机器学习笔记--常见算法(9)--support vector machine(SVM)(台大林轩田SVM)
文章目录
- 1. Liner Support Vector Machine
- 1.1 SVM引出
- 1.2 SVM中的margin计算
- 1.3 margin计算公式的简化
- 1.4 SVM一般求解方法
- 1.5 非线性SVM
- 2.Dual Support Vector Machine
- 2.1 Dual SVM引出
- 2.2 Lagrange Function 拉格朗日函数
- 2.3 把SVM构造成非条件问题
- 2.4 Lagrange Dual SVM
- 2.6 解对偶SVM
1. Liner Support Vector Machine
1.1 SVM引出
SVM是一种分类器。现在有两种类别(如下图),我们要找到一条直线,将两个不同的类别区分开。图中存在许多满足条件的直线,我们该选哪条最合适呢?
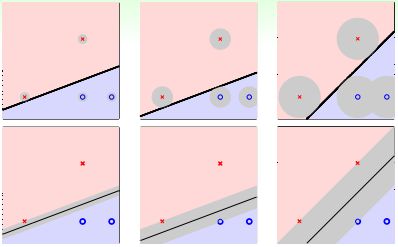
直观上来说,我们有几种考虑因素:①能容忍更多噪声,②模型更健壮,不会过拟合。
这个问题可以等价于:选择一条直线,判断该直线到最近的点的距离究竟是远还是近。我们希望这条直线更"fat"(如上图最后一条直线),也就是直线到最近的点的距离越远越好。
1.2 SVM中的margin计算
定义分类线有多胖,也就是看距离分类线最近的点与分类线的距离,我们把它用margin表示。
整体来说,我们的目标就是找到这样的分类线并满足下列条件:
- 分类正确。能把所有正负类分开。即 y n ω T x n > 0 y_n\omega^Tx_n>0 ynωTxn>0
- margin最大化
有了上述条件,那么如何计算点到分类线的距离呢?
为了便于计算,做一个小小的改动,将 ω ( ω 0 , ω 1 , … , ω d ) \omega(\omega_0,\omega_1,…,\omega_d) ω(ω0,ω1,…,ωd)中的 ω 0 \omega_0 ω0拿出,替换为b。同时省去 x 0 x_0 x0项。假设函数hypothesis就变成了 h ( x ) = s i g n ( ω T x + b ) h(x)=sign(\omega^Tx+b) h(x)=sign(ωTx+b)。
那么,点到分类平面的距离公式为:(推导见视频)
d i s t a n c e ( x , b , w ) = ∣ ω T ∣ ∣ ω ∣ ∣ ( x − x ′ ) ∣ = 1 ∣ ∣ ω ∣ ∣ ∣ ω T x + b ∣ distance(x,b,w)=|\frac{\omega^T}{||\omega||}(x-x')|=\frac{1}{||\omega||}|\omega^Tx+b| distance(x,b,w)=∣∣∣ω∣∣ωT(x−x′)∣=∣∣ω∣∣1∣ωTx+b∣
具体的求距离步骤:
①写出hyperplane ω 1 x 1 + ω 2 x 2 + . . . + ω d x d + b = 0 \omega_1x1+\omega_2x2+...+\omega_dxd+b=0 ω1x1+ω2x2+...+ωdxd+b=0的形式
②求 ∣ ∣ ω ∣ ∣ = ω 1 2 + ω 2 2 + . . . + ω d 2 ||\omega||=\sqrt{\omega_1^2+\omega_2^2+...+\omega_d^2} ∣∣ω∣∣=ω12+ω22+...+ωd2
③将距hyperplane最近的点代入 ω T x = b \omega^Tx=b ωTx=b中
④求③绝对值,代入距离公式计算最终结果
1.3 margin计算公式的简化
为了简化计算,做一个放缩,令距离分类面最近的点满足 y n ( w T x n + b ) = 1 y_n(w^Tx_n+b)=1 yn(wTxn+b)=1。那么我们所要求的margin就变成了:
m a r g i n ( b , w ) = 1 ∣ ∣ w ∣ ∣ margin(b,w)=\frac{1}{||w||} margin(b,w)=∣∣w∣∣1
目标形式简化为:

另外,最大化问题 m a x 1 ∣ ∣ w ∣ ∣ max\frac{1}{||w||} max∣∣w∣∣1可转换为最小化问题 m i n 1 2 ω T ω min\frac{1}{2}\omega^T\omega min21ωTω。
放松条件(放松条件对我们毫无影响,见视频1.3 16:00),最终形式为:

1.4 SVM一般求解方法
现在,SVM的标准问题为:
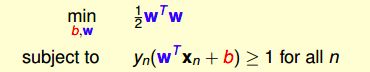
这是一个典型的二次规划问题,即Quadratic Programming(QP)。将SVM与标准二次规划问题的参数一一对应起来,就可以将参数输入一些软件(如matlab)自带的二次规划的库函数求解。

那么,线性SVM算法可以总结为三步:
①计算对应的二次规划参数Q、p、A、c
②根据二次规划库函数,计算 b , ω b, \omega b,ω
③将 b , ω b, \omega b,ω代入 g S V M g_{SVM} gSVM,得到最佳分类面。
1.5 非线性SVM
如果是非线性的,例如包含x的高阶项,那么可以使用在《机器学习基石》课程中介绍的特征转换的方法,先作 z n = Φ ( x n ) z_n=\Phi(x_n) zn=Φ(xn)的特征变换,从非线性的x域映射到线性的z域空间,再利用Linear Hard-Margin SVM Algorithm求解即可。
PS:使用SVM得到large-margin,减少了有效的VC Dimension,限制了模型复杂度;另一方面,使用特征转换,目的是让模型更复杂,减少 E i n E_in Ein。所以,非线性SVM是把这两者的目的结合起来,平衡这两者的关系。
2.Dual Support Vector Machine
2.1 Dual SVM引出
在1.5节中,对于非线性SVM,可以使用非线性变换将变量从x域转换到z域中,再使用线性SVM解决即可。
然而,特征转换下,设求解QP问题在z域中的维度为为 d ^ + 1 \hat d +1 d^+1,如果模型越复杂,则 d ^ + 1 \hat d +1 d^+1越大,相应求解这个QP问题也变得很困难。当 d ^ \hat d d^无限大的时候,问题将会变得难以求解,那么有没有什么办法可以解决这个问题呢?一种方法就是使SVM的求解过程不依赖 d ^ \hat d d^,这就是我们本节课所要讨论的主要内容。
把问题转化为对偶问题,同样是二次规划,只不过变量个数编程N个,有N+1个限制条件。这种对偶SVM的好处就是问题只跟N有关,与 d ^ \hat d d^无关,这样就不存在当 d ^ \hat d d^无限大难以求解的情况。
2.2 Lagrange Function 拉格朗日函数
如何把问题转化为对偶问题?
首先,把SVM的条件问题转换为非条件为题。对于SVM问题,使用拉格朗日乘子法,令朗格朗日因子为 α n \alpha_n αn,构造一个函数:
L ( b , w , α ) = 1 2 w T w + ∑ n = 1 N α n ( 1 − y n ( w T z n + b ) ) L(b,w,\alpha)=\frac12w^Tw+\sum_{n=1}^N\alpha_n(1-y_n(w^Tz_n+b)) L(b,w,α)=21wTw+n=1∑Nαn(1−yn(wTzn+b))
该函数称为拉格朗日函数。
2.3 把SVM构造成非条件问题
下面,利用拉格朗日函数,把SVM构造成一个非条件问题。

该最小化问题中包含了最大化问题,怎么解释呢?首先我们规定拉格朗日因子 α n ≥ 0 \alpha_n\geq0 αn≥0,根据SVM的限定条件可得: ( 1 − y n ( w T z n + b ) ) ≤ 0 (1-y_n(w^Tz_n+b))\leq0 (1−yn(wTzn+b))≤0,如果没有达到最优解,即有不满足 ( 1 − y n ( w T z n + b ) ) ≤ 0 (1-y_n(w^Tz_n+b))\leq0 (1−yn(wTzn+b))≤0的情况,因为 α n ≥ 0 \alpha_n\geq0 αn≥0,那么必然有 ∑ n α n ( 1 − y n ( w T z n + b ) ) ≥ 0 \sum_n\alpha_n(1-y_n(w^Tz_n+b))\geq0 ∑nαn(1−yn(wTzn+b))≥0。对于这种大于零的情况,其最大值是无解的。如果对于所有的点,均满足 ( 1 − y n ( w T z n + b ) ) ≤ 0 (1-y_n(w^Tz_n+b))\leq0 (1−yn(wTzn+b))≤0,那么必然有 ∑ n α n ( 1 − y n ( w T z n + b ) ) ≤ 0 \sum_n\alpha_n(1-y_n(w^Tz_n+b))\leq0 ∑nαn(1−yn(wTzn+b))≤0,则当 ∑ n α n ( 1 − y n ( w T z n + b ) ) = 0 \sum_n\alpha_n(1-y_n(w^Tz_n+b))=0 ∑nαn(1−yn(wTzn+b))=0时,其有最大值,最大值就是我们SVM的目标: 1 2 w T w \frac12w^Tw 21wTw。因此,这种转化为非条件的SVM构造函数的形式是可行的。
2.4 Lagrange Dual SVM
现在,我们已经将SVM问题转化为与拉格朗日因子 α n \alpha_n αn有关的最大最小值形式。已知 α n ≥ 0 \alpha_n\geq0 αn≥0,那么对于任何固定的 α ′ \alpha' α′,且 α n ′ ≥ 0 \alpha_n'\geq0 αn′≥0,一定有如下不等式成立:

对上述不等式右边取最大值,不等式同样成立:

上述不等式表明,我们对SVM的min和max做了对调,满足这样的关系,这叫做Lagrange dual problem。不等式右边是SVM问题的下界,我们接下来的目的就是求出这个下界。
已知 ≥ \geq ≥是一种弱对偶关系,在二次规划QP问题中,如果满足以下三个条件:
-
函数是凸的(convex primal)
-
函数有解(feasible primal)
-
条件是线性的(linear constraints)
那么,上述不等式关系就变成强对偶关系, ≥ \geq ≥变成=,即一定存在满足条件的解 ( b , w , α ) (b,w,\alpha) (b,w,α),使等式左边和右边都成立,SVM的解就转化为右边的形式。
经过推导,SVM对偶问题的解已经转化为无条件形式:
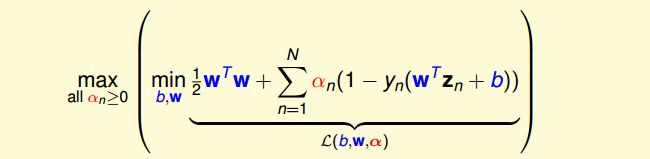
其中,上式括号里面的是对拉格朗日函数 L ( b , w , α ) L(b,w,\alpha) L(b,w,α)计算最小值。那么根据梯度下降算法思想:最小值位置满足梯度为零。首先,令 L ( b , w , α ) L(b,w,\alpha) L(b,w,α)对参数b的梯度为零:
∂ L ( b , w , α ) ∂ b = 0 = − ∑ n = 1 N α n y n \frac{\partial L(b,w,\alpha)}{\partial b}=0=-\sum_{n=1}^N\alpha_ny_n ∂b∂L(b,w,α)=0=−n=1∑Nαnyn
也就是说,最优解一定满足 ∑ n = 1 N α n y n = 0 \sum_{n=1}^N\alpha_ny_n=0 ∑n=1Nαnyn=0。那么,我们把这个条件代入计算max条件中(与 α n ≥ 0 \alpha_n\geq0 αn≥0同为条件),并进行化简:
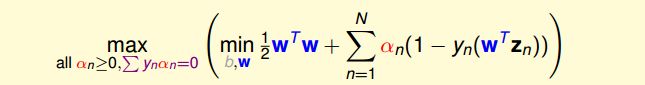
这样,SVM表达式消去了b,问题化简了一些。然后,再根据最小值思想,令 L ( b , w , α ) L(b,w,\alpha) L(b,w,α)对参数w的梯度为零:
∂ L ( b , w , α ∂ w = 0 = w − ∑ n = 1 N α n y n z n \frac{\partial L(b,w,\alpha}{\partial w}=0=w-\sum_{n=1}^N\alpha_ny_nz_n ∂w∂L(b,w,α=0=w−n=1∑Nαnynzn
即得到:
w = ∑ n = 1 N α n y n z n w=\sum_{n=1}^N\alpha_ny_nz_n w=n=1∑Nαnynzn
也就是说,最优解一定满足 w = ∑ n = 1 N α n y n z n w=\sum_{n=1}^N\alpha_ny_nz_n w=∑n=1Nαnynzn。那么,同样我们把这个条件代入并进行化简:
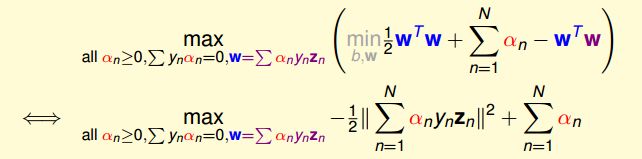
这样,SVM表达式消去了w,问题更加简化了。这时候的条件有3个:
-
all α n ≥ 0 \alpha_n\geq0 αn≥0
-
∑ n = 1 N α n y n = 0 \sum_{n=1}^N\alpha_ny_n=0 ∑n=1Nαnyn=0
-
w = ∑ n = 1 N α n y n z n w=\sum_{n=1}^N\alpha_ny_nz_n w=∑n=1Nαnynzn
SVM简化为只有 α n \alpha_n αn的最佳化问题,即计算满足上述三个条件下,函数 − 1 2 ∣ ∣ ∑ n = 1 N α n y n z n ∣ ∣ 2 + ∑ n = 1 N α n -\frac12||\sum_{n=1}^N\alpha_ny_nz_n||^2+\sum_{n=1}^N\alpha_n −21∣∣∑n=1Nαnynzn∣∣2+∑n=1Nαn最小值时对应的 α n \alpha_n αn是多少。
总结一下,SVM最佳化形式转化为只与 α n \alpha_n αn有关:
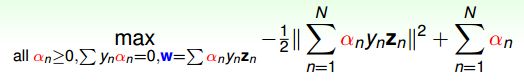
其中,满足最佳化的条件称之为Karush-Kuhn-Tucker(KKT):

在下一部分中,我们将利用KKT条件来计算最优化问题中的 α \alpha α,进而得到b和w。
2.6 解对偶SVM
上面我们已经得到了dual SVM的简化版了,接下来,我们继续对它进行一些优化。首先,将max问题转化为min问题,再做一些条件整理和推导,得到:

显然,这是一个convex的QP问题,且有N个变量 α n \alpha_n αn,限制条件有N+1个。则根据上一节课讲的QP解法,找到Q,p,A,c对应的值,用软件工具包进行求解即可。

求解过程很清晰,但是值得注意的是, q n , m = y n y m z n T z m q_{n,m}=y_ny_mz^T_nz_m qn,m=ynymznTzm,大部分值是非零的,称为dense。当N很大的时候,例如N=30000,那么对应的 Q D Q_D QD的计算量将会很大,存储空间也很大。所以一般情况下,对dual SVM问题的矩阵 Q D Q_D QD,需要使用一些特殊的方法,这部分内容就不再赘述了。

得到 α n \alpha_n αn之后,再根据之前的KKT条件,就可以计算出w和b了。首先利用条件 w = ∑ α n y n z n w=\sum\alpha_ny_nz_n w=∑αnynzn得到w,然后利用条件 α n ( 1 − y n ( w T z n + b ) ) = 0 \alpha_n(1-y_n(w^Tz_n+b))=0 αn(1−yn(wTzn+b))=0,取任一 α n ≠ 0 \alpha_n\neq0 αn̸=0即 α n \alpha_n αn>0的点,得到 1 − y n ( w T z n + b ) = 0 1-y_n(w^Tz_n+b)=0 1−yn(wTzn+b)=0,进而求得 b = y n − w T z n b=y_n-w^Tz_n b=yn−wTzn。

值得注意的是,计算b值, α n \alpha_n αn>0时,有 y n ( w T z n + b ) = 1 y_n(w^Tz_n+b)=1 yn(wTzn+b)=1成立。 y n ( w T z n + b ) = 1 y_n(w^Tz_n+b)=1 yn(wTzn+b)=1正好表示的是该点在SVM分类线上,即fat boundary。也就是说,满足 α n \alpha_n αn>0的点一定落在fat boundary上,这些点就是Support Vector。这是一个非常有趣的特性。