数据分析一共分为五个任务:

image
第一步:明确分析的任务
分析出每个季度的骑行的平均时长和各个季度的对比
第二步:数据处理
先看数据:

image
shell 查看csv 数据前十行
➜ data cat bikeshare/2017-q1_trip_history_data.csv|head -10
image.gif
如果用Excle 打开呢?
image.gif
根据 上面的格式我们开始进行数据的收集
数据收集
image.gif
from pathlib import Path
导入Python3下的pathlib模块
怎么才能获取文件的路径呢?
image.gif
from pathlib import Path
ls
data/ index.py
Path("data/bikeshare")
Out[4]: PosixPath('data/bikeshare') Path("data/bikeshare")/"index.py"
# 的文件路径,可以直接拼接的
Out[5]: PosixPath('data/bikeshare/index.py')Numpy.loadtxt()
Pycharm快捷键 ⌘+B 获取函数的源码:
def loadtxt(fname, dtype=float, comments='#', delimiter=None,
converters=None, skiprows=0, usecols=None, unpack=False,
ndmin=0):
def collect_data(data_path):
"""
数据收集 数据分析的第一步 :param data_path: 数据路径 :return:
""" data_arr_list = []
for data_file in data_filenames:
data_csv = np.loadtxt(Path(data_path) / data_file, delimiter=',', dtype='str', skiprows=1)
# delimiter定界符逗号,dtype 字符类型 skiprows 跳过第一行
# 因为numpy库默认的是浮点型,而为了方便后续处理我们将其改为str格式,用的参数就是dtype='str' data_arr_list.append(data_csv)
return data_arr_list
# delimiter定界符逗号,dtype默认是float,但是我们用str的形式读取,字符类型 skiprows 跳过第一行,因为第一行是表头 # 因为numpy库默认的是浮点型,而为了方便后续处理我们将其改为str格式,用的参数就是dtype='str'
在的位置打个断点:

image
打个断点 debug 模式调试
image
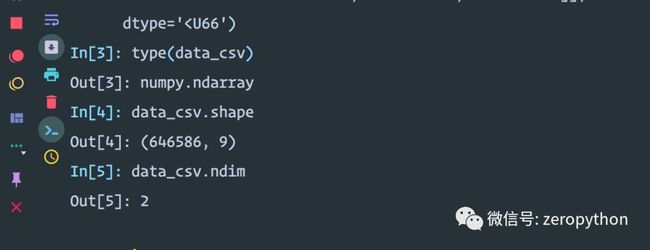
type(data_csv) Out[3]: numpy.ndarray
# 数据类型
data_csv.shape
Out[4]: (646586, 9)
# 数据的大小
data_csv.ndim
Out[5]: 2
# 只有横向和纵向代表的两个维度
数据的收集完成后,我们接下来就开始第三部分:数据的处理
def process_data(data_arr_list):
duration_in_min_list = []
for data_arr in data_arr_list:
duration_str_col = data_arr[:, 0]
# 行优先, [:,0] 取出所有行的第0列
duration_str_ms = np.core.defchararray.replace(duration_str_col, '"', '')
# 把"替换成空
duration_str_min = duration_str_ms.astype('float') / 1000 / 60
# astype字符串转换成 float 转换成 min
# 向量化操作,如果不行,我们再考虑 变量
duration_in_min_list.append(duration_str_min)
return duration_in_min_list
第四步:数据分析
求出平均骑行的时间,我们可以采用np.mean 这种方式求出整列的平均值
def analyze(duration_in_min_list):
"""
数据分析
"""
duration_mean_list = []
for index, duration in enumerate(duration_in_min_list):
duration_mean = np.mean(duration)
# duration 整列的平均值
print("{} ,平均骑行时间{:.2f}".format(index + 1, duration_mean))
# 平均骑行时间,保留两位有效数字
duration_mean_list.append(duration_mean)
return duration_mean_list
最后一步:数据展示
我们采用的matplotlib 库进行的柱状图展示:
当然我们首先导入库
def show_results(duration_mean_list):
# 结果展示
plt.figure()
# 创建个图
plt.bar(range(len(duration_mean_list)),duration_mean_list)
# 采用柱状图,横坐标采用四个季度的 ,纵坐标采用的是四个季度的平均值
plt.show()
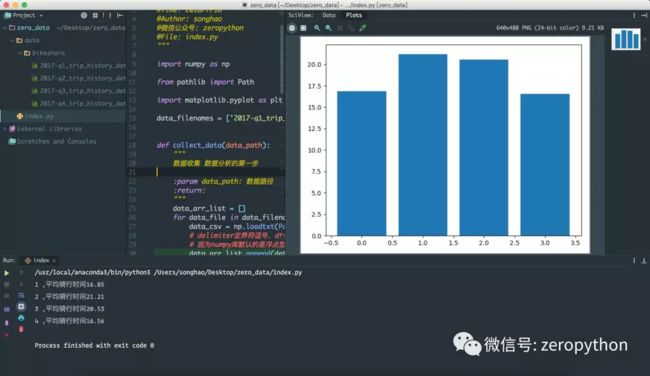
image.png
完整代码: 关注微信公众号 :zeropython 回复 data_bike

image.png