JUC并发容器——ConcurrentHashMap

Hashmap
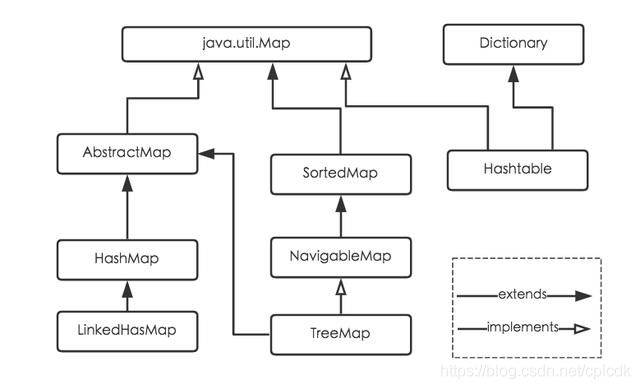
(1) HashMap:它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。
HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。
(2) Hashtable:Hashtable是遗留类,很多映射的常用功能与HashMap类似,不同的是它承自Dictionary类,并且是线程安全的,任一时间只有一个线程能写Hashtable,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。Hashtable不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换。
(3) LinkedHashMap:LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
(4) TreeMap:TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。如果使用排序的映射,建议使用TreeMap。在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException类型的异常。
(5)HashSet: 委托给HashMap
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
内部实现:散列
如何表达键值对?
class Node<K,V> implements Map.Entry<K,V>{
K key;
V value;
}
如何表达键值对的集合?
在java中, 存储一个对象的集合无外乎两种方式:
- 数组
- 链表
在使用键值对时, 查找和插入,删除等操作都会用到, 但是在实际的应用场景中, 对于键值对的查找操作居多, 所以我们当然选择数组形式.
Node<K,V>[] table;
如何有效地根据key值查找value?
数组查找快是因为有索引(index),为了利用索引来查找, 我们需要建立一个 key -> index 的映射关系, 这样每次我们要查找一个 key时, 首先根据映射关系, 计算出对应的数组下标, 然后根据数组下标, 直接找到对应的key-value对象, 这样基本能以o(1)的时间复杂度得到结果.
我们把这样的映射关系称为 散列,:散列是一种面向查找的数据结构。越均匀的散列,性能越好。
如何选择更均匀的散列函数?
有一个最直接的想法:key.hashCode() % table.length,源码基于两种优化:
优化一:
static final int hash(Object key) { //jdk1.8 & jdk1.7
int h;
// h = key.hashCode() 为第一步 取hashCode值
// h ^ (h >>> 16) 为第二步 高位参与运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
优化二:
static int indexFor(int h, int length) { //jdk1.7的源码,jdk1.8没有这个方法,但是实现原理一样的
return h & (length-1); //第三步 取模运算
}
先说优化二:方法二实际上是取模运算。
可以证明:当length总是2的n次方时,
h % 2^n = h & (2^n -1)
在JDK1.8的实现中,优化了高位运算的算法,通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。 这充分利用了高半位和低半位的信息, 对低位进行了 扰动 , 目的是为了使该hashCode映射成数组下标时可以更均匀。详细的解释可以参考这里.
HashMap中key值可以为null, 且null值一定存储在数组的第一个位置.

如何解决hash冲突?
也就是两个Node要存储在数组的同一个位置该怎么办?
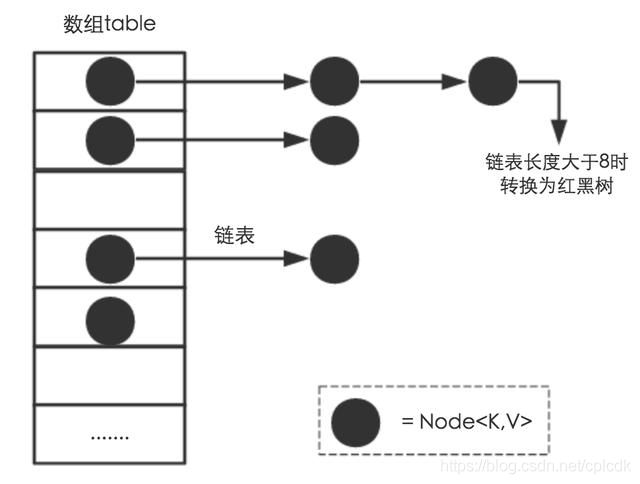
解决hash冲突的方法有很多, 在HashMap中我们选择链地址法, 即在产生冲突的存储桶中改为单链表存储(拓展阅读: 解决哈希冲突的常用方法 )
其实,最理想的效果是,Entry数组中每个位置都只有一个元素,这样,查询的时候效率最高,不需要遍历单链表,也不需要通过equals去比较Key,而且空间利用率最大。
链地址法使我们的数组转变成了链表的数组.
从而也得到了HashMap的实现结构是:数组(hash桶)+链表+红黑树(JDK1.8增加了红黑树部分,解决链表过长的问题)
相应的代码流程如下:

什么时候扩容
数组空间已使用3/4之后, 我们就会括容2倍。
为什么是默认是0.75呢, 官方文档的解释是:
the default load factor (.75) offers a good tradeoff between time and
space costs.
想要看证明的可以看这里.
- 负载因子是可以修改的,也可以大于1,但是建议不要轻易修改,除非情况非常特殊。
- 扩容是一个特别耗性能的操作,所以当程序员在使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。
- 别指望利用链表来扩容, 否则当一个存储桶的中的链表越来越大, 在这个链表上的查找性能就会很差(退化成顺序查找了)
链表存在的意义只是为了解决hash冲突, 而不是为了增大容量. 事实上, 我们希望链表的长度越短越好, 或者最好不要出现链表.
设计初心
我们设计HashMap的初心是什么呢, 是找到一种方法, 可以存储一组键值对的集合, 并实现快速的查找.
==> 为了实现快速查找, 我们选择了数组而不是链表. 以利用数组的索引实现o(1)复杂度的查找效率.
==> 为了利用索引查找, 我们引入Hash算法, 将 key 映射成数组下标: key -> Index
==> 引入Hash算法又导致了Hash冲突
==> 为了解决Hash冲突, 我们采用链地址法, 在冲突位置转为使用链表存储.
==> 链表存储过多的节点又导致了在链表上节点的查找性能的恶化
==> 为了优化查找性能, 我们在链表长度超过8之后转而将链表转变成红黑树, 以将 o(n)复杂度的查找效率提升至o(log n)
==> 为了优化查找性能,我们在数组(也叫做hash桶)超过3/4的时候会自动扩容
ConcurrentHashMap
ConcurrentHashMap是在多线程情况下在线程安全的HashMap,它是一个高性能的线程安全的HashMap。在1.8版本以前,ConcurrentHashMap采用分段锁的概念,使锁更加细化,在jdk1.8以后,是利用CAS+Synchronized来保证并发更新的安全,底层采用数组+链表+红黑树的存储结构。
https://blog.csdn.net/CSDN_bay/article/details/100067700
经典代码
Doug Lea书写这段代码时,流下了许多的经典。
- 构造函数延迟table
- 红黑树实现
- 1.7 分段锁
- 1.8 ConcurrentHashMap
参考文献
https://segmentfault.com/a/1190000015796727#articleHeader3
https://youzhixueyuan.com/the-underlying-structure-and-principle-of-hashmap.html