【论文系列】光流/ LK光流/ FlowNet/ FlowNet2
今天重点介绍光流
首先介绍光流的idea inspiration,传统光流的估计方法,再介绍用CNN解决光流的思路--FlowNet以及FlowNet2(个人认为只是利用stack方式堆叠FlowNetS和FlowNetC,其中更出彩的可能在数据集与更适应的数据训练方法,当然,精度和速度的效果也更为出色,解决了小displacement的估计)。Let's START!
光流
第一次读光流的文章是很久以前,当时有个印象很深的例子,就是当你坐火车的时候往窗外开,原本固定的刚体的物体,由于相对参考系的运动,仿佛变成了一条条川流的线,如同光在流动。而且,不同距离的物体,例如近处的相邻铁轨,远处的天和云,不远处的房屋,其运动的速度不是完全一样的,也就是说,我们可以通过不同的视觉感觉速度,而判断这个物体的远近。
光流(optical flow)最早在1940s由Gibson的The Perception of the Visual World.提出的,其定义是,由物体/相机的运动引起的在连续帧之间的视在运动模式。它是一个矢量2D场,每个矢量是一个位移矢量,代表点从第一帧到第二帧的运动。
-
光流需要满足的条件假设:
-
物体的像素强度在连续帧之间不会改变
-
相邻像素间有相似的运动
---------------------------------------------------
推导:

考虑在第一帧的像素点![]() ,
, ![]() 为在下一帧中的运动的位移,所以该点经过运动后在第二帧为
为在下一帧中的运动的位移,所以该点经过运动后在第二帧为![]() 。考虑到假设条件一,“物体的像素强度在连续帧之间不会改变”,有:
。考虑到假设条件一,“物体的像素强度在连续帧之间不会改变”,有:
![]()
将,![]() 泰勒展开:
泰勒展开:
![]()
故有:
其中![]() ,各代表其在x y方向的运动速度,可以看成 u,v。
,各代表其在x y方向的运动速度,可以看成 u,v。![]()
这样 我们就得到了光流方程
![]()
在这个光流方程中![]() 代表的是图像在(x ,y,t )这一点的梯度,
代表的是图像在(x ,y,t )这一点的梯度,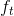 是两帧图像块之间差值,均为已知。我们需要求解的u,v,那么如何求解呢?这里引入L-K光流法和L-K金字塔光流法。
是两帧图像块之间差值,均为已知。我们需要求解的u,v,那么如何求解呢?这里引入L-K光流法和L-K金字塔光流法。
L-K光流法
-------------------------------------------
-
稀疏光流法: L-K光流
利用L-K法解决光流,充分利用了光流的第二个假设条件,即,相邻像素间有相似的运动。需要注意的是,L-K光流法解决的是小位移情况,所以后文将会介绍L-K金字塔光流法来搞定大位移的光流问题。
由光流方程我们可知,现需求解两个未知数u&v。
L-K方法是找一个3*3的patch,利用相邻像素间有相似的运动,所以假定这九个点都有相同的位移。这样我们就可以得到方程组:
九个方程解两个未知数,超定,可以用最小二乘法来得出近似解。![]()
由此,我们解得x,但是观察
![]() ,并不一定总是可逆的!(充要条件
,并不一定总是可逆的!(充要条件![]() )
)
在图像中沿着两个方向都有像素变化的区域(角点,这个式子也很像harris corner的响应式),一般对应的![]() 是可逆的,但是对于在灰度变化很小的区域,一般
是可逆的,但是对于在灰度变化很小的区域,一般![]() 是不可逆的。这限制了LK光流法的适用范围,所以我们称之为稀疏光流法(并不是所有光流都能被计算出来)
是不可逆的。这限制了LK光流法的适用范围,所以我们称之为稀疏光流法(并不是所有光流都能被计算出来)
在光流跟踪中,由于可逆的充要条件![]() ,也就是要求,矩阵G的最小特征值要足够大,满足这个要求的像素点才易于光流跟踪。)
,也就是要求,矩阵G的最小特征值要足够大,满足这个要求的像素点才易于光流跟踪。)
-------------------------------------------
-
稠密光流法:迭代求解L-K光流
这里对上面的证明,再重新梳理一遍,并用迭代的方式求解光流d;连续帧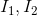 ,对于
,对于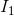 中的像素点
中的像素点![]() ,需要在
,需要在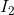 中找到其对应的像素点
中找到其对应的像素点![]() ,使得其灰度值差别最小(光流假设条件一:物体的像素强度在连续帧之间不会改变)。我们把图像在
,使得其灰度值差别最小(光流假设条件一:物体的像素强度在连续帧之间不会改变)。我们把图像在![]() 处的运动位移
处的运动位移 ![]() 称之为在a处的光流。又由条件二知道,相邻像素间光流相同,引入大小为
称之为在a处的光流。又由条件二知道,相邻像素间光流相同,引入大小为![]() 的相同光流邻域。
的相同光流邻域。
则求解 转换为使下述目标函数的最小值优化为题:
转换为使下述目标函数的最小值优化为题:

一般来说,如果![]() 是一个数学形式很简单的函数,可以用解析形式来求——令目标函数的导数为0:
是一个数学形式很简单的函数,可以用解析形式来求——令目标函数的导数为0:
将![]() 一阶泰勒展开,得到:
一阶泰勒展开,得到:
由于![]() 足够小,有
足够小,有![]() ,且令
,且令![]() ,
, ![]() ,则有:
,则有:

又![]() 为标量,有
为标量,有
再令
因为我们最终是求得在使得导数=0下d的值,![]() 。现在以迭代方式求解:
。现在以迭代方式求解:
 代表迭代次数(
代表迭代次数(![]() ),对于第k次迭代,
),对于第k次迭代,![]() ,第k-1次迭代已经提供了初始值
,第k-1次迭代已经提供了初始值 ![]() 并把该值作为图像
并把该值作为图像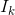 处的运动位移初始值,移动后的点落在图像
处的运动位移初始值,移动后的点落在图像![]() ,则有
,则有![]() ,之后重复之前推导的内容:
,之后重复之前推导的内容:![]() ,使得下面的目标函数最小:
,使得下面的目标函数最小:
最终可以得到![]() (*这里的G在迭代计算中始终保持不变,
(*这里的G在迭代计算中始终保持不变, )而
)而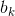 每次需要重新计算。
每次需要重新计算。
第k次迭代的结果![]() 。当迭代次数达到设定次数,或者计算得到的
。当迭代次数达到设定次数,或者计算得到的![]() 达到阈值,迭代计算结束。
达到阈值,迭代计算结束。
-
金字塔光流法

我们知道L-K光流法中的几个假设都是强假设,当连续帧物体的运动位移较大(运动速度较快时)算法误差较大,如何解决?缩小图像尺寸,我们就可以使得运动像素变小。金字塔分层解决光流方法应用而生。简答来说,上层金字塔(低分辨率)图像中的一个像素可以代表下层的两个像素。利用金字塔的结构,可以自上而下修正光流运动位移。
步骤:
-
1.金字塔建立。首先,对两帧建立高斯金字塔,最低分辨率图在最顶层,原始图片在底层:
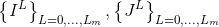 。为了保证每层分解得到的图像尺寸都是整数,所以需要在正式处理之前,通过resize对原图像(包括前后两帧图像)的尺寸进行调整。
。为了保证每层分解得到的图像尺寸都是整数,所以需要在正式处理之前,通过resize对原图像(包括前后两帧图像)的尺寸进行调整。
图像的金字塔化包括两个步骤:
①利用低通滤波器(lowpass filter)平滑图像。
防止图像降采样后发生锯齿现象。一般使用高斯滤波器,所以也称高斯金字塔![]()
②对平滑图像进行抽样,从而得到一系列尺寸缩小的图像
可以对原始图像调整宽高以满足整除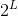 ,也可以用公式确定新图像的宽高:
,也可以用公式确定新图像的宽高:![]() 。
。![]() 代表第L层图像的宽和高。
代表第L层图像的宽和高。

- 2.计算每层图像的光流,先计算顶层光流,从顶层(Lm层)开始,对于每一层L,通过最小化每个点的领域范围内的匹配误差和,得到顶层图像中每个点的光流。(g为上一层传递的初始值,d为光流位移与初始值的残差,即g+d=光流)
最小化该式→:
具体步骤如下:
①计算对于当前图像![]() 中像素点u对应的位置:
中像素点u对应的位置:![]() (图像缩放1/2)。
(图像缩放1/2)。
②计算图像![]() 在x方向的梯度:
在x方向的梯度:![]()
③计算图像![]() 在y方向的梯度:
在y方向的梯度:![]()
④计算空间矩阵G:
⑤迭代获取LK初始值g,最顶层的光流估计值设为0,![]() ,其余层的光流估计值为:
,其余层的光流估计值为:![]()
⑥计算图像差异:
⑦计算残差向量 ![]() 。
。
⑧计算光流:![]() ,第L层的光流优化值
,第L层的光流优化值![]()
⑨提供下一层的光流计算的初始值,
![]() 。
。
(假设图像的尺寸每次缩放为原来的1/2。共缩放了Lm层,第0层为原图。设已知原图的位移为d,则每层的位移为:![]() )
)
- 反馈直到底层(准确值=估计值+残差)
![]()
其实可以看出,最终的光流值,就是所哟偶层的分段光流d的叠加:

-
最终得到图像J中的点坐标
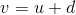 。
。
光流金字塔实际操作中一些需要注意的点:
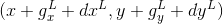 往往不是整数坐标,需要双线性插值。
往往不是整数坐标,需要双线性插值。- 滤波、求梯度时,需要注意图像边界处的像素点的关于像素越界的处理
- v的坐标在J图像外被判定为错误点,但当v在J内时,匹配也不一定正确,需要滤除该方法计算得到的误匹配,常用解决方案是基于RANSAC计算两帧图像的变换矩阵。
至此,三个点推下来,相信你已经对光流有了比较深刻的理解了,接下来,我们将看如何利用CNN解决光流问题。
FlowNet
------------------------------------
- 文章下载地址:http://lmb.informatik.uni-freiburg.de/Publications/2015/DFIB15/
- 实现代码地址:http://lmb.informatik.uni-freiburg.de/resources/binaries/
FlowNet,开创了利用CNN来进行光流估计的先河。光流估计需要的两个条件:“needs precise per-pixel localization”,“requires finding correspondences between two input images”指向了利用CNN解决光流会面临的问题——要学习一个什么样的特征表达 和 如何匹配两图之间不同位置上的特征。作者提出的大致思路如下图所示:

首先,用两张图片作为输入,利用一个收缩部分(contracting part)压缩可用的信息,然后再利用一个放大部分(expanding part)将图像和光流特征图都恢复到full image resolution级别。并且在收缩部分,作者提出了两种网络结构FlowNetS(imple) 和FlowNetC(orrelation),其区别在于FlowNetC中加入了一个新层——correlation layers——用来进行patch之间的乘性匹配(每两个patch都要一一匹配,后文细说),这个显式关联层,可以利用多层级多尺度和抽象的能力去学习强的特征来匹配(在FlowNet中没有完全发挥它的作用,是数据集和训练策略的问题,FlowNet2有提到,并且有更好地应用FlowNetC)。
-
网络结构
作者采用端到端的训练方式,整个网络结构中只用卷积层联系起来(读了上篇pooling博文的同学知道,没有连接层,就不用在意图片的输入大小。)在contracting part使用了池化操作使得计算更简单,网络不容易过拟合并且能够在输入图像大区域地聚集信息。但是Pooling会让网络分辨率降低,所以作者又加入了expanding part来refine收缩结果使得光流map最终可以以一个高像素图呈现。
-
收缩部分
收缩部分提出两个框架——FlowNetSimple 和 FlowNet Corr
- FlowNetS

FlowNetS的思路很简单,我们就套用CNN在学习输入输出关系上很擅长的优点:我把一对图片的通道连接起来,网络结构图中可以看到输入的data层的channel是6输入,让网络自己去学习怎样处理图像对来获得光流移动信息,如上图所示,没有其他的多余操作。
整个收缩部分FlowNetS一共有九个卷积层,其中的六个stride(步长)为2。每一层后还有一个非线性的ReLU操作。卷积操作的filter大小随着网络的深入而递减。
- FlowNetC

第二种方法是,将两张图片分开,两张图片经过同样的处理进行特征提取(我个人把卷积当做一个特征提取的过程),得到各自的feature map,再通过correlation layer使得这两张特征图在更高的特征级别(卷积后)上联系(匹配),再继续进行特征提取。整个过程就像图像匹配——提取特征+匹配特征,这里作者的匹配特征应用的方式是the correlation layers。
- The correlation layers

既然要匹配“特征”了,那就是找最像的过程(别忘了光流的假设条件一:物体的像素强度在连续帧之间不会改变,所以找到最像像素的点对,motion就有了)。FlowNet作者的想法是,那我就把所有patch的对比结果都拿来做个map吧,继续在这个map上学习,我就能学到光流的。于是作者就先提出一个correlation(patchs相关性定义):

描述一下这个公式,x1,x2是两张图的两个patch的中心坐标,二维,![]() 。
。![]() 各自代表图像卷积后的feature map。每个patch的大小为K=2k+1,所以整个公式类似卷积核在图片上的卷积:以x1为中心的patch和以x2为中心的patch,对应位置相乘然后相加,但它的weight不可训练。
各自代表图像卷积后的feature map。每个patch的大小为K=2k+1,所以整个公式类似卷积核在图片上的卷积:以x1为中心的patch和以x2为中心的patch,对应位置相乘然后相加,但它的weight不可训练。
到这里,大家就会觉得如果两两patch都要算,会不会太麻烦?两块之间c*K*K的复杂度,考虑到光流本身是有一定的范围的,所以作者用两个小tips来解决计算的问题:
- 我假定光流是有最大displacement的,设定一个最大displacement范围d,超出x1中心d范围的patch,我不再做correlation比较。
- 加一个步长,s1和s2分别针对x1和x2,不用D范围(D=2d+1)都去进行计算。
于是乎,计算量得到减小,从correlation layers出来的结果维度为![]() 。
。
![]()
-
放大部分

放大部分主要由“upconvolutional layers”组成,主要进行unpooling和convolution操作。整个refinement过程如上图所示:作者在feature map上做反卷积(绿色箭头),同时将由收缩部分得到的feature map(灰色箭头)以及上采样得到的光流粗预测结果(红色箭头)连接起来(如果有的话)进行新的光流预测。每一步提升两倍的分辨率,重复四次,预测出来的光流的分辨率是输入图片的分辨率的1/4。如果想要继续提升分辨率,双线性插值没有什么明显地提升,可以用variational refinement。
至此,网络结构大概就已经被梳理好了,具体的其他细节,可以对照原文查看。
--------------------------------------------------------
- 数据集制作
这是本文的第二个贡献,作者通过拼接前景和背景制造的仿真数据集Flying Chairs使得网络能够有充分数据进行训练。具体做法、考量内容,本文不关注。此外,作者也比较了其他几个光流数据集的光流类型,数据集特点,有兴趣可以详读。
- 评价指标
EPE是一种对光流预测错误率的一种评估方式,代表所有像素点的gound truth和预测出来的光流之间差别距离(欧氏距离)的平均值,越低越好。
- 数据集表现:
- Sintel Clean : FlowNetC比FlowNetS要好。
- Sintel Final:FlowNetS比FlowNetC要好。
- Flyingchair:Flownet优于其他方法,FlowNetC比FlowNetS要好:
- Kitti:Flownet表现一般,FlowNetS比FlowNetC要好。
- FlowNetC比FlowNetS比较
数据集的表现上各有千秋,但是FlowNetC有过拟合的问题所以才导致有些数据集上的表现不够好。(可以继续看在FlowNet2上如何进行训练的改进。)相比FlowNetS,FlowNetC应该可以在真实数据集上有更好的表现,所以坚信C网络在保存信息上的优势,加以更丰富的数据和合理的训练方法,可以得到更好的结果。
因为我们在计算correlation的时候,为了减少计算的复杂度,所以我们设立了max displacement d,这使得,有一些超出d范围的光流motion没能被很好地学习以及在数据集中被测试出来,所以FlowNetC在large displacement上的表现比FlowNetS要差,比如在kitti数据集上,动态物体多,displacement大。
- 本文贡献:
- CNN预测光流先河。虽然我们也能大概感觉到,作为第一个利用CNN解决光流的工作,作者的思路可以算是尝试性的(但一定尝试了多种方法),FlowNetS结构如其名的simple..C相比S添加了correlation layers。所以我相信在利用深度学习方面一定有更好的网络结构和切入点来解决光流问题,只是大家暂时被障目所以暂时还没有找到...
- FlyingChairs数据集。数据集真的是个好东西,深度学习上数据集多重要就不说了,自己的数据集还能够很好地说明你的实验效果,能够多加引用...当然制作起来也是...比较耗费精力。
FlowNet2
接下来进入FlowNet2的世界。
横空出世的FlowNet,证明了的确可以用CNN完成对光流的估计,然而,对于small displacement问题和在真实数据集上的表现,FlowNet要逊色于传统方法。FlowNet的不足,是有原因的:例如对训练数据的需求,例如没有充分发挥FlowNetC中显式关联层correlation layers的作用,例如训练策略是否存在一些不足?可不可以结合FlowNetS和FlowNetC?这里,FlowNet2更关注训练数据和训练策略,为解决FlowNet的不足给出了答案。
-
依据摘要,文章的主要贡献有三:
- 本文提出了新的训练策略和新的训练数据。并且实验证明,这些的确可以影响实验结果。作者首先是发现如果单独使用越复杂的数据,将导致越差的结果。然后作者还发现,多个数据集的训练策略可以显著提高实验结果,使得correlation layer真正派上用场。
- 作者将FlowNetC和FlowNetS进行堆叠而得到新的网络 instead of promoting a new architecture, 。并且在网络中,对第二帧图像施加warp操作,使得localization更精确。并非通过调节stack的深度和单个成分的大小,得到许多网络变种来控制网络精度和计算资源中的平衡,速度范围在8fps~140fps。
- 提出一个专治small displacement的子网络和数据集,弥补上一版的不足。基于此数据集的特定网络只是对于真实世界中小运动有着良好的效果。为了对于任意位移都能达到最佳的性能,添加了一个网络来融合前面堆叠网络和小位移网络。
FlowNet2继承了FlowNet的优点:large displacement上表现很好(传统方法的劣势),光流域里的极小细节也能正确估计,还有对于特定场景里学习先验的潜力和运行速度快。同时,还能搞定small displacement和光流噪声问题,加速real-world中的应用发展。上个对比图,更清晰的边界,更平滑的结果。

- 数据集策略
1.数据集质量要高,这是监督训练成功的关键。
2.不同属性的训练的数据的出场顺序也很重要。
如此一来,FlowNetC比FlowNetS效果要好。最好的训练效果的顺序和数据集是:先在Chairs数据集上训练,然后仔仔Things3D上fine-tuning。
本文的三个学习率训练策略:

不同的学习率训练策略+不同的数据集训练顺序得出的不同结果:

--------------------------------------------------------
-
Stacking Networks

- 1.Stacking Two Networks for Flow Refinement堆叠两个网络:
输入两张图片只用FlowNetS网络堆叠,添加warp或不添加warp。
得到如下观察:
1)如果只堆叠网络不warp,堆叠网络易过拟合,在Sintel数据集上结果更差
2)stack和warp同时使用比较好。warp的确可以提高精度
3)Net1层加intermediate loss效果更好
4)固定第一个网络在warp操作之后训练第二个网络可以得到最佳的结果。
堆叠网络大小是原始网络的两倍,易过拟合。解决办法是网络一个接一个的训练。
实验结果如下

- 2.Stacking Multiply Diverse Networks堆叠不同种网络:FlowNetS+FlowNetC
这一节主要是进行不同种类和大小的网络的堆叠。设第一个网络为bootstrap网络,第二个网络用不同权重的新网络(运行时间上不会增加,但训练资源会增加)。这种情况下,作者认为顶层网络,可以在不同的步骤中表征不同的任务——这样,通过固定现有网络再一个接一个的添加新网络,stack针对某一任务就可以在更小的数据集上训练了。
同时,可以通过对通道数的减少从而对网络进行精简,最佳精简的尺寸是3/8。用大小写来区分网络中到底用了多少通道数。CSS比C要好,通道数更少网络参数少,速度快。
 3/8的来历
3/8的来历

---------------------------------------------
- Small displacement network
作者想要捕获小运动的同时不丢失大运动→但是亚像素级motion上,噪声影响了光流的估计。→这是FlowNet本身的结构固有问题造成的→作者设计了网络图中右下角的FlowNet-SD,用以下改进解决:
-
修改filter的大小,7*7,5*5都用成3*3,更小,更平滑。
-
FlowNetS的第一层的stride=2变为1
-
在上采样前加了卷积层用了平滑噪声
-
重新做了数据集ChairsSDHom
-----------------------------------------------
- 最后的一些实验结果



做完这些总结之后,再回头看,并没有觉得FlowNet有多惊艳,但是第一个就是第一个,开天辟地,FlowNet2更像一篇工程性的文章,这里修修,那里改改,堆叠网络,做各种实验,隔了几年之后的FlowNet2,效果的确很好,背后的工作和努力肯定是值得人肯定的,但我还是坚信...光流有更合适的其他深度学习网络结构可以解决....卷积只是在做类似金字塔的工作,但是你有足够的数据量可以学习,金字塔不能保存这个权重信息,切入点暂时也没想法,期待未来读到更惊艳的文章吧!
参考博客:
- https://my.oschina.net/u/3702502/blog/1815343
- Mega_Li 的博客 https://blog.csdn.net/lwx309025167/article/details/80012199?utm_source=blogxgwz0
- FlowNet——爆米花好美啊 的博客 https://blog.csdn.net/u013010889/article/details/71189271
- FlowNet2——lvhhh 的博客 https://blog.csdn.net/lvhao92/article/details/72899761
- FlowNet2——bea_tree 的博客https://blog.csdn.net/bea_tree/article/details/67049373