MySql数据库表操作:创建表、删除表、查看表、修改、查询表(详细)、设置表的字符编码
目录
1 创建表
1.1 设置表的主键
1.2 设置表的外键
2 删除表
3 查看表
4 修改表
4.1 修改表名
4.2 修改字段的数据类型
4.3 修改表的字段名
4.4 增加字段
5 查询表
5.1 带in子的查询
5.2 带BETWEEN AND的范围查询
5.3 带like的通配符匹配查询
5.4 空值查询
5.5 带AND的多条件查询
5.6 带OR的多条件插查询
5.7 去重复查询
5.8 对结果排序
5.9 分组查询
5.10 union合并查询
5.11 LIMIT分页查询
5.12 内连接查询和外连接查询
6 设置表的字符编码
表的操作是数据库中的重要内容,在此总结一下MySql数据库的表操作。
本文参考书籍《MySql入门很简单》
1 创建表
创建表的SQL语句格式如下:
CREATE TABLE 表名(属性名 数据类型 [完整性约束条件],
属性名 数据类型 [完整性约束条件],
...
属性名 数据类型 [完整性约束条件]
);
注意创建表的时候要选择合适的数据类型,而且还可以给字段添加完整性约束条件,比如主键、非空键等,完整的约束条件如下所示:
| 约束条件 |
说明 |
| PRIMARY KEY |
修饰的属性为该表的主键,可以区分不同的行记录 |
| FOREIGN KEY |
修饰的属性为该表的外键,关联了父表的主键 |
| NOT NULL |
表示该属性不能为空 |
| UNIQUE |
表示该属性的值是唯一的 |
| AUTO_INCREMENT |
MySQL特色,表示该属性是自增的,整数类型 |
| DEFAULT |
给属性设置默认值 |
1.1 设置表的主键
接下来我们来创建一个student表:
如下图所示:
![]()
如上所示,创建了一个student表,有两个属性,id,设置为主键,name设置为非空。
同时我们还可以为表设置多个主键,如下,我们创建一个表example0:

如上,通过PRIMARY KEY(属性名,属性名,……)的语法格式可以为表设置多个主键。
1.2 设置表的外键
外键是表的一个特殊字段。如果字段sno是一个表A的属性,且依赖于B的主键。那么,称表B为父表,表A为子表,sno为表A的外键。那么就可以通过sno字段将父表和子表建立关联关系。
外键的作用:设置外键的作用是建立该表与其父表的关联关系。当父表中删除某条信息时,子表中与之对应的信息也必须有相应的改变。
例如,stu_id是student表的主键,stu_id是表grade的外键。当stu_id为“123”的同学退学了,需要删除student表中该 学生的信息,那么grade表中与该学生对应的信息也应该删除。这样保证了数据的完整性和一致性。
在1.1节中,我们创建了一个表example0,其中有stu_id和courese_id,且都为主键。下面我们创建一个表example1,且将外键设置为example0表中的两个主键。
sql语句如下图:

表example1有三个属性,id为主键,stu_id和course_id为外键,fk为外键的别名,从上可以发现创建外键的语法格式为:
CONSTRAINT 外键别名 FOREIGN KEY(属性名1,属性名2,……) REFERENCES 表名(属性名1,属性名2,……)
需要注意:子表的外键关联的必须是父表的主键,而且数据类型必须保持一致。
除了设置表的主键外键外,我们还可以设置表的非空约束、表的唯一性约束、属性值自动、默认值,都非常简单,应用相应的约束性条件即可。这里不再举例。
2 删除表
删除表的时候要注意,要删除的表是一个普通的表还是一个被关联的表:
删除普通表可以直接用下面的sql语句来进行删除:
DROP TABLE 表名;
当我们要删除一个被关联的表的时候,上述的方法不再适用,用上述方法删除父表,会报错,可以自行尝试。
我们知道,表的关联是通过设置外键来实现的。但是我们用上述语句直接删除子表是没有问题的。因此我们的一种解决方案是先删除子表,再去删除父表,但是这样可会影响其他子表的数据。因此,我们可以先删除子表的外键约束,再去删除父表,从而不会影响其他表的数据。
删除表的外键约束的时候我们可以使用:ALTER TABLE 表名 DROP FOREIFN KEY 外键别名;
举例:上述中我们建立了两个表,example0为父表,example1为子表:
我们先来直接删除父表:
![]()
可以发现,直接删除父表会直接报错。
因此我们先来删除子表中的外键约束,再来删除父表:

其中fk为example1中的外键别名。再去删除父表,发现没有报错。成功。
![]()
注意:删除子表中的外键约束,比如外键为stu_id,删除之后,与父表的关联不再存在,但是子表中stu_id属性还是存在的。
3 查看表
这里的查看表指的是查看表的结构。
可以使用DESCRIBE 表名进行查看,如下:
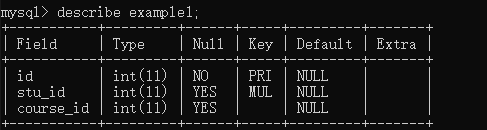
可以将,example的属性信息展示出来。
我们还可以通过语句SHOW CREATE TABLE 表名的方法将展示表的详细信息,如下:
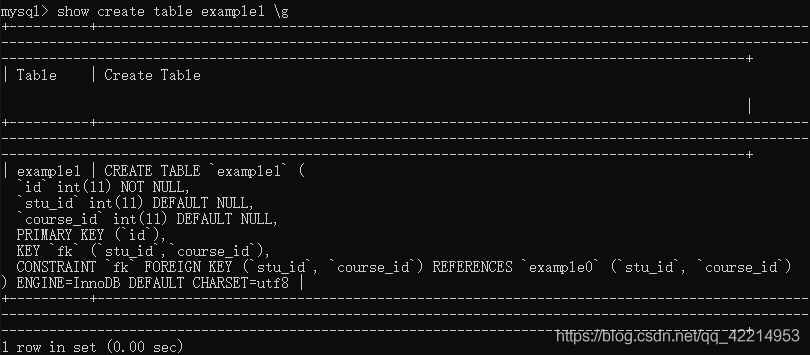
上图中通过show create table 语句展示了example1的详细信息,包括属性约束条件、主键、外键、关联信息、存储引擎和字符编码。
4 修改表
修改表主要用到的SQL语句为ALTER,同时,修改表包含许多个小部分,一一解释。
4.1 修改表名
修改表名的语法形式如下:
ALTER TABLE 旧表名 RENAME 新表名;
4.2 修改字段的数据类型
语法形式如下:
ALTER TABLE 表名 MODIFY 属性名 新属性类型;
4.3 修改表的字段名
语法形式如下:
ALTER TABLE 表名 CHANGE 旧属性名 新属性名 新数据类型;
4.4 增加字段
首先,向表中增加字段的语法格式如下:
ALTER TABLE 表名 ADD 属性名1 属性类型 [约束条件] [FIRST |AFTER 属性名2];
上述加”[]“的为可选项。
属性名1为要添加的字段名,[FIRST|AFTER 属性名]表示要添加的位置,默认为末尾,FIRST为首部添加,AFTER 属性名2:属性名2为表原有的属性名,表示将新的字段添加在属性名2之后。
一个实例:
我们现在有一个表example,结构如下:
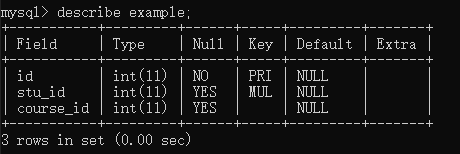
现在我们在stu_id后面添加一个name属性:

可以发现,name成功的添加在了stu_id之后。
5 查询表
表的查询操作可以说是数据库操作里面最重要的操作。
MySql的基本查询语句如下:
SELECT 属性列表
FROM 表名
[WHERE 条件表达式1]
[GROUP BY 属性名1 [HAVING 条件表达式2]]
[ORDER BY 性名2[ASC|DESC]];
其中属性名为要查询的字段名,”条件表达式1”指定查询条件;“属性名1“参数按指定该字段中的数据进行分组,”条件表达式2”参数表示满足该表达式的数据才能进行输出,“属性名2“参数指定该字段中的数据进行排序,排序方式由ASC和DESC两个参数指出,ASC表示升序,DESC表示降序。
接下来详细介绍一下常用的SQL查询,在这之前,先来建一张表,在下述难理解的查询中,用此表举例。
表名:employee

5.1 带in子的查询
语句格式为
[NOT] IN (元素1,元素2……)
如:select * from user where id in (select stu_id from grade where average>=60.0);
带in的普通查询如下所示:
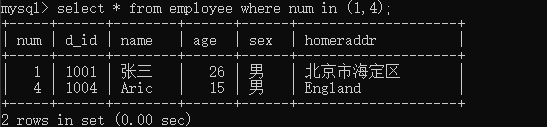
in后面根一跟集合。
5.2 带BETWEEN AND的范围查询
[NOT] BETWEEN 取值1 AND 取值2
如:select * from user where average between 80.0 and 100.0;
5.3 带like的通配符匹配查询
[NOT] LIKE '字符串'
注意此处LIKE后面的字符串可以携带通配符
% : 表示0个或任意长度的字符串
_ :只能表示单个字符
如:select * from news where content like “%亚运会%”;
5.4 空值查询
IS [NOT] NULL;
如:select * from user where b.id is NULL;
5.5 带AND的多条件查询
条件表达式1 AND 条件表达式2 [... AND 条件表达式n]
如:select * from user where average between 80.0 and 100.0 and user.sex=’男’;
5.6 带OR的多条件插查询
条件表达式1 OR 条件表达式2 [... OR 条件表达式n]
如:select * from user where grade.math>80.0 or grade.english>80.0;
5.7 去重复查询
SELECT DISTINCT 属性名
如:select distinct name from user ;
5.8 对结果排序
ORDER BY 属性名 [ASC | DESC]
如:select * from user where average between 80.0 and 100.0 order by average desc;
5.9 分组查询
GROUP BY 属性名 [HAVING 条件表达式]
对于分组排序,用前面提到的employee来进行示例。
分组查询可以将查询结果的按照某个字段或者多个字段来进行分组。字段中值相等的为一组。
当单独使用GROUP BY来分组的时侯,查询结果只显示一个分组的一条记录。
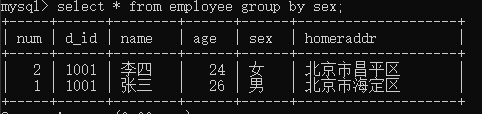
因此,GRUOP BY一般会与GROUP_CONCAT()函数、集合函数、HAVING等一起使用。
与GROUP_CONCAT()一起使用:
GROUP_CONCAT 会将每个分组中的指定字段显示出来,如下:

与集合函数一起使用:
当使用GROUP_BY的时候,我们可以通过集合函数来计算组中的总记录、最大值、最小值等。
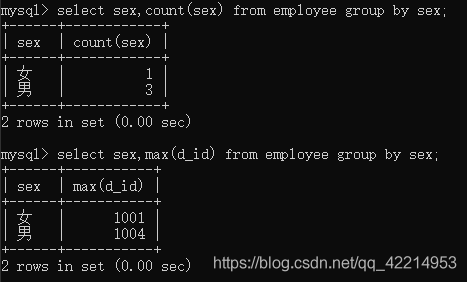
与关键字HAVING一起使用:
这个理解起来也比较直观,如下:

5.10 union合并查询
SELECT expression1, expression2, ... expression_n
FROM tables[WHERE conditions]
UNION [ALL | DISTINCT]
注意:union默认去重,不用修饰distinct,all表示显示所有重复值
SELECT expression1, expression2, ... expression_n
FROM tables[WHERE conditions];
如:SELECT country FROM Websites UNION ALL SELECT country FROM apps ORDER BY country;
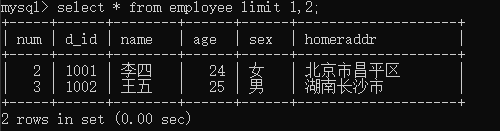
5.11 LIMIT分页查询
limt查询会查找固定数量的数据。不指定初始位置是个数是LIMIT 记录数;指定初始位置格式是LIMIT 初始位置, 记录数。
5.12 内连接查询和外连接查询
内连接查询:
SELECT a.属性名1,a.属性名2,...,b,属性名1,b.属性名2... FROM table_name1 a, table_name2 b on a.id = b.id where a.属性名 满足某些条件;
内连接查询是一种常用的连接查询。内连接查询可以查询两个或者两个以上的表。
如下我们建立一个新表:

然后使用内连接查询(对表deparment和employee):

外连接查询:
外连接查询也可以查询两个或者两个以上的表。包括左查询和右查询,语法如下:

左连接查询:

查询结果共显示了四条记录。这四条条记录的数据是从employee表和department表中取出来的。因为employee表和department表中都包含d_id值为1001he 1002的记录,所以这些记录都能查出来。因为department表中没有d_id等于1004记录,所以该记录只能从表employee中取出来,而对应的需要从deparment表中取出来的值都是空值。
右连接查询:

查询结果也显示了4条记录。因为employee表和department表中都包含了d_id值为1001和1002的记录,所以这些记录能查出来。但是查询结果中比内查询多出1003的记录。因为employee表中没有d_id等于1003的记录,所以该记录只能从department表中取除了相应的值。而对应的需要从employee表中取出的值都是空值。
通过上述例子,想必都可以明白左连接查询和有链接查询的不同。
我们一般都会用连接查询代替in子查询进行多表联合查询,子查询的效率远不及连接查询效率高!
6 设置表的字符编码
有时候MySQL中的表需要存储中文,需要设置表的字符编码为utf8,否则默认的字符编码有可能不能正确处理中文,那么在MySQL中,如何设置表的字符编码呢?如下:
通过命令查看MySQL表的字符编码,如下:
mysql> show variables like 'charac%';
+--------------------------+---------------------------------------------------------+
| Variable_name | Value |
+--------------------------+---------------------------------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 需要设置! |
| character_set_system | utf8 |
| character_sets_dir | C:\Program Files\MySQL\MySQL Server 5.7\share\charsets\ |
+--------------------------+---------------------------------------------------------+
如下设置:
mysql> set character_set_server=utf8;
Query OK, 0 rows affected (0.00 sec)
字符编码设置utf8成功,MySQL的status运行状态和运行参数都是通过全局变量来控制的,用show status和show variables两个命令可以查看这些信息,用set可以设置这些信息,改变配置。