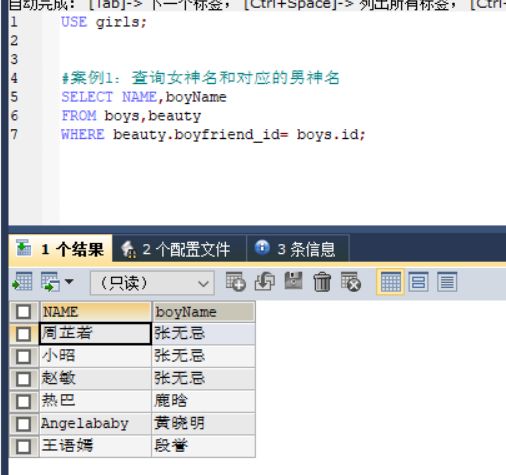
#案例1:查询女神名和对应的男神名
SELECT NAME,boyName
FROM boys,beauty
WHERE beauty.boyfriend_id= boys.id;
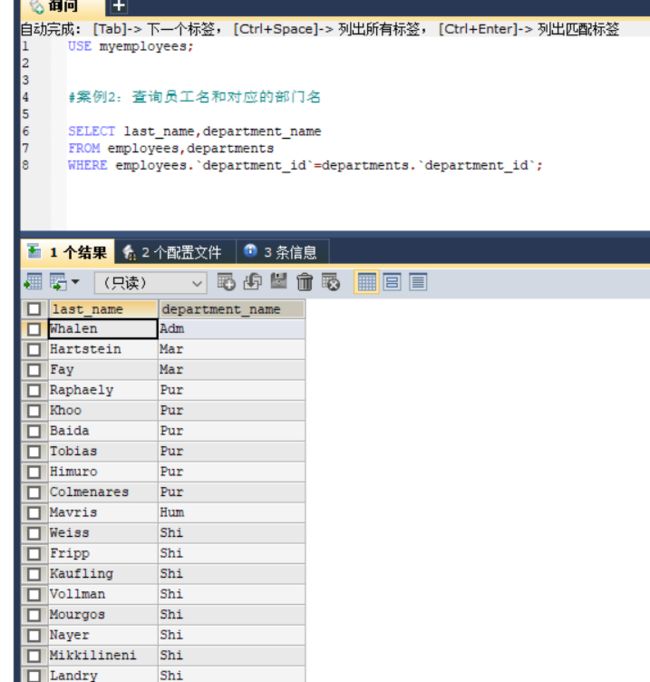
#案例2:查询员工名和对应的部门名
SELECT last_name,department_name
FROM employees,departments
WHERE employees.`department_id`=departments.`department_id`;
#2、为表起别名
/*
①提高语句的简洁度
②区分多个重名的字段
注意:如果为表起了别名,则查询的字段就不能使用原来的表名去限定
因为执行顺序是先from 再select
*/
USE myemployees;
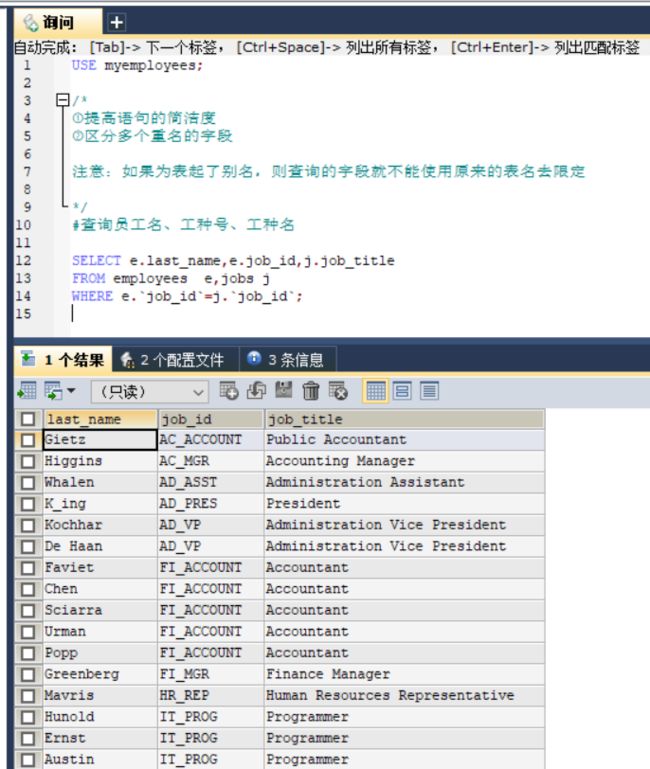
#查询员工名、工种号、工种名
SELECT e.last_name,e.job_id,j.job_title
FROM employees e,jobs j
WHERE e.`job_id`=j.`job_id`;
两个表的顺序可以交换
#3、两个表的顺序是否可以调换
#查询员工名、工种号、工种名
SELECT e.last_name,e.job_id,j.job_title
FROM jobs j,employees e
WHERE e.`job_id`=j.`job_id`;
可以加筛选
因为前面有了where,不能再加where,所以添加and。
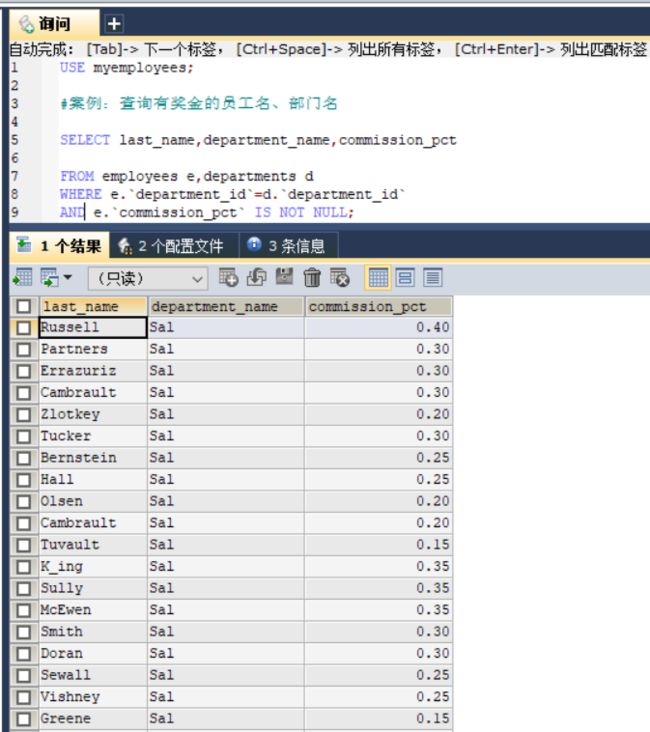
#案例:查询有奖金的员工名、部门名
SELECT last_name,department_name,commission_pct
FROM employees e,departments d
WHERE e.`department_id`=d.`department_id`
AND e.`commission_pct` IS NOT NULL;
可以加分组
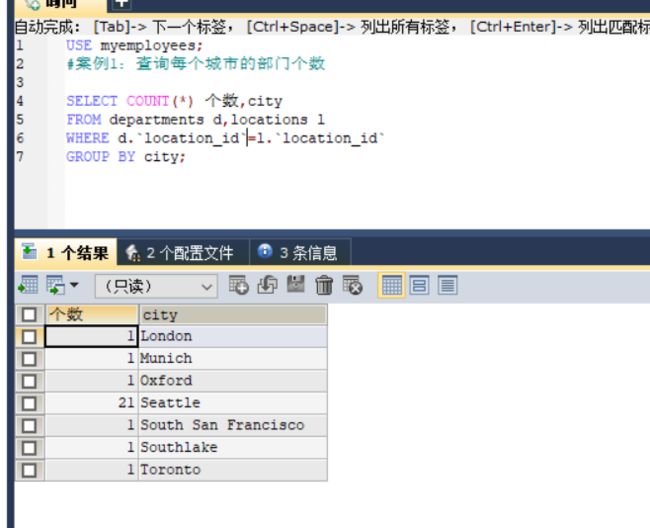
#案例1:查询每个城市的部门个数
SELECT COUNT(*) 个数,city
FROM departments d,locations l
WHERE d.`location_id`=l.`location_id`
GROUP BY city;
可以加排序
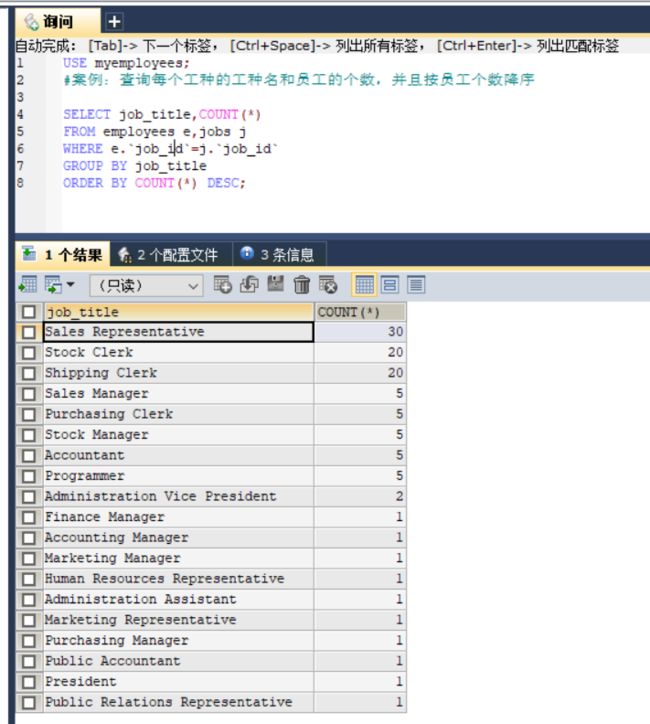
#案例:查询每个工种的工种名和员工的个数,并且按员工个数降序
SELECT job_title,COUNT(*)
FROM employees e,jobs j
WHERE e.`job_id`=j.`job_id`
GROUP BY job_title
ORDER BY COUNT(*) DESC;
可以实现三表连接
#案例:查询员工名、部门名和所在的城市
SELECT last_name,department_name,city
FROM employees e,departments d,locations l
WHERE e.`department_id`=d.`department_id`
AND d.`location_id`=l.`location_id`;

4自连接
自连接是一种特殊的等值查询
把一张表 另命名两次 就变成啦等值连接。
如表所示,原图给出的员工ID 以及他的领导id,
我们想要直接把员工名与他的领导抽取出来做成一张表。
这时就用到的自连接。
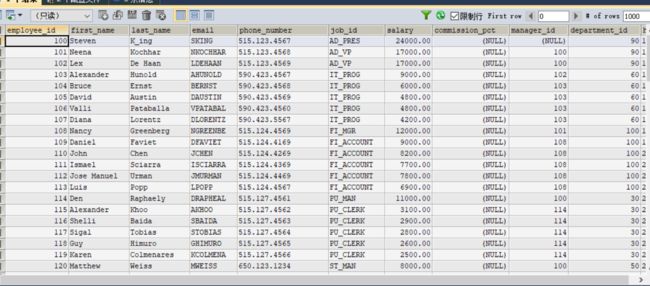
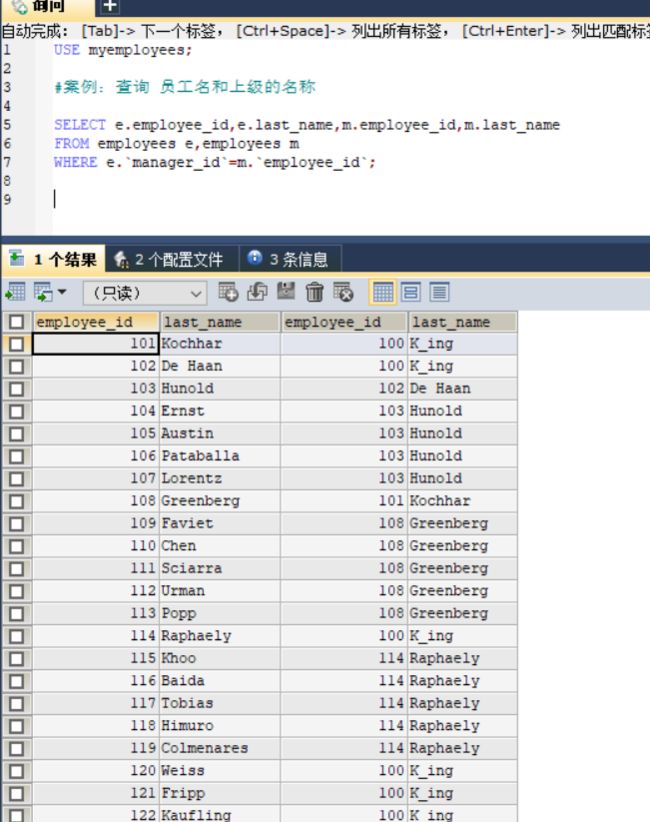
#案例:查询 员工名和上级的名称
SELECT e.employee_id,e.last_name,m.employee_id,m.last_name
FROM employees e,employees m
WHERE e.`manager_id`=m.`employee_id`;
二.sql99语法的连接查询
前面讲的是92语法。92语法把连接条件和筛选条件都放在啦where后面,可读性较差。
99语法:连接条件放在on后面,筛选条件where,等后面
分类:
内连接(★):inner
外连接
左外(★):left 【outer】
右外(★):right 【outer】
全外:full【outer】
交叉连接:cross
语法:
select 查询列表
from 表1 别名 【连接类型】
join 表2 别名
on 连接条件
【where 筛选条件】
【group by 分组】
【having 筛选条件】
【order by 排序列表】
连接类型为前面分类提到的inner,leftouter…
如图内连接语法
#一)内连接
/*
语法:
select 查询列表
from 表1 别名
inner join 表2 别名
on 连接条件;
#sql92和 sql99pk
/*
功能:sql99支持的较多
可读性:sql99实现连接条件和筛选条件的分离,可读性较高
*/
1.sql99语法的等值连接
特点:
①添加排序、分组、筛选
②inner可以省略
③ 筛选条件放在where后面,连接条件放在on后面,提高分离性,便于阅读
④inner join连接和sql92语法中的等值连接效果是一样的,都是查询多表的交集
#案例1.查询员工名、部门名
SELECT last_name,department_name
FROM departments d
JOIN employees e
ON e.`department_id` = d.`department_id`;
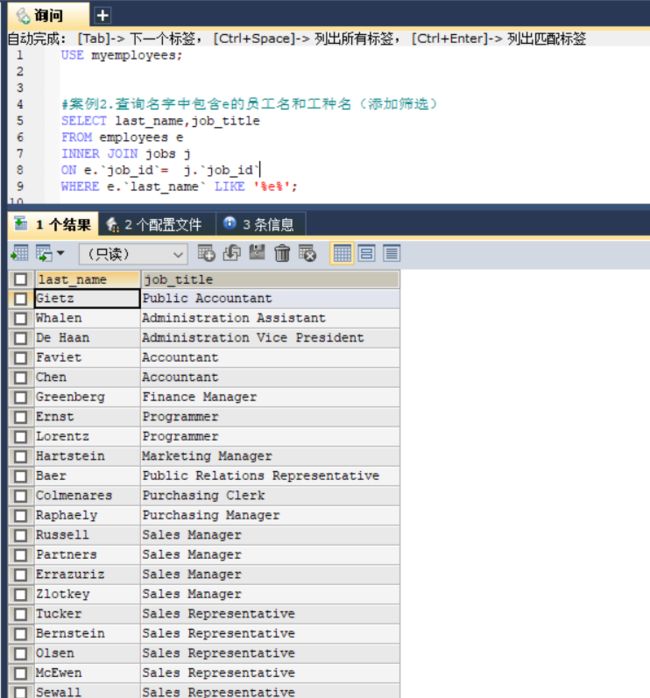
#案例2.查询名字中包含e的员工名和工种名(添加筛选)
SELECT last_name,job_title
FROM employees e
INNER JOIN jobs j
ON e.`job_id`= j.`job_id`
WHERE e.`last_name` LIKE '%e%';
#3. 查询部门个数>3的城市名和部门个数,(添加分组+筛选)
#①查询每个城市的部门个数
#②在①结果上筛选满足条件的
SELECT city,COUNT(*) 部门个数
FROM departments d
INNER JOIN locations l
ON d.`location_id`=l.`location_id`
GROUP BY city
HAVING COUNT(*)>3;
三表连接
#5.查询员工名、部门名、工种名,并按部门名降序(添加三表连接)
SELECT last_name,department_name,job_title
FROM employees e
INNER JOIN departments d ON e.`department_id`=d.`department_id`
INNER JOIN jobs j ON e.`job_id` = j.`job_id`
ORDER BY department_name DESC;
2.sql99语法的非等值连接
语法 连接条件 :between and
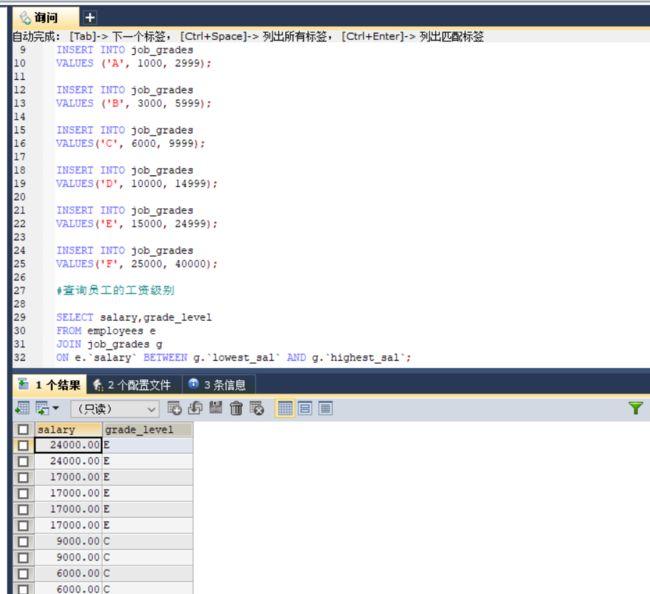
#查询员工的工资级别
创建级别表
USE myemployees;
CREATE TABLE job_grades
(grade_level VARCHAR(3),
lowest_sal INT,
highest_sal INT);
INSERT INTO job_grades
VALUES ('A', 1000, 2999);
INSERT INTO job_grades
VALUES ('B', 3000, 5999);
INSERT INTO job_grades
VALUES('C', 6000, 9999);
INSERT INTO job_grades
VALUES('D', 10000, 14999);
INSERT INTO job_grades
VALUES('E', 15000, 24999);
INSERT INTO job_grades
VALUES('F', 25000, 40000);
查询
#查询员工的工资级别
SELECT salary,grade_level
FROM employees e
JOIN job_grades g
ON e.`salary` BETWEEN g.`lowest_sal` AND g.`highest_sal`;
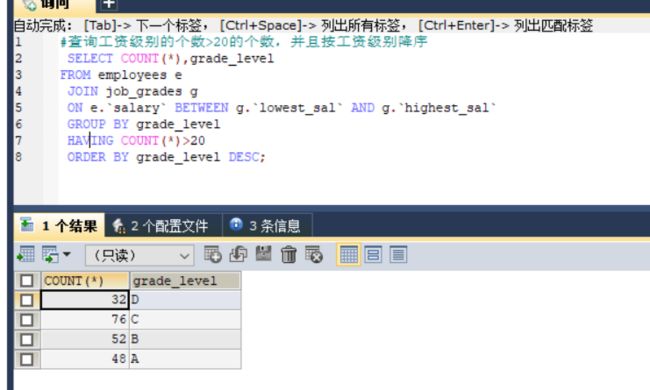
#查询工资级别的个数>20的个数,并且按工资级别降序
SELECT COUNT(*),grade_level
FROM employees e
JOIN job_grades g
ON e.`salary` BETWEEN g.`lowest_sal` AND g.`highest_sal`
GROUP BY grade_level
HAVING COUNT(*)>20
ORDER BY grade_level DESC;
3.sql99语法的自连接
#查询员工的名字、上级的名字
SELECT e.last_name,m.last_name
FROM employees e
JOIN employees m
ON e.`manager_id`= m.`employee_id`;
#查询姓名中包含字符k的员工的名字、上级的名字
SELECT e.last_name,m.last_name
FROM employees e
JOIN employees m
ON e.`manager_id`= m.`employee_id`
WHERE e.`last_name` LIKE '%k%';
4.sql99语法的左(右)外连接
/*
应用场景:用于查询一个表中有,另一个表没有的记录
特点:
1、外连接的查询结果为主表中的所有记录
如果从表中有和它匹配的,则显示匹配的值
如果从表中没有和它匹配的,则显示null
外连接查询结果=内连接结果+主表中有而从表没有的记录
2、左外连接,left join左边的是主表
右外连接,right join右边的是主表
3、左外和右外交换两个表的顺序,可以实现同样的效果
4、全外连接=内连接的结果+表1中有但表2没有的+表2中有但表1没有的
*/
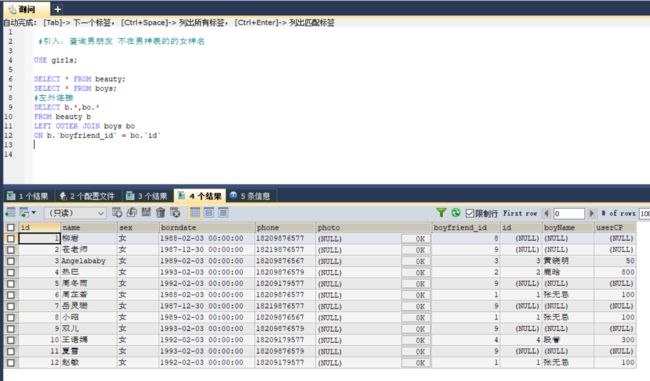
#引入:查询男朋友 不在男神表的的女神名
USE girls;
SELECT * FROM beauty;
SELECT * FROM boys;
#左外连接
SELECT b.*,bo.*
FROM beauty b
LEFT OUTER JOIN boys bo
ON b.`boyfriend_id` = bo.`id`
主表为beauty
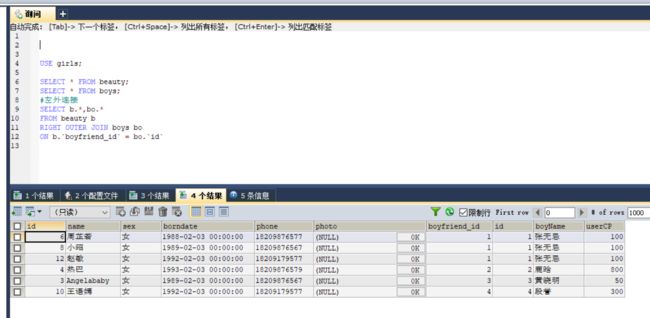
如果将上述代码改为右连接
主表为boys
USE myemployees;
#案例1:查询哪个部门没有员工
#左外
SELECT d.*,e.employee_id
FROM departments d
LEFT OUTER JOIN employees e
ON d.`department_id` = e.`department_id`
WHERE e.`employee_id` IS NULL;
USE myemployees;
#右外
SELECT d.*,e.employee_id
FROM employees e
RIGHT OUTER JOIN departments d
ON d.`department_id` = e.`department_id`
WHERE e.`employee_id` IS NULL;
主表为部门

5.sql99语法的全外连接
语法不支持
介绍下语法
#全外
USE girls;
SELECT b.*,bo.*
FROM beauty b
FULL OUTER JOIN boys bo
ON b.`boyfriend_id` = bo.id;
6.sql99语法的交叉连接
交叉连接即笛卡尔乘积的实现
USE girls;
#交叉连接
SELECT b.*,bo.*
FROM beauty b
CROSS JOIN boys bo;

7.sql99语法的总结


三.子查询

#一、where或having后面
/*
1、标量子查询(单行子查询)
2、列子查询(多行子查询)
3、行子查询(多列多行)
特点:
①子查询放在小括号内
②子查询一般放在条件的右侧
③标量子查询,一般搭配着单行操作符使用
< >= <= = <>
列子查询,一般搭配着多行操作符使用
in、any/some、all
④子查询的执行优先于主查询执行,主查询的条件用到了子查询的结果
*/
1.where后面的标量子查询使用
标量子查询 :子查询的值是一个值
USE myemployees;
#1.标量子查询★
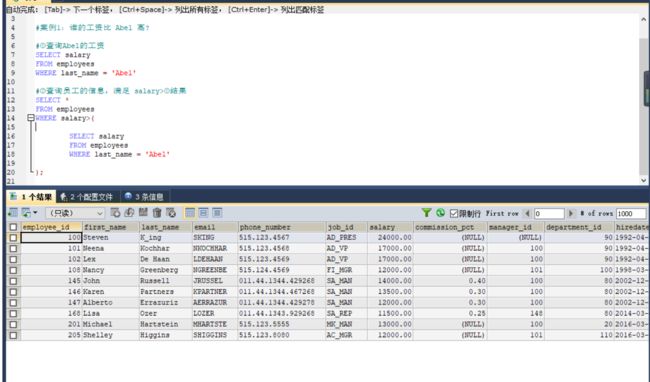
#案例1:谁的工资比 Abel 高?
#①查询Abel的工资
SELECT salary
FROM employees
WHERE last_name = 'Abel'
#②查询员工的信息,满足 salary>①结果
SELECT *
FROM employees
WHERE salary>(
SELECT salary
FROM employees
WHERE last_name = 'Abel'
);
#案例2:返回job_id与141号员工相同,salary比143号员工多的员工 姓名,job_id 和工资
#①查询141号员工的job_id
SELECT job_id
FROM employees
WHERE employee_id = 141
#②查询143号员工的salary
SELECT salary
FROM employees
WHERE employee_id = 143
#③查询员工的姓名,job_id 和工资,要求job_id=①并且salary>②
SELECT last_name,job_id,salary
FROM employees
WHERE job_id = (
SELECT job_id
FROM employees
WHERE employee_id = 141
) AND salary>(
SELECT salary
FROM employees
WHERE employee_id = 143
);
使用having
#案例4:查询最低工资大于50号部门最低工资的部门id和其最低工资
#①查询50号部门的最低工资
SELECT MIN(salary)
FROM employees
WHERE department_id = 50
#②查询每个部门的最低工资
SELECT MIN(salary),department_id
FROM employees
GROUP BY department_id
#③ 在②基础上筛选,满足min(salary)>①
SELECT MIN(salary),department_id
FROM employees
GROUP BY department_id
HAVING MIN(salary)>(
SELECT MIN(salary)
FROM employees
WHERE department_id = 50
);
2.where后面的列子查询使用
列子查询 即子查询返回多行
需要结合多行操作符使用
多行操作符
in/not in 返回列表中的任意一个
any/some 和子查询返回的某一个值进行比较
all 和子查询返回的所有值进行查询。
USE myemployees;
#案例1:返回location_id是1400或1700的部门中的所有员工姓名
#①查询location_id是1400或1700的部门编号
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700)
#②查询员工姓名,要求部门号是①列表中的某一个
SELECT last_name
FROM employees
WHERE department_id <>ALL(
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700)
);
#《》all =in
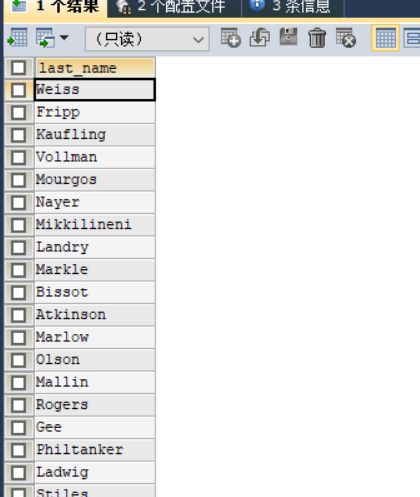
#案例2:返回其它工种中比job_id为‘IT_PROG’工种任一工资低的员工的员工号、姓名、job_id 以及salary
#①查询job_id为‘IT_PROG’部门任一工资
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
#②查询员工号、姓名、job_id 以及salary,salary<(①)的任意一个
SELECT last_name,employee_id,job_id,salary
FROM employees
WHERE salary<ANY(
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
) AND job_id<>'IT_PROG';
3.where后面的行子查询使用
子查询是一行多列或者多行多列
#案例:查询员工编号最小并且工资最高的员工信息
原始方法
#①查询最小的员工编号
SELECT MIN(employee_id)
FROM employees
#②查询最高工资
SELECT MAX(salary)
FROM employees
#③查询员工信息
SELECT *
FROM employees
WHERE employee_id=(
SELECT MIN(employee_id)
FROM employees
)AND salary=(
SELECT MAX(salary)
FROM employees
);
多行查询
USE myemployees;
#案例:查询员工编号最小并且工资最高的员工信息
SELECT MIN(employee_id),MAX(salary)
FROM employees;
SELECT *
FROM employees
WHERE (employee_id,salary)=(
SELECT MIN(employee_id),MAX(salary)
FROM employees
);
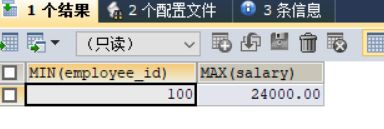

4.select后面的子查询使用
/*
仅仅支持标量子查询
*/
USE myemployees;
#案例:查询每个部门的员工个数
SELECT d.*,(
SELECT COUNT(*)
FROM employees e
WHERE e.department_id = d.`department_id`
) 个数
FROM departments d;
这一部分是个数
SELECT COUNT(*)
FROM employees e
WHERE e.department_id = d.department_id
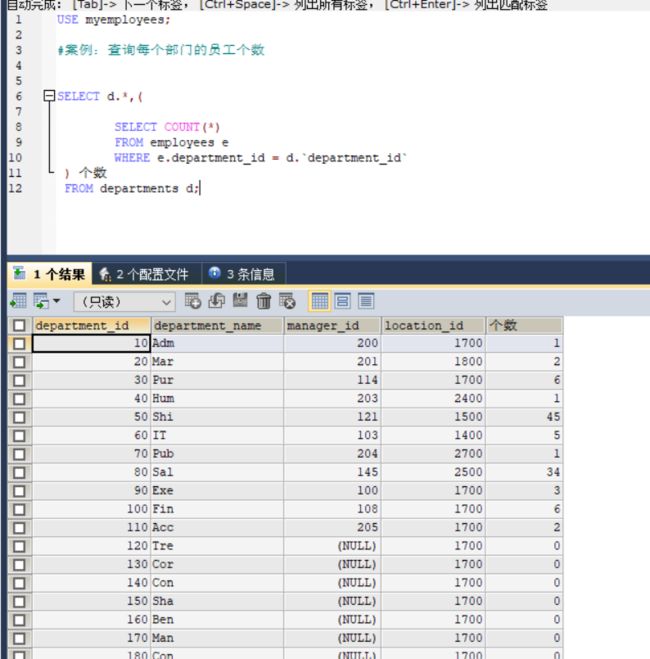
5.from后面的子查询使用
/*
将子查询结果充当一张表,要求必须起别名
*/
算例
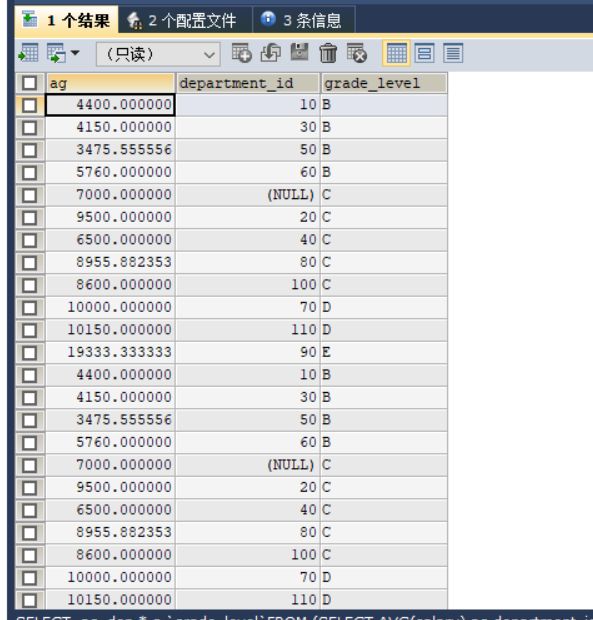
#案例:查询每个部门的平均工资的工资等级
#①查询每个部门的平均工资
SELECT AVG(salary),department_id
FROM employees
GROUP BY department_id;
得到的是每个部门的平均工资
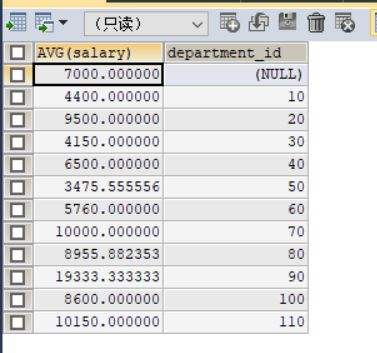
#等级表
SELECT * FROM job_grades;
等级表
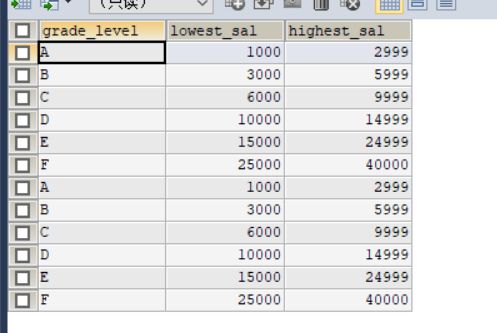
#②连接①的结果集和job_grades表,筛选条件平均工资 between lowest_sal and highest_sal
SELECT ag_dep.*,g.`grade_level`
FROM (
SELECT AVG(salary) ag,department_id
FROM employees
GROUP BY department_id
) ag_dep
INNER JOIN job_grades g
ON ag_dep.ag BETWEEN lowest_sal AND highest_sal;
注释:from 后面的是第一张表并取别名为ag_dep
INNER JOIN job_grades g 内连接 等级表,并取别名g
SELECT ag_dep.*,g.grade_level:取出第一张表的全部,第二张等级表的等级。
ON ag_dep.ag BETWEEN lowest_sal AND highest_sal; 连接条件
5.exists后面的子查询使用
/*
语法:
exists(完整的查询语句)
结果:
1或0
*/
一般来说,能用exists的都能用in查询
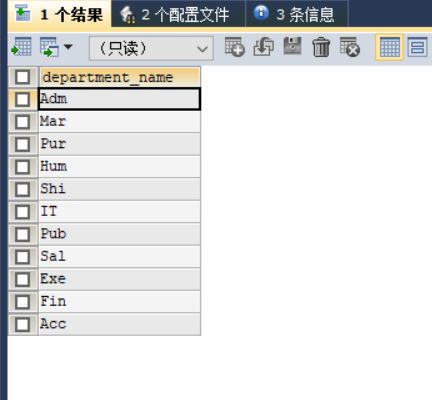
#案例1:查询有员工的部门名
使用In
SELECT department_name
FROM departments d
WHERE d.`department_id` IN(
SELECT department_id
FROM employees
)
使用exists
SELECT department_name
FROM departments d
WHERE EXISTS(
SELECT *
FROM employees e
WHERE d.`department_id`=e.`department_id`
);
四.分页查询
如淘宝 搜索内衣,内衣商品有10万条,但淘宝不是一下把10万条请求出来再分页显示。
而是一次请求1页的数据,如10条淘宝。

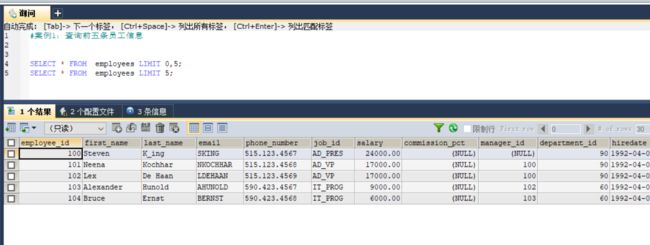
#案例1:查询前五条员工信息
SELECT * FROM employees LIMIT 0,5;
SELECT * FROM employees LIMIT 5;
#案例:有奖金的员工信息,并且工资较高的前10名显示出来
SELECT
*
FROM
employees
WHERE commission_pct IS NOT NULL
ORDER BY salary DESC
LIMIT 10 ;

五.联合查询
/*
union 联合 合并:将多条查询语句的结果合并成一个结果
语法:
查询语句1
union
查询语句2
union
…
应用场景:
要查询的结果来自于多个表,且多个表没有直接的连接关系,但查询的信息一致时
特点:★
1、要求多条查询语句的查询列数是一致的!(select 查的列一致。原始表列可以不一致。
2、要求多条查询语句的查询的每一列的类型和顺序最好一致
3、union关键字默认去重,如果使用union all 可以包含重复项
*/
#引入的案例:查询部门编号>90或邮箱包含a的员工信息
#原始方法
SELECT * FROM employees WHERE email LIKE '%a%' OR department_id>90;;
#现在
SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id>90;
总结:当条件比较少时可以用or,当条件多时推荐使用联合查询union

电气专业的计算机萌新,写博文不容易。如果你觉得本文对你有用,请点个赞支持下,谢谢。
![]()
