开始前的准备工作:
MySQL下载:点我
python MySQL驱动下载:pymysql(pyMySql,直接用pip方式安装)
全部安装好之后,我们来熟悉一下pymysql模块
import pymysql
#创建链接对象
connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='1234', db='python')
#创建游标 游标用来进行查询,修改等操作
cursor = connection.cursor()
#定义sql语句 这里的sql语法根据使用的数据库不同会有一些小差别
sql = "SELECT * FROM python.text_info where text_title='test'"
#执行sql语句 返回受到影响的行数
cursor.execute(sql)
#获取sql语句执行后的返回数据 默认返回的数据类型为元组
#获取所有返回
r = cursor.fetchall()
#获取一个返回
r = cursor.fetchone()
#获取至多三个返回 不足三个时返回所有
r = cursor.fetchmany(3)
#其他的fetch方法可自行百度
#将返回数据类型改为字典
cursor = connection.cursor(cursor=pymysql.cursors.DictCursor)
#或者在创建连接对象时指定返回数据类型为字典 建议把返回类型修改为字典类型
connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='1234', db='python', cursorclass=pymysql.cursors.DictCursor)
#保存所做的修改 在连接关闭之前,如果你没有调用下面的语句
#那么,你之前的所有修改将不会被保存
connection.commit()
#关闭游标
cursor.close()
#关闭连接
connection.close()
一、确定items
我们要爬取的网站是:http://m.50zw.la
要爬取的是小说的信息,如图:
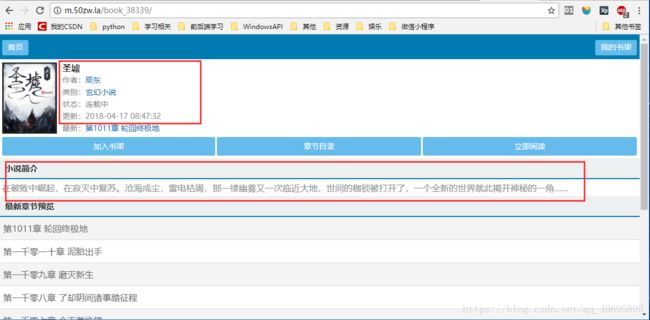
所以items.py文件如下:
import scrapy
class TextInfoItem(scrapy.Item):
# name = scrapy.Field()
text_name = scrapy.Field()
text_author = scrapy.Field()
text_type = scrapy.Field()
text_status = scrapy.Field()
text_latest = scrapy.Field()
text_intro = scrapy.Field()
最后信息是要储存到数据库里的,所以我们还得创建一个数据库表。
- 第一步:在开始菜单里找到MySQL Workbench,双击打开。MySQL Workbench是MySQL自带的一个可视化管理工具
- 第二步:在 MySQL Workbench里连接数据库,并创建一个数据库 python,然后再在刚刚创建的数据库里创建一个表 text_info
- 第三步:在 text_info表里逐一添加 text_name,text_author 等属性,类型全部设置为 varchar,大小除了 text_intro是 1000外,其他的全部设置为 50
MySQL的使用就不详细讲了。如果遇到问题,欢迎评论留言。
二、爬取信息
为了简单,我们只爬取 50zw网站下的玄幻分类的小说信息。
细节前面已经讲过了,这里不再多讲,有不懂的可以去看前面的几篇文章。
废话不多说,直接上代码:
import scrapy
from text_info.items import TextInfoItem
class A50zwSpider(scrapy.Spider):
name = '50zw'
allowed_domains = ['m.50zw.la']
start_urls = ['http://m.50zw.la/wapsort/1_1.html']
#主站链接 用来拼接
base_site = 'http://m.50zw.la'
def parse(self, response):
book_urls = response.xpath('//table[@class="list-item"]//a/@href').extract()
for book_url in book_urls:
url = self.base_site + book_url
yield scrapy.Request(url, callback=self.getInfo)
#获取下一页
next_page_url = self.base_site + response.xpath('//table[@class="page-book"]//a[contains(text(),"下一页")]/@href').extract()[0]
yield scrapy.Request(next_page_url, callback=self.parse)
def getInfo(self, response):
item = TextInfoItem()
#提取信息
item['text_id'] = response.url.split('_')[1].replace('/', '')
item['text_name'] = response.xpath('//table[1]//p/strong/text()').extract()[0]
item['text_author'] = response.xpath('//table[1]//p/a/text()').extract()[0]
item['text_type'] = response.xpath('//table[1]//p/a/text()').extract()[1]
item['text_status'] = response.xpath('//table[1]//p/text()').extract()[2][3:]
item['text_latest'] = response.xpath('//table[1]//p[5]/text()').extract()[0][3:]
item['text_intro'] = response.xpath('//div[@class="intro"]/text()').extract()[0]
yield item
这里我们通过 yield 来发起一个请求,并通过 callback 参数为这个请求添加回调函数,在请求完成之后会将响应作为参数传递给回调函数。
scrapy框架会根据 yield 返回的实例类型来执行不同的操作,如果是 scrapy.Request 对象,scrapy框架会去获得该对象指向的链接并在请求完成后调用该对象的回调函数。
如果是 scrapy.Item 对象,scrapy框架会将这个对象传递给 pipelines.py做进一步处理。
这里我们有三个地方使用了 yield ,第一个地方是:
for book_url in book_urls:
url = self.base_site + book_url
yield scrapy.Request(url, callback=self.getInfo)
这里我们在循环里不断提取小说详细页面的链接,并通过 yield 来发起请求,并且还将函数 getInfo 作为回调函数来从响应中提取所需的数据。
第二个地方是:
#获取下一页
next_page_url = self.base_site + response.xpath('//table[@class="page-book"]//a[contains(text(),"下一页")]/@href').extract()[0]
yield scrapy.Request(next_page_url, callback=self.parse)
这里是在爬取完一页的信息后,我们在当前页面获取到了下一页的链接,然后通过 yield 发起请求,并且将 parse 自己作为回调函数来处理下一页的响应。
这有点像递归,不过递归是函数自己调用自己,这里看起来好像是 parse 调用了自己,但实际上 parse 是由 scrapy框架在获得响应后调用的。
最后一处使用了 yield 的地方在 getInfo 函数里:
def getInfo(self, response):
item = TextInfoItem()
... ...
item['text_intro'] = response.xpath('//div[@class="intro"]/text()').extract()[0]
yield item
这里我们通过 yield 返回的不是 Request 对象,而是一个 TextInfoItem 对象。
scrap有框架获得这个对象之后,会将这个对象传递给 pipelines.py来做进一步处理。
我们将在 pipelines.py里将传递过来的 scrapy.Item 对象保存到数据库里去。
三、将信息插入数据库
python对数据库的操作很简单,我们简单了解一下步骤:
- 建立数据库连接
- 创建操作游标
- 写sql语句
- 执行sql语句
- 如果执行的是查询语句,则用fetch语句获取查询结果
- 如果执行的是插入、删除等对数据库造成了影响的sql语句,还需要执行commit保存修改
贴上代码:
import pymysql
class TextInfoPipeline(object):
def __init__(self):
#建立数据库连接
self.connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='1234', db='python',charset='utf8')
#创建操作游标
self.cursor = self.connection.cursor()
def process_item(self, item, spider):
#定义sql语句
sql = "INSERT INTO `python`.`text_info` (`text_id`, `text_name`, `text_author`, `text_type`, `text_status`, `text_latest`, `text_intro`) VALUES ('"+item['text_id']+"', '"+item['text_name']+"', '"+item['text_author']+"', '"+item['text_type']+"', '"+item['text_status']+"', '"+item['text_latest']+"', '"+item['text_intro']+"');"
#执行sql语句
self.cursor.execute(sql)
#保存修改
self.connection.commit()
return item
def __del__(self):
#关闭操作游标
self.cursor.close()
#关闭数据库连接
self.connection.close()
写在最后:
代码敲好后不要忘记在settings里开启pipelines
pymsql连接时默认的编码是latin-1,所以在建立数据库连接时会增加参数charset来修改编码,要修改为utf-8的话得用charset=’utf8‘,而不是charset=’utf-8‘
这个网站有些问题,会时不时报404错误,所以在爬的过程中会报list index out of range,这是因为得到了错误的网页,xpath找不到对应得路径返回了空列表。这是正常现象,并不是代码出问题了(当然,如果频繁报错最好是检查一下代码)
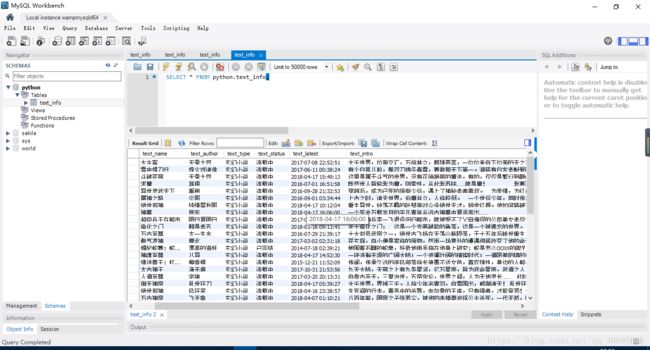
贴一张成功后的图片:
最后的最后,觉得我写的不错的话记得关注我哦。