ibm bpm实战指南_IBM Business Process Manager的灾难恢复指南
ibm bpm实战指南
业务流程管理是用于运行业务交易的概念和方法,其持续增长的势头。 功能强大的业务流程管理系统以敏捷,灵活和一致的方式为利益相关者提供价值。 您的组织可能刚刚开始将IBM BPM应用于您的业务,因此您可能没有遇到对强大的灾难恢复解决方案的需求。 但是,许多组织已经在他们的IBM BPM系统上托管了关键任务应用程序。 如果您的组织是其中之一,那么您已经了解了发生灾难时与IBM BPM系统丢失相关的成本,以及灾难发生后恢复业务运营的过程。
使用业务流程管理系统的常见指导原则是着重于提供业务竞争优势或在市场中具有独特价值的高价值流程。 无论优势是成本效益,客户保留率还是另一种业务价值衡量标准,业务流程通常都需要高度可用,并受到日益严格的灾难恢复要求的保护。
可以理解,灾难恢复要求是通过恢复时间目标(RTO)和恢复点目标(RPO)来衡量的。 近年来,IBM BPM系统的灾难恢复要求已经从传统的RTO和RPO数量转移到了更具挑战性的目标。 例如,人们渴望在30分钟内恢复并重新营业,这导致大型组织寻求新的和更多的方法来进行灾难恢复。
查理·雷德林(Charlie Redlin)于2008年在developerWorks上发表的关于灾难恢复环境的WebSphere Process Server和WebSphere Enterprise Service Bus的异步复制的开创性工作确立了灾难恢复策略的基准,定义了一种被称为“经典灾难恢复”的方法,因为其广泛的吸引力和成功。 Charlie描述的策略在IBM BPM客户中仍然很流行,并依赖于以下各节中称为克隆单元和存储托管复制的技术。 Hong Yan Wang和其他人描述了一种替代方法,该方法将事务和补偿日志存储在关系数据库中以在IBM Business Process Manager中实现高可用性和灾难恢复,该方法于2014年在developerWorks上发布。她的方法使用了新的WebSphere Application Server功能和新的拓扑结构来处理与六年前查理·雷德林(Charlie Redlin)相同的技术问题。 哪种方法更好? 您应该使用哪个作为自己的灾难恢复设计的基础? 答案当然是,它取决于许多因素。 第一步是审查灾难恢复中与所有IBM BPM工作负载相关的关键概念,以及由IBM BPM系统通常管理的工作负载的状态性带来的关键挑战。 第二步是注意成功的IBM BPM灾难恢复解决方案中的常见模式,以了解每种模式的一些优缺点。 有了这两部分信息,对要解决的挑战的理解以及解决这些挑战的常用技术,您作为IBM BPM管理员就可以开始设计满足您的业务需求的灾难恢复策略的过程。
如果您想将IBM BPM开发为平台,可以在该平台上运行一套全面而详尽的业务流程,包括组织中最关键的业务流程和关键业务流程,则应继续阅读。 您可能是应用程序架构师,企业架构师或高级业务专家,并且熟悉业务驱动的需求,以在发生灾难时保持可用性。 讨论的技术适用于IBM BPM版本8.0.1.3、8.5.0.1、8.5.5.0、8.5.6和8.5.7。
IBM BPM灾难恢复中的关键概念
业务流程管理平台由协同工作的硬件和软件组件组成,其中任何一个都可能会失败。 系统架构师和系统管理员的目标之一是确保有足够的冗余,以使业务活动能够继续进行,即使信息技术资源出现故障以及在维修或更换它们时也是如此。
例如,物理磁盘驱动器被分组为一个阵列,该阵列由一个控制器控制,该控制器在整个组中分配数据,并且在其中一个磁盘发生故障时自动重定向流量。 同样,IBM WebSphere Network Deployment将应用程序服务器分组为集群并协调它们之间的通信,以便该组可以容忍丢失任何成员。 此类构建模块包括用于使业务流程管理系统高度可用并成功使用该系统来自动适应丢失任何单个要素的工具集。 这两个示例解决了高可用性事件,即包含较大系统的单个组件故障的事件。 相反,灾难是灾难性事件,包括同时丢失整个数据中心的多个组件。 但是,冗余的核心概念可以扩展为包括跨数据中心边界的关键产品组件和运行时数据的复制,从而即使整个主数据中心丢失,业务也可以继续进行。
设计灾难恢复策略时,一个重要的考虑因素是,在这样做时,基础架构设计师必须假定用于保持业务状态的主存储丢失了。 因此,除了替换业务流程管理系统的所有相关硬件和软件组件之外,灾难恢复解决方案还必须替换代表业务状态的数据。 这可以通过使用复制来处理:将数据副本保留(并保持最新)在与主数据中心充分隔离的位置,以确保两组数据不受同一灾难的影响。 复制对于业务流程管理系统尤为重要,因为复制管理系统对维持业务所依赖的活动状态至关重要的数据,通常会跨多个数据存储系统协调活动。 为了更好地理解复制需求,请将要复制的数据分为两类:配置数据和运行时数据。
配置数据
顾名思义,配置数据由定义业务流程管理系统状态所需的所有元数据组成,包括安装了IBM BPM的IBM WebSphere Network Deployment拓扑的定义以及连接到外部的所有信息。资源和数据源。 如果您熟悉IBM WebSphere Application Server,则可以将配置数据视为IBM WebSphere Application Server概要文件的内容。 另外,IBM BPM配置数据还包括元数据,该元数据定义了在创作环境中构建并部署到运行时服务器的业务流程。 此流程定义元数据在WebSphere Application Server概要文件和IBM BPM数据库中。
为了复制的目的,配置数据的一个重要特征是离散的,孤立的事件会对其进行更改。 例如,在管理控制台中对概要文件信息所做的更改,将代码更改应用于流程应用程序或升级IBM BPM都会更改配置数据。 通常,操作过程可能会将对配置数据的这些类型的更改收集到组中,这些组可能一起在系统维护期间应用到系统中。 因此,对配置数据使用离散复制技术,在应用并确认每组更改后收集配置状态的快照,以产生所需的效果,从而获得稳定的系统。
运行时数据
与配置数据相反,运行时数据由描述业务处理的流程实例的所有信息组成。 描述流程实例当前状态的元数据(包括当前正在执行的任务以及关联的业务数据变量的值)存储在IBM BPM数据库中。
因为IBM BPM使用消息传递引擎进行内部和外部通信,所以运行时数据还包括存储在队列中消息中的信息。 IBM BPM允许应用程序开发人员将其业务流程与应用程序数据库集成,并通过使用内置在业务流程实现中的Java数据库连接(JDBC)通信来保持一致性。 这些应用程序数据库的内容(如果存在)也包括在运行时数据的范围内。
最后,IBM BPM依赖于WebSphere Application Server事务服务来协调数据更改并将其分组为原子单位,以确保所有更改都发生或不发生。 因此,与WebSphere Application Server事务服务关联的日志文件是运行时数据的重要部分,它链接了IBM BPM产品资源和特定于应用程序的资源。
为了复制的目的,运行时数据的一个重要特征是它会不断变化。 因此,使用连续策略来复制运行时比率是很自然的,无论该策略是同步的(保证提交给源的每个更改也保证都提交给副本)还是异步的(可以分批发送对源的更改,定期复制到副本)。 无论哪种方式,复制都不会类似于一系列离散快照,而是从源到副本的稳定信息流。 通常,同步复制技术不是灾难恢复的理想选择,因为在跨地理位置分开的站点上应用时,它们会带来无法接受的性能成本。 因此,运行时数据通常首选异步复制。
尽管从性能的角度来看是可取的(很多时候是强制性的),但是异步复制运行时数据对一致性提出了挑战。 由于运行时数据跨多个资源分布,因此在任何时间点,这些资源之一的异步更新副本可能与另一资源的独立异步副本不一致。 在恢复时,这种不一致会导致损坏,这可能导致业务数据丢失或阻止锁定的资源(例如数据库行)在事务超时之前被释放。
许多基于存储的复制管理技术(例如,由存储区域网络提供的复制管理技术)提供了称为一致性组的功能来解决此问题。 使用一致性组,可以将物理上和逻辑上不同的存储卷的集合进行分组以进行复制。 这样,即使使用异步复制,复制管理器也可以确保在所有卷上保留写顺序一致性。 因此,即使副本中的映像可能永远不会与源中的原始映像匹配(由于异步批处理),它仍会忠实地反映源在过去某个时刻的状态。
恢复指标
当您考虑基于运行时数据的异步复制映像的恢复机制时,您将了解灾难恢复的两个关键指标:恢复点和恢复时间。
恢复点是源和副本之间的运行时数据状态之间的延迟的度量,通常以经过的时间来度量。 同步复制可以提供零延迟的副本,因此,恢复点可以与源完全匹配。 因为异步复制不能保证在复制副本上同时应用所有对源的更新,所以恢复点度量很重要。 延迟量将取决于复制管理软件的详细信息,但是通常,较小的恢复点度量(较小的延迟)会更昂贵。 大多数企业都建立了一个容忍度,称为恢复点目标(RPO),它描述了在灾难和后续恢复中允许丢失的最大数据量。
恢复时间度量标准描述了从灾难发生到恢复业务运营所需的时间。 同样,如果发生灾难,不同的企业(实际上,同一企业中的不同应用程序)可以容忍不同的停机时间。 这种对停机时间的容忍度通常表示为恢复时间目标(RTO)。
IBM BPM的灾难恢复选项
IBM BPM团队已经测试并认证了基于两种根本不同的IBM WebSphere Network Deployment拓扑结构以及两种复制运行时数据的方法的灾难恢复策略。 您可以结合使用这些技术来产生四个不同的选项,以完成IBM BPM解决方案的灾难恢复。 添加另一种更简单的方法,并将这些基本概念扩展为更高级的混合方法,进一步扩展了可用于IBM BPM灾难恢复的各种方法。
在每种情况下,确保您在主数据中心中的IBM BPM安装遵循良好的高可用性惯例以及《 IBM红皮书》出版物《 业务流程管理部署指南:使用IBM Business Process Manager V8.5》中的建议,这一点很重要。 。
下一节探讨了可以应用的灾难恢复选件的一些关键功能。
复制配置数据:克隆单元与杂散节点
上一节介绍了将IBM WebSphere Application Server和IBM BPM配置数据从主数据中心复制到远程灾难恢复数据中心的需求。 通过使用从源到副本的配置数据的逐个文件副本来实现此目的的策略称为克隆单元拓扑。 远程数据中心中的单元是主数据中心中单元的精确副本。 单元名称,节点名称和服务器名称相同。 实际上,WebSphere Application Server和IBM BPM代码用来描述单元的所有组件的通用唯一标识符(UUID)是相同的。 另外,由WebSphere Network Deployment管理的事务恢复处理要求与服务器所部署到的操作系统相关联的主机名必须在两个数据中心之间都匹配。 因此,通过从主数据中心备份构成拓扑定义的文件并将这些文件还原到辅助数据中心,来构造辅助数据中心中的WebSphere Network Deployment拓扑。 尝试通过使用并行安装和运行概要文件创建脚本来构造辅助单元不起作用(因为UUID不匹配,尤其是因为这些原因)。
杂散节点拓扑使用完全不同的方法。 流浪节点方法不是从备用数据中心的主数据中心复制服务器,而是在两个数据中心之间扩展了IBM BPM单元。 这样,该单元包含两个数据中心中的节点以及联合到同一单元中的两个数据中心中的群集成员。 通常,不建议跨数据中心跨越一个单元,因为它有数据损坏(由分区网络导致)和性能问题(由连接两个数据中心时网络中的高延迟导致)的风险,因此,必须采取其他步骤来缓解如以下段落所述,这些风险。
IBM BPM和IBM WebSphere Network Deployment都是基于以下期望而设计的:组成整个单元的服务器通过快速,可靠的局域网(LAN)而不是较慢,可靠性较差的广域网(WAN)连接。 离群节点拓扑结构提出了一项重要的附加要求:必须存在操作过程,以确保一次只能在一个数据中心中启动应用程序服务器。 在正常操作期间,这些是主数据中心中的服务器。 发生灾难后,该过程将确保实际上已停止主数据中心中的所有服务器,然后可以启动恢复数据中心中的服务器。 这样,就不会发生运行时数据的跨数据中心通信。 许多团队发现使用脚本来自动化操作过程的运行是提高效率,正确性和可重复性的有价值的技术,并且有助于减少总恢复时间并避免违规,例如意外地在两个数据中心中同时启动节点时间。
相反,在杂散节点拓扑中跨数据中心传送配置数据是可以接受的。 这意味着节点代理可以在两个数据中心中运行,以通过在部署管理器和节点代理之间进行通信来传播配置更改。 结果,与克隆单元方法使用的备份和还原技术相比,维护数据中心边界的配置更改是自动化的。 因此,由于所有配置和复制功能都在WebSphere Network Deployment基础架构中,因此,杂散节点拓扑可能比克隆的单元拓扑更快,更简单,并且成本更低。
复制运行时数据:存储子系统与数据库
如上一节所述,许多企业级存储解决方案提供了可用于跨多个卷协调异步复制的功能。 例如,基础架构管理员可以使用存储区域网络向IBM BPM基础结构提供两个卷,并使用存储区域网络提供的工具来构建包含两个卷的一致性组。 即使使用异步复制,存储区域网络也可以确保在两个卷之间保留写顺序一致性。 可以将这些卷之一提供给数据库管理器,以用于构造IBM BPM将使用的数据库容器和日志。 一致性组中的其他卷可以用作分布式文件系统(网络文件系统,通用并行文件系统或类似文件)的后备存储,该文件系统托管与WebSphere Application Server事务服务和补偿服务相关联的恢复日志,并由IBM BPM。
就像存储子系统一样,许多数据库管理系统(例如Oracle Data Guard复制和IBM DB2中的高可用性灾难恢复(HADR)功能)都提供复制功能。 以前不可能将这些数据库复制功能与IBM BPM一起使用,因为它们没有提供维护数据库内容和托管WebSphere Application Server恢复日志的文件系统之间一致性的方法。 但是,最新版本的WebSphere Application Server包含一个选项,IBM BPM服务器可以使用该选项将恢复日志存储在数据库中,而不是直接存储在文件系统中,如将事务和补偿日志存储在关系数据库中以实现更高的可用性中所述。 IBM Knowledge Center上的WebSphere Application Server文档。 如果此数据库与包含IBM BPM数据库的数据库相同,则数据库管理技术变得可行。
如果要将事务和补偿日志存储在数据库中,请注意,与将这些信息直接存储在配置良好的文件系统中相比,这样做可能会给某些工作负载带来额外的性能开销。 从一个IBM BPM应用程序到另一个IBM BPM应用程序,这些额外开销的影响是不同的。 使用业务流程建模表示法(BPMN)的IBM BPM Standard实现和流程的影响最小,而使用业务流程执行语言(BPEL)的流程(尤其是事务复杂的宏流应用程序)的影响更大。 与往常一样,当您评估新技术时,请务必测量特定于您自己的流程和基础架构的性能变量。 尽管有性能方面的考虑,但通过将事务和补偿日志存储在数据库中所提供的简单性和灵活性使其成为许多应用程序的流行选择。
恢复WebSphere Application Server部署管理器
灾难发生后,首要任务是恢复业务运营,这需要启动备用IBM BPM服务器,使您可以查看和处理业务流程。 WebSphere Network Deployment基础结构的其他元素(最著名的是Deployment Manager)是更改系统配置所必需的,并且最终必须替换。
IBM WebSphere开发者技术期刊2010年1月版的WebSphere Contrarian专栏, 运行时管理高可用性选项redux ,描述了可用于复制Deployment Manager配置以替代Deployment Manager提供的管理功能的技术。如果发生灾难。
一种流行的技术涉及Deployment Manager配置的基于文件的复制,就像已经讨论的克隆单元策略中所做的一样。 因此,自然也可以将此方法扩展到Deployment Manager。 即使单元配置的其余部分不需要复制,这种样式的Deployment Manager复制和替换也可以很好地适用于杂散节点方法。 WebSphere Network Deployment基础结构在正常操作期间直接维护杂散节点的配置。
辅助数据中心的容量
无论是使用零散节点还是克隆的单元拓扑来复制IBM BPM配置信息,从灾难中恢复之后,计划辅助数据中心中的足够容量都是很重要的。 通常,组织从灾难中恢复后需要与正常操作期间相同的容量(节点数和每个节点的核心数)。 毕竟,灾难恢复计划的目标是使系统恢复正常状态。
但是,灾难恢复计划中的一个常见缺陷是无法确保备用数据中心有足够的可用容量来支持完整的生产负载。 在这些情况下,灾难恢复过程可能会成功完成,但是您可能会发现替换的IBM BPM和数据库服务器立即过载。 因此,备用数据中心中的备用容量应等于主数据中心中的备用容量。 当然,辅助数据中心中的服务器在正常运行期间不必保持空闲状态。 它们可以用于其他低优先级的工作,只要在执行灾难恢复过程后可以立即将其从系统中删除。
灾难恢复策略
有七种方法涵盖了可与IBM BPM一起使用以实现业务需求的可用性和恢复的广泛技术。
简单的灾难恢复
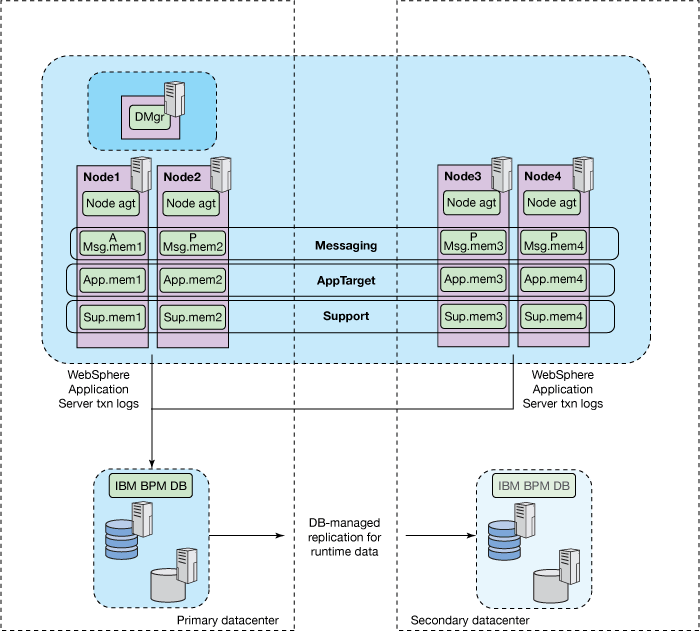
确保复制期间一致性的最简单方法是使整个系统停顿。 使用管理工具停止IBM BPM服务器时,参与业务流程的所有资源都是一致的,而不管其存储子系统如何,并且可以单独复制。 因此,您具有一种简单的灾难恢复方法,该方法在可以忍受定期计划的系统中断或缺乏跨资源管理器进行统一复制的功能的情况下很有用。 事实证明,当需要复制测试和性能验证系统时,此策略很有用。 杂散节点或克隆的单元拓扑可以与基于脱机备份的复制方案一起使用。 克隆单元拓扑是典型的,因为所有配置数据和运行时数据都会在维护窗口期间一起复制,如图1所示。
| 简单的灾难恢复 | |
|---|---|
| 典型的RTO | 4-8小时 |
| 典型的RPO | 取决于维护间隔,通常为24小时 |
| 优点 | 简单 |
| 注意事项 | 主数据中心的定期计划中断 |
| 推荐用于 | 测试系统 可以承受常规停机时间和高RPO的过程 |
图1.简单的灾难恢复
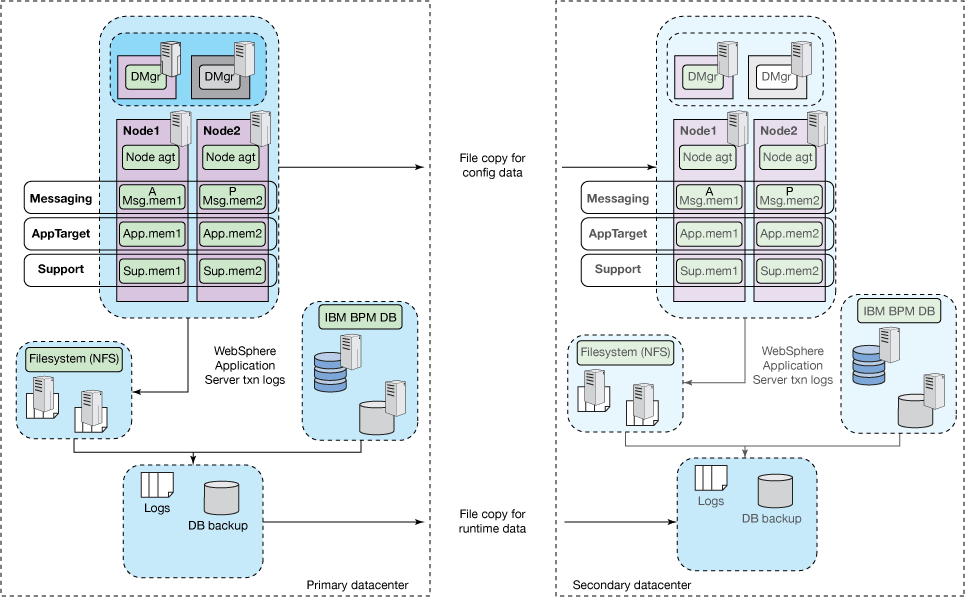
经典灾难恢复(存储区域网络复制)
将克隆的单元拓扑与存储管理的复制相结合,将为IBM BPM提供最流行的灾难恢复方法之一。 在IBM开发实验室和客户端安装中,它仍然是测试最广泛的方法。 有关说明,请参见图2。 使用克隆的单元拓扑要求恢复过程确保来自主数据中心的主机名可用于辅助数据中心。
| 经典灾难恢复 (存储区域网络复制) |
|
|---|---|
| 典型的RTO | 4-8小时 |
| 典型的RPO | 秒到分钟 |
| 优点 | 存储区域网络复制提供了一流的企业复制功能 |
| 注意事项 | 来自主数据中心的主机名必须在辅助数据中心中可用。 |
| 推荐用于 | 具有现有存储区域网络复制实践的大型企业 |
图2.经典灾难恢复(存储区域网络复制)
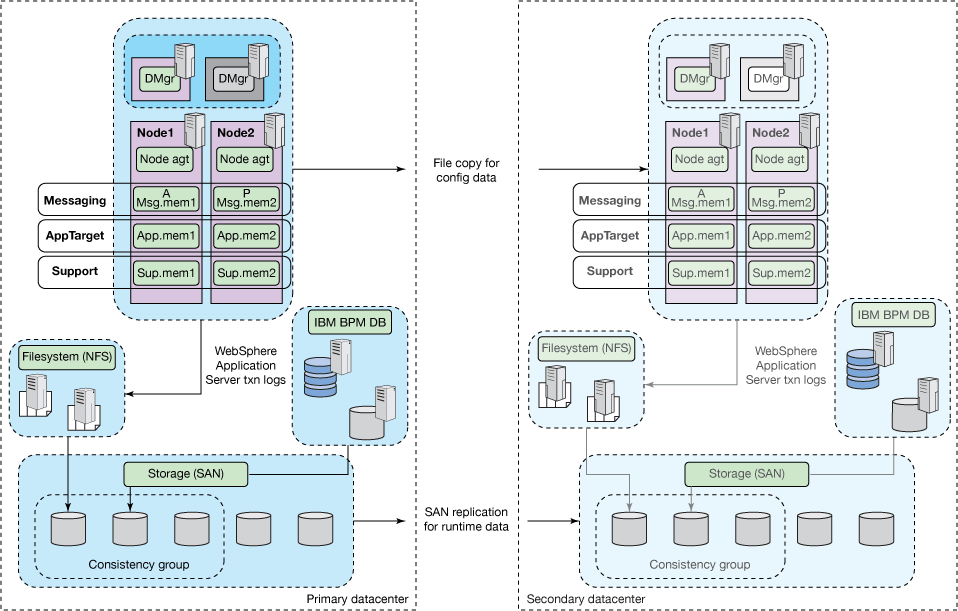
经典灾难恢复(数据库复制)
具有基于Oracle Data Guard Replication或DB2 HADR功能而非存储子系统组件的已建立复制实践的组织,可以将WebSphere Application Server事务和补偿日志直接放置在IBM BPM数据库中,以将其现有的操作过程也用于IBM BPM(参见图3)。 广泛的测试证明这种方法是可靠的。 同样,由于备份辅助数据中心中数据库服务器的存储在正常操作期间仍保持安装状态,因此此方法可以提供比存储子系统管理的复制更快的总恢复时间。
| 经典灾难恢复(数据库复制) | |
|---|---|
| 典型的RTO | 2-4小时 |
| 典型的RPO | 秒到分钟 |
| 优点 | 使用数据库复制技术 |
| 注意事项 | 来自主数据中心的主机名必须在辅助数据中心中可用。事务日志的存储和复制性能可能是某些应用程序的一个因素。 |
| 推荐用于 | 具有基于数据库管理的复制的现有复制实践的组织 |
图3.经典灾难恢复(数据库复制)
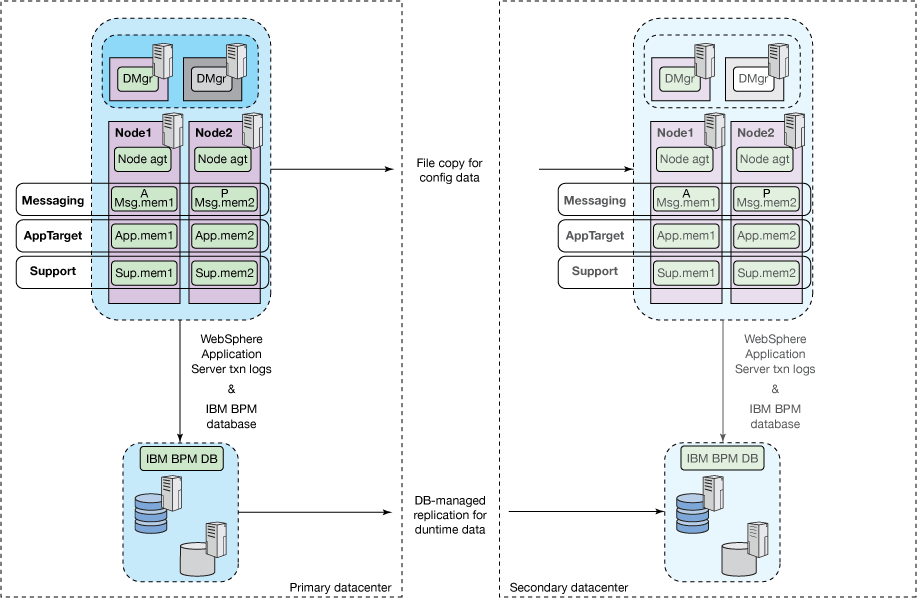
杂散节点(数据库复制)
流浪节点拓扑结构与数据库管理的复制相结合,在内部测试中显示出最快的总恢复时间。 除了在正常操作期间辅助数据中心中的数据库存储保持安装的事实外,流浪节点方法还允许辅助数据中心中的节点代理启动并运行,从而减少了恢复过程中要运行的步骤数。 自从IBM BPM版本8.5.0.1和8.0.1.1引入以来,这种方法已经非常流行,尤其是在依赖Oracle Data Guard Replication的IBM BPM Standard Edition安装中。 参见图4。
在2014年9月版中发布的IBM Business Process Manager中的将事务和补偿日志存储在关系数据库中以实现高可用性和灾难恢复中,提供了基于此拓扑构建IBM BPM单元所需的配置步骤的详细说明。业务流程管理杂志。
| 杂散节点(数据库复制) | |
|---|---|
| 典型的RTO | 约1小时 |
| 典型的RPO | 秒到分钟 |
| 优点 | 使用数据库管理的复制技术进行快速,灵活的恢复 |
| 注意事项 | 操作程序必须确保正常运行期间不会意外启动杂散节点。 事务日志的存储和复制性能可能是某些应用程序的一个因素。 |
| 推荐用于 | 具有基于数据库管理的复制的强大WebSphere Application Server网络部署技能和复制实践的组织 |
图4.杂散节点(数据库复制)

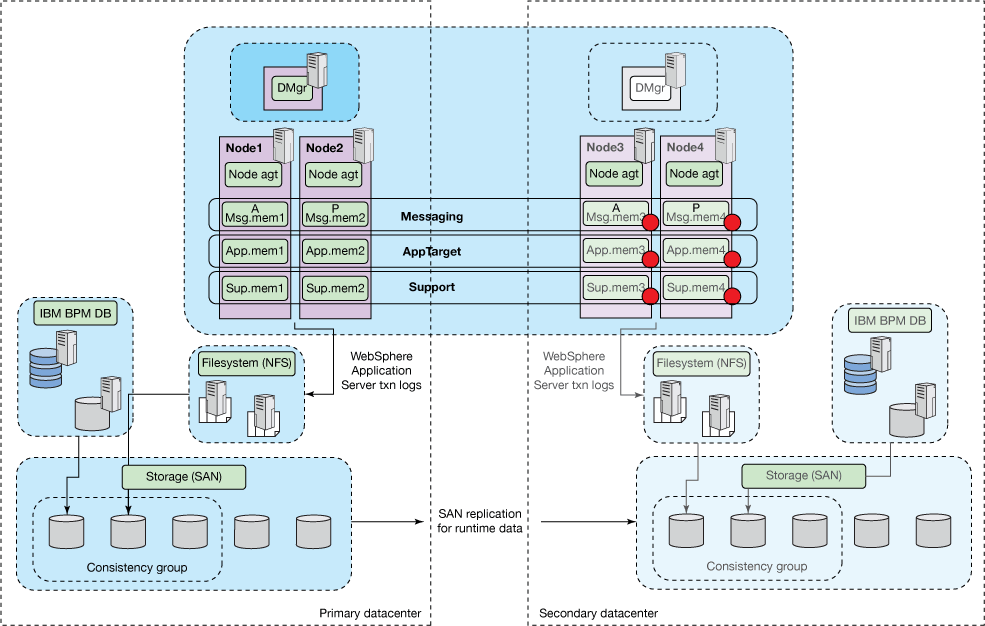
杂散节点(存储区域网络复制)
您还可以将散乱节点配置与依赖于存储子系统的运行时数据复制策略配对,如图5所示。这种组合在已经将存储区域网络复制用于其他应用程序并且想要应用此功能的组织中特别流行。也可以练习他们的IBM BPM应用程序。 这种组合提供了用于复制的存储区域网络的功能和灵活性,同时还可以简化由杂散节点提供的IBM BPM单元的恢复。
| 杂散节点(存储区域网络复制) | |
|---|---|
| 典型的RTO | 2小时 |
| 典型的RPO | 秒到分钟 |
| 优点 | 具有一流企业复制功能的灵活WebSphere Application Server网络部署配置 |
| 注意事项 | 操作程序必须确保正常运行期间不会意外启动杂散节点 |
| 推荐用于 | 具有基于存储区域网络技术的强大WebSphere Application Server网络部署技能和复制实践的组织 |
图5.杂散节点(存储区域网络复制)
地铁对
在多个数据中心中使用具有活动成员的单个IBM BPM单元仍然是不建议用于灾难恢复目的的做法。 IBM BPM服务器大量使用其数据库,而这些方法所暗示的网络分离会通过网络分区(裂脑场景)增加性能问题和数据损坏问题的风险。 为了降低网络问题的风险,这些安装通常依赖于彼此靠近的一对数据中心(这就是为什么将该方法称为“ Metro”的原因),并通过冗余的高容量网络基础结构进行连接,如图2所示。图6.这种邻近性降低了对自然灾害和其他影响广泛地理区域的事件的保护。 因此,这种方法被认为是高级的高可用性技术,而不是灾难恢复的解决方案。
Before implementing an approach based on a metro pair with no geographic dispersion, carefully consider all availability and recovery requirements to ensure that the benefits justify the risks. In particular, consider the behavior of the database server when the primary data center is lost. If switching the database from one of the metro pair data centers requires the IBM BPM servers to be restarted, you have lost the recovery time advantage that the topology tried to achieve.
Many organizations find that a single cell split among data centers forms an important element of their overall availability and recovery strategy. When backed by a fast and reliable network and supported by exhaustive testing to characterize actual failover times and the risk of data corruption, topologies like the metro pair can serve a purpose. When augmented to include a true, remote disaster-recovery site, as described in the Metro pair and disaster recovery section, these strategies can become a valuable enterprise class solution.
| Metro pair | |
|---|---|
| Typical RTO | 分钟 |
| Typical RPO | Seconds to minutes |
| 优点 | Gives the appearance of Active/Active |
| Cautions | No geographic dispersion Network latency and partition exposures |
| Recommended for | Not generally recommended for disaster recovery |
Figure 6. Metro pair
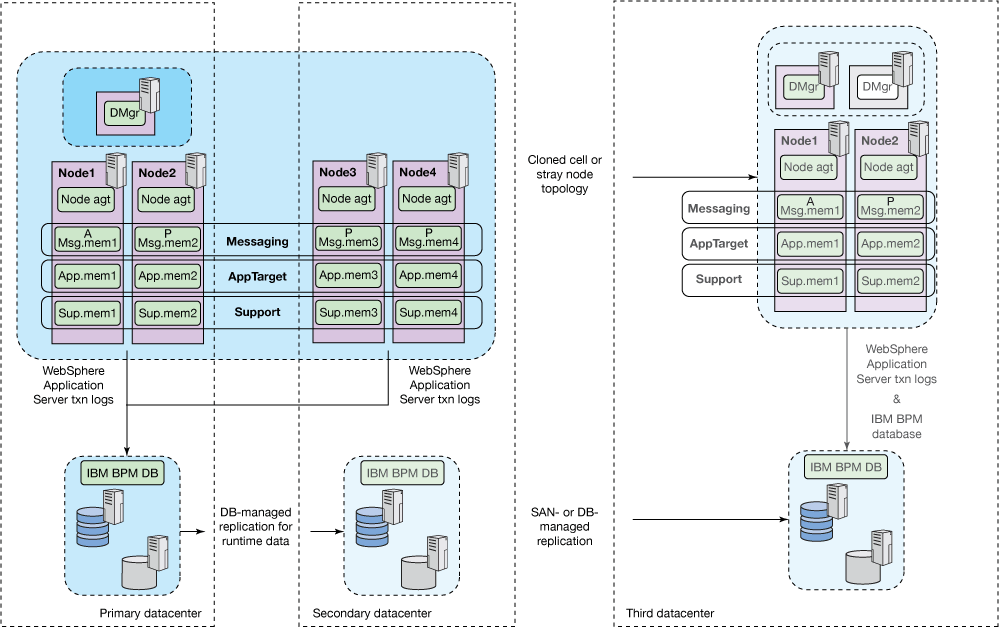
Metro pair and disaster recovery
You can augment the metro pair topology approach with a disaster recovery strategy that uses replication across geographically dispersed data centers to a passive standby system. This solution resolves the exposure to total system loss in the event of a natural disaster that is present when only a metro pair topology is used. Because the metro pair topology is nothing more than a single, extended IBM BPM cell, you could implement this augmentation by using any of the four core disaster-recovery strategies described previously.
For simplicity, Figure 7 depicts a cloned cell with database managed replication, although stray nodes and storage-area-network-managed replication techniques are equally well suited to this type of approach. Because a third data center is introduced, the operational procedures required to manage this type of infrastructure are more complex than the other approaches described.
| Metro pair and disaster recovery | |
|---|---|
| Typical RTO | Local: Minutes / Geo: up to 4 hours |
| Typical RPO | Seconds to minutes |
| 优点 | Hybrid approach provides the best of both worlds |
| Cautions | 复杂 |
| Recommended for | Sophisticated organizations with a well-defined recovery requirements and strong test practice |
Figure 7. Metro pair and disaster recovery
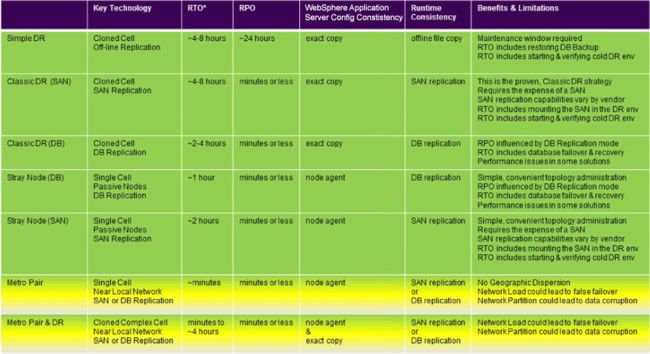
Summary of disaster recovery strategies
The previous sections explored core replication technologies for IBM BPM configuration data (stray nodes and cloned cells) and runtime data (storage-managed and database-managed), leading to four primary disaster recovery strategies. Extending this set of four to include the simple disaster recovery strategy and the two strategies based on a metro pair of IBM BPM data centers, gives seven approaches that cover the broad spectrum of techniques that you can use with IBM BPM to achieve availability and recovery business requirements. Figure 8 provides a quick reference that compares the features that distinguish these approaches from each other.
Figure 8. Summary of disaster recovery strategies
Validation of disaster recovery
As with any set of nonfunctional requirements, verifying that business requirements for recovery behavior are met is an important element of the disaster recovery plan. Because simulations including cross-site failover are disruptive, it is extremely useful to provision a dedicated test environment for this type of testing. Primary objectives include validating cross-site configuration to ensure that all systems connect and communicate properly after recovery and measurement of total recovery time to set proper expectations in the event of an actual disaster. In addition, many organizations improve execution efficiency through practice, as administrators become more comfortable and confident in the steps to run. Beyond this, new opportunities for scripting and other sorts of automation become apparent only after repeated execution.
The future of disaster recovery
While techniques such as cloned cells, stray nodes, database-managed replication and storage-managed replication originated in traditional on-premise environments, it is natural to consider to what extent the same techniques can be applied or extended to virtual environments. Beyond this, virtualization of infrastructure introduces new opportunities for automating the operational procedures upon which a successful disaster recovery procedure relies. Look for future IBM content that more deeply covers how disaster recovery can be achieved in the presence of the various virtualization approaches that dominate the world of infrastructure and topology for IBM BPM systems.
In addition to virtualization influences, more and more IBM BPM workloads are running in various cloud configurations, including public clouds, hosted configuration, and private cloud environments such as those running on IBM PureApplication System. Look for updates on how to best achieve disaster recovery in these environments to complement this update.
As a preview specifically on the subject of running IBM BPM systems on IBM PureApplication System, the recently released IBM BPM 8.5.5 pattern supports the same approaches for disaster recovery that are popular when replicating configuration data and runtime data in physical systems.
结论
Ensuring that a business process management system running mission-critical business processes can be recovered in the event of a disaster remains a key requirement of large businesses. Stateful workloads bring challenges to the table that are beyond those of traditional stateless workloads.
You can configure IBM BPM V8.x to recover from a disaster by using various techniques. Recent evolutions in how IBM BPM can be configured and run now provide new and valuable configuration options that significantly reduce the possible RTO values down to less than an hour. You should now be familiar with the current set of options, the current set of implications for using those options in terms of topology, and the underlying infrastructure capabilities necessary to get to these aggressive RTO numbers considered unachievable before.
Each of the possible configurations impacts the underlying infrastructure and has associated costs. Charlie Redlin engaged clients with a simple message when they requested aggressive RTO and RPO numbers: "How much money do you have to achieve required numbers?" Although aggressive disaster recovery still costs money and takes a deep infrastructure commitment, the good news is that, with the current infrastructure and database capabilities, the costs are coming down to more affordable levels. You can use these capabilities to achieve aggressive RTO and RPO disaster recovery.
致谢
The authors would like to thank Hong Yan BJ Wang, Yu Zhang, Uday Pillai and Mahesh Sharma for their review and valuable input.
翻译自: https://www.ibm.com/developerworks/bpm/library/techarticles/1504_richardson/1504_richardson.html
ibm bpm实战指南