【论文系列】读《SeqSLAM: Visual Route-Based Navigation for Sunny Summer Days and Stormy Winter Nights》
SeqSLAM: Visual Route-Based Navigation for Sunny Summer Days and Stormy Winter Nights
SeqSLAM 是2012年两位澳大利亚的IEEE fellow提出来的,Michael J. Milford, Member, IEEE, Gordon. F. Wyeth, Member, IEEE。是当时第一个在极端环境变化下还能实现的基于视觉的定位系统,"this is the first time vision-based localization has been demonstrated across extreme environmental change."
这篇文章的核心思想就是 大家都用基于特征来做,那么好,我就不用基于特征来做,我要基于图像序列,也就是所说的“sequence-based”。原因主要是因为SLAM需要在季节变换、日夜不同情况下都能具有识别同一场景的能力,而特征方法当时效果还不足以完成,尤其是特征主要还是选用的人工特征,比如SIFT/SURF(因为现在已经有文章证明了深度学习的特征在那些急剧变化的环境情况下也有好的表现,足够多,暂不举例。)所以作者也用了当时的FAB-MAP来做对比试验,证明其效果。
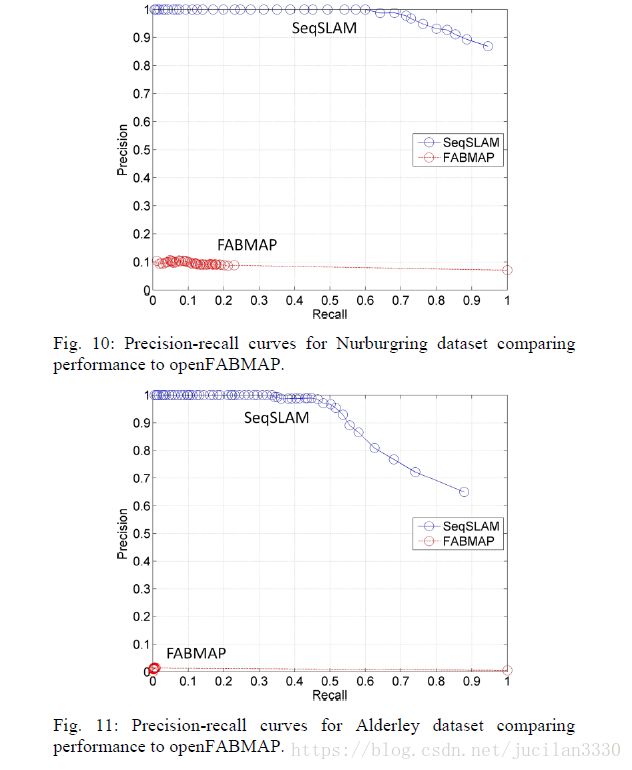
图1 SeqSLAM在当时666 的效果图
SeqSLAM的提出应该是里程碑式的吧,不管是思路还是结果,不管是从论文引用还是后续顶会(最新17年ICAR的Fast-SeqSLAM: A Fast Appearance Based Place Recognition Algorithm)中对于这个系统的继续研究,该文的核心思想在摘要和引言中都出现了,而且只字未改,此处也给出原文:
“our approach calculates the best candidate matching location within every local navigation sequence. Localization is then achieved by recognizing coherent sequences of these “local best matches”.
接下来讲到该文用到的两个部分
A.Local Best Match
 图2 shows a schematic of the local contrast enhancement process operating on a number of Dˆ vectors calculated at different times.
图2 shows a schematic of the local contrast enhancement process operating on a number of Dˆ vectors calculated at different times.
由图2可见,也由前面的核心思想所述。作者将图像识别问题不再当做在全局中找一个唯一最匹配的template(候选帧),而是在每一个局部邻域中都找一个和当前图像最匹配的template,这样就有了一个templates合集,也就是上图最左边的一组图像。然后对图像差矢量D的每一个template 元素 , 都要进行一个局部对比增强处理(作者告诉我们这就是和一维版本的块正则化差不多)。下面是公式:
, 都要进行一个局部对比增强处理(作者告诉我们这就是和一维版本的块正则化差不多)。下面是公式:![]() 代表的是平均值,
代表的是平均值,![]() 标准差。
标准差。
![]()
公式的结果是加强了对比的图像差异度矢量
B.Localized Sequence Recognition
因为每一步中局部的template匹配会产生很多的候选template匹配,这些template之间也有较高的相似度。所以为了识别出相似的位置序列,手选定了一个空间M,M是由前面的图像差异度组成的。
ds意味着已经搜索了多远,T意味着现在的时间。这里作者做出了一个假想:“that velocities (in terms of templates learned per second) on repeated traverses of a path are approximately repeatable (within 40% for these experiments).”重复穿越路径的速度也近似重复。
这个搜索主要是投影了大量的轨迹线,来表现源自的可能的不同的速度。
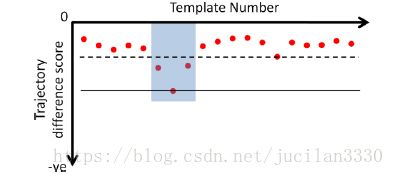
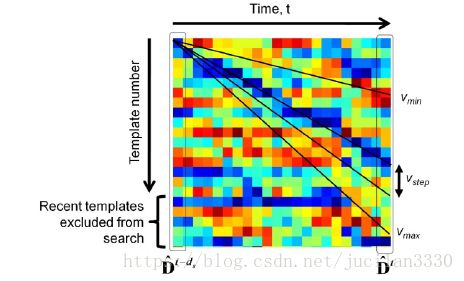 图3 显示了源自单一template的不同速度轨迹线
图3 显示了源自单一template的不同速度轨迹线
这里,我们定义从T-ds到T时间段t内的每一个轨迹的差异性分数S(像不像相似性分数的概念),接下来我们会用这个分数做匹配。 轨迹搜索会在 除了在当前的template的R recent 中最近学习到的templates之外的 每一个template上进行搜索。
S的定义:

k意味着轨迹在t时刻穿过是的精确差异值。
s意味着其中s是轨迹起始的模板号,V是以Vstep为步长的Vmin和Vmax之间的轨迹速度。
有了S这个关键的评判标准,我们进行下一步的learned templates队伍扩充。在所有的S被计算完之后,最小分数的S所用的每一个template都会被放置在矢量S中,(此S非彼分数S,加入之后的结果请看图3最左一栏)
最后,如果滑动窗口R内的最小分数是比其他的窗外的轨迹分数都要小的μ的因子。那么认为该轨迹是一个匹配。闭环检测完成。
实验部分不再分析。
参考文献 SeqSLAM: Visual Route-Based Navigation for Sunny Summer Days and Stormy Winter Nights. Michael J. Milford, Member, IEEE, Gordon. F. Wyeth, Member, IEEE