前言
兜兜转转了这么久,数据结构与算法始终是逃不过命题。曾几何时,前端学习数据结构与算法,想必会被认为不务正业,但现今想必大家已有耳闻与经历,面试遇到链表、树、爬楼梯、三数之和等题目已经屡见不鲜。想进靠谱大厂算法与数据结构应该不止是提上日程那么简单,可能现在已经是迫在眉睫。这次决定再写一个系列也只是作为我这段时间的学习报告,也不绝对不会再像我之前的vue原理解析那般断更了,欢迎大家监督~
学数据结构与算法的最好时机是十年前,其次就是现在。
什么是数据结构与算法?
例如书店里的书可以以年代作为区分摆放,可以以作家个人为区分摆放,也可以以类型作为区分摆放,这么摆的目的就是为了高效的找到心仪的书,这就是数据结构;又例如你借了一摞书准备走出书店,其中有一本忘了登记,如何快速找出那本书?你可以一本本的尝试,也可以每一次直接就检测半摞书,再剩下的半摞书依然如此,这样12本书,你只用4次即可,而这就是算法。
再举个例子,计算数字从1到100之和,使用循环我们可能会写出这样的程序:
let res = 0
for (let i = 1; i <= 100; i++) {
res += i
}
return res如果这里的100变成了十万、百万,那么这里计算量同样也会随之增加,但是如果使用这样一个求和的公式:
100 * (100 + 1) / 2 无论数字是多大,都只需要三次运算即可,算法可真秒!同样数据结构与算法是相互依存的,数据结构为什么这么存,就是为了让算法能更快的计算。所以首先需要了解每种数据结构的特性,算法的设计很多时候都需要基于当前业务最合适的数据结构。
为什么要学习数据结构与算法?
谈谈我个人的见解,首先当然是环境的逼迫,大厂都再考这些,人人又想进大厂,而大厂又为了增加筛选的效率。其次学习之后可以开阔解决问题的眼界,多指针、二分查找、动态规划;树、链表、哈希表,这一坨数据为什么要用这么麻烦的方式的存储?这些都可以拓展我们编写程序的上限。当然所有的这些都指向同一个问题:
如何高效且节约存储空间的完成计算任务
现在才明白,原来代码不全是写的越短越简洁效率就越高;原来同样一个问题,不同的解法效率可能有成百上千倍的差距;原来时间和空间不可兼得,总得牺牲其中的一个性能。
最后就是复杂应用对数据结构和算法的应用,个人学习中所知的,如九宫格输入法的拼音匹配、编辑器里括号的匹配、浏览器历史记录前进和后退的实现、vue组件keep-alive的LRU缓存策略等,这些都需要对数据结构与算法有了解才行。可能日常的开发中所用甚少,不过增加对复杂问题的抽象与理解总是有益处的,毕竟程序员的价值体现就是解决问题。
如果评判一段程序运行时间?
例如我们再leetcode上解题,当获取一个通过时,你编写的题解的用时与内存超过的百分比是越高越好,那为什么一段程序有那么大的区别?这个时候我们就要理解评断程序执行效率的标准,毕竟不能等每段程序都运行完了之后去看执行时间来评判,执行之前我们要用肉眼粗略能看出个大概。
大O复杂度表示法
可以看接下来这段代码:
function test (n) {
const a = 1
const b = 2
let res = 0
for (let i = 0; i < n; i++) {
res += i
}
} 站在程序执行的角度来看,这段程序会分别执行一次a = 1以及b = 2,接下来会执行一段循环,for循环执行了两次n遍的运算(i++以及res += i),这段程序一共执行了2n + 2次,如果用大O表示法,这段程序的时间复杂度可以表示为O(2n + 2),(大O的具体理论及公式网上很多,大家可自行搜索)。简单来说, 大O表示法的含义是代码执行时间随数据规模增长而增长的趋势, 也就是这段代表的执行运行耗时,常数级别的操作对趋势的影响甚少,会被直接无视。所以上面的O(2n + 2)可以直接看成是O(n),因为只有n影响到了趋势。接下里再看一段代码:
function test (n) {
let sum1 = 0
for (let i = 1; i <= 1000; i++) { // O(1)
sum += i
}
let sum2 = 0
for (let i = 1; i <= n; i *= 2) { // O(logn)
sum2 += i
}
let sum3 = 0
for (let i = 1; i <= n; i++) { // O(n)
sum3 += i
}
let sum4 = 0
for (let i = 1; i <= n; i++) { // O(n²)
for(let j = 1; j <= n; j++) {
sum4 += i + j
}
}
}上面这段代码的时间复杂度是多少了?
首先看第一段1000次的循环,表示是O(1000),但是与趋势无关,所以只是常数级别的,只能算做的O(1);
再看第二段代码,每一次的不再是+1,而是x2,i的增长为1 + 2 + 4 + 8 + ...次,也就是i经过几次乘2之后到了n的大小,这也就是对数函数的定义,时间复杂度为log₂n,无论底数是多少,都是用大O表示法为O(logn);
再看第三段n次的循环,算做是O(n);
第四段相当于是执行了n * n次,表示为O(n²)。
最后相加它们可以表示为O(n² + n + logn + 1000),不过 大O表示法会在代码所有的复杂度中只取量级最大的, 所以总的时间复杂度又可以表示为O(n²)。
几种常见的时间复杂度
相信看了上面两段代表,大家已经对复杂度分析有了初步的认识,接下来我们按照运行时间从快到慢,整体的解释下几种常见的复杂度:
O(1): 常数级别,不会影响增长的趋势,只要是确定的次数,没有循环或递归一般都可以算做是O(1)次。O(logn): 对数级别,执行效率仅次于O(1),例如从一个100万大小的数组里找到一个数,顺序遍历最坏需要100万次,而logn级别的二分搜索树平均只需要20次。二分查找或者说分而治之的策略都是这个时间复杂度。O(n): 一层循环的量级,这个很好理解,1s之内可以完成千万级别的运算。O(nlogn): 归并排序、快排的时间复杂度,O(n)的循环里面再是一层O(logn),百万数的排序能在1s之内完成。O(n²): 循环里嵌套一层循环的复杂度,冒泡排序、插入排序等排序的复杂度,万数级别的排序能在1s内完成。O(2ⁿ): 指数级别,已经是很难接受的时间效率,如未优化的斐波拉契数列的求值。O(!n): 阶乘级别,完全不能尝试的时间复杂度。
知道自己写的代码的时间复杂度这个很重要,leetcode有的题目会直接说明数据的规模,通过数据规模大致可以知道需要在什么级别之内解出这个题,否则就会超时。
其他几种复杂度分析
以上说的时间复杂度指的是一段程序的平均时间复杂度,其实还会有最坏时间复杂度,最好时间复杂度以及均摊时间复杂度。
- 最好时间复杂度:例如我们要从数据里找到一个数字,数组的第一项就符合要求,这个时候就表示数组取值最好的时间复杂度是
O(1),当然了这种概率是极低的,所以并不能作为算法复杂度的指导值。 - 最坏时间复杂度:数组取值直到最后一个才找到符合要求的,那就是需要
O(n)的复杂度;又例如快排的平均时间复杂度是O(nlogn),但一个没经过优化的快排去处理一个已经排好序的数组,会退化成O(n²)。 - 均摊时间复杂度:表示的是一段程序出现最坏和最好的频次不同,这个时候复杂度的分析就是将它们的操作进行均摊,取频次的多操作,然后得出最终的复杂度。
空间复杂度分析
如果能理解时间复杂度的分析,那么空间度的分析就会显示的格外的好理解。它指的是一段程序运行时,需要额外开辟的内存空间是多少,我们来看下这段程序:
function test(arr) {
const a = 1
const b = 2
let res = 0
for (let i = 0; i < arr.length; i++) {
res += arr[i]
}
return res
}我们定义了三个变量,空间复杂度是O(3),又是常数级别的,所以这段程序的空间复杂度又可以表示为O(1)。只用记住是另外开辟的额外空间,例如额外开辟了同等数组大小的空间,数组的长度可以表示为n,所以空间复杂度就是O(n),如果开辟的是二维数组的矩阵,那就是O(n²),因为空间度基本也就是以上几种情况,计算会相对容易。
递归函数的时间复杂度分析
如果一个递归函数再每一次调用自身时,只是调用自己一次,那么它的时间复杂度就是这段递归调用栈的最大深度。这么说可能比较不好理解,我们看这段代码:
function reversetStr (s) {
if (s === '') {
return ''
}
return s[s.length - 1] + reversetStr(s.slice(0, -1))
}使用递归对一段字符串进行翻转,因为每次调用都会截取字符串的最后一位,所以这段程序的递归调用次数就是递归的深度,也就是字符串自身的长度,也就是O(n),这也是递归最简单的调用,每一次只调用自身一次;接下来我们使用递归求解斐波拉契数列,也就是这样的一堆数,后面一个数等于前面两个之和:
1 1 2 3 5 8 13 21 34 55 89 ...
function fib (n) {
if (n === 1 || n === 2) {
return n
}
return fib(n - 1) + fib(n - 2)
}这个递归函数在调用自身的时,又调用了两次自身,那是不是说明这段递归函数的时间复杂度是O(n²)?简单的画一下这个递归函数的调用树,大家也就会看的更加明白,以n为7为例: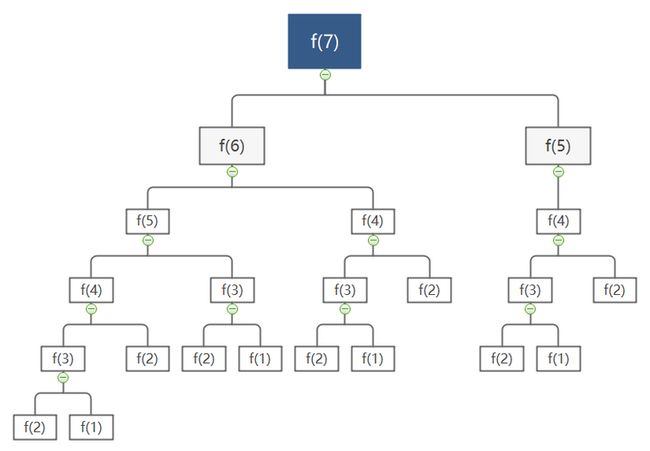
我们可以看到,当要计算7时,需要计算出6和5;当要计算6和5时,又要分别计算出5和4以及4和3;每次这颗递归树展开的叶子节点都是上一层的两倍,也就说这是一个指数级的算法,时间复杂度为O(2ⁿ)。
最后
下面这段代码每次都会出队数组的第一个元素,那下面这段代码的时间复杂度是多少?
function test(arr) {
let len = arr.length
for (let i = 0; i < len; i++) {
arr.shift()
}
}