多线程&JUC:线程池原理、自定义线程池详细解析
作者简介:一位大四、研0学生,正在努力准备大四暑假的实习
上期文章:多线程&JUC:等待唤醒机制(生产者消费者模式)
订阅专栏:多线程&JUC
希望文章对你们有所帮助
线程池是一个比较好玩的东西,在做项目的过程中多少也是接触过的,在高并发的任务执行过程中就会经常自行创建线程池。在这里梳理一下线程池的原理,并且进行实践。
线程池原理、自定义线程池详细解析
- 线程池
- 自定义线程池详细解析
- 最大并行数
- 线程池多大合适
线程池
在之前的多线程程序中,我们需要一个线程进行工作,就需要创建出一个线程对象,等到线程对象的任务执行完毕以后,线程就会自动被回收消失,这种方式其实并不好,这会浪费我们操作系统的资源。
线程池的主要核心:
1、创建一个池子,池子是空的
2、提交任务时,池子会创建新的线程对象,任务执行完毕不会销毁,而是归还给池子。下回再次提交任务时,不需要创建新的线程,直接复用已有的线程即可
3、如果提交任务时,线程池没有空闲线程,就会创建新的线程,不过这有一定的上限,达到上限则无法继续创建新线程,任务就会排队等待
线程池的代码实现:
1、创建线程池
2、提交任务(底层自动完成创建新线程或复用线程)
3、所有的任务全部执行完毕,关闭线程池
创建线程池可以使用工具类Executors,通过调用方法返回不同类型的线程池对象:
| 方法名称 | 说明 |
|---|---|
| public static ExecutorService newCachedThreadPool() | 创建一个没有上限的线程池 |
public static ExecutorService newFixedThreadPool(int nThreads) |
创建有上限的线程池 |
一般还是会创建有上限的线程池。
MyRunnable:
public class MyRunnable implements Runnable{
@Override
public void run() {
for (int i = 1; i <= 100; i++) {
System.out.println(Thread.currentThread().getName() + "@" + i);
}
}
}
测试类:
public class MyThreadPoolDemo {
public static void main(String[] args) {
//获取线程池对象
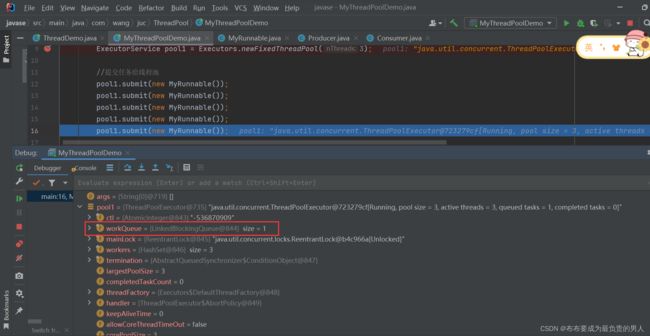
ExecutorService pool1 = Executors.newFixedThreadPool(3);
//提交任务给线程池
pool1.submit(new MyRunnable());
pool1.submit(new MyRunnable());
pool1.submit(new MyRunnable());
pool1.submit(new MyRunnable());
pool1.submit(new MyRunnable());
//销毁线程池
pool1.shutdown();
}
}
调试的时候也可以看到,当提交完4个任务以后,就会有一个任务是无法执行的,即等待状态:
自定义线程池详细解析
Executors自带的两个方法创建线程池很方便,但是不够灵活,因此要掌握如何自定义一个线程池对象。
查看newFixedThreadPool的底层源码,其创建了ThreadPoolExecutor对象,这个就是线程池对象,参数很复杂,所以可以稍微看一下它的英文讲解:
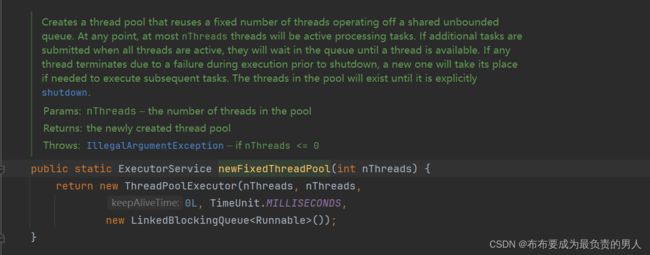
最好的方式就是举个例子:
将线程池当作一个一对一服务的餐厅,即一个员工服务一名客户。
一般状态下,有一定数量的正式员工进行工作,但是当进店的顾客很多的时候,就需要招聘临时员工,若之后临时员工长时间不工作,就会解聘。
在餐厅爆满的时候,我们应该让客户排队等待,应该限定一个排队等待的客户数量,防止后续客户等待时间过长
这样的方式比起Executors中的方法会灵活很多,可以解析出7个核心元素:
1、正式员工数量
2、餐厅最大员工数(正式员工数+临时员工数)
3、临时员工空闲多长时间被辞退(值)
4、临时员工空闲多长时间被辞退(单位)
5、排队的客户
6、从哪里招人
7、当排队人数过多,超出客户拒绝服务
转化为线程池,就是以下7个核心元素:
1、核心线程数量
2、线程池中最大线程的数量
3、空闲时间(值)
4、空闲时间(单位)
5、阻塞队列
6、创建线程的方式
7、要执行的任务过多时的解决方案
基本元素上线程池与餐厅对应起来,但是线程池真正的执行流程和上面的餐厅还是有一些区别的,假设:核心线程:3 临时线程:3 队伍长度:3,有8个任务(1-8)需要执行,则1、2、3被3个核心线程执行,4、5、6排队等待,7、8被2个临时线程执行。
也就是说,临时线程是在阻塞队列满了之后才会创建执行的,同时也说明了任务提交的顺序不代表执行的顺序,就如上述的7、8线程比4、5、6先进去线程池,自然也先执行。
若线程池完全满负荷工作(达到最大线程数,阻塞队列也满),则后面提交的任务就会出发任务拒绝策略,默认为舍弃任务并抛出异常。
/**
* 参数1:核心线程数量 不能小于0
* 参数2、线程池中最大线程的数量 不能小于0,且线程最大数量≥核心线程数量
* 参数3、空闲时间(值) 不能小于0
* 参数4、空闲时间(单位) 用TimeUnit指定
* 参数5、阻塞队列 不能为null
* 参数6、创建线程的方式 不能为null
* 参数7、要执行的任务过多时的解决方案 不能为null
*/
ThreadPoolExecutor pool = new ThreadPoolExecutor(
3,
6,
60,
TimeUnit.SECONDS, //60S
new ArrayBlockingQueue<>(3),
Executors.defaultThreadFactory(), //默认方式创建
new ThreadPoolExecutor.AbortPolicy() //默认方案,这是一个内部类
);
这样就成功实现了线程池的自定义。
总结:不断的提交的任务会有以下三个临界点:
1、核心线程满时,再提交任务就会排队
2、核心线程满,队伍满时,会创建临时线程
3、核心线程满,队伍满,临时线程满时,会触发任务拒绝策略
最大并行数
可以自定义线程池,但是设置为多大是很重要的,它有一些计算公式,在学习计算公式前先了解何为最大并行数。
最大并行数,实际上和我们CPU的型号是有关系的,例如4核8线程的CPU,本地的相关信息是可以查看到的,但是它根本不会把本地的所有CPU资源都交给java虚拟机使用,因此想要查看java虚拟机的最大并行数可以通过写代码:
//getRuntime()获取到系统的运行环境,availableProcessors即可向java虚拟机返回可用处理器的数目
int count = Runtime.getRuntime().availableProcessors();
System.out.println(count);
我的电脑这边的最大并行数为12。
线程池多大合适
这其实是有计算公式的,不过得看项目是什么类型的:
1、CPU密集型运算:I/O操作少,计算多
2、I/O密集型运算:I/O操作多,计算少
在CPU密集型运算的项目中:
线程池大小 = 最大并行数 + 1 线程池大小 = 最大并行数 + 1 线程池大小=最大并行数+1
在I/O密集型运算的项目中:
线程池大小 = 最大并行数 ∗ 期望 C P U 利用率 ∗ 总时间 ( C P U 计算时间 + 等待时间 ) C P U 计算时间 线程池大小=最大并行数*期望CPU利用率*\frac{总时间(CPU计算时间+等待时间)}{CPU计算时间} 线程池大小=最大并行数∗期望CPU利用率∗CPU计算时间总时间(CPU计算时间+等待时间)
对于多线程,就先学这么多,乐观锁、CAS等在项目中用的不算太多,但是面试应该会经常问,需要去看一下面经。