什么是IPFS
IPFS(InterPlanetary File System 星际文件系统) 是一个旨在创建持久且分布式存储和共享文件的网络传输协议。它是一种内容可寻址的对等超媒体分发协议。IPFS网络中的节点将构成一个分布式文件系统(类似BitTorrent)。
IPFS协议利用比特币区块链协议和网络基础设施的优势来存储不可更改的数据,移除网络上的重复文件,以及获取存储节点的地址信息——用以搜索网络中的文件。
IPFS是一个对等的分布式文件系统,它尝试为所有计算设备连接同一个文件系统。在某些方面,IPFS类似于万维网,但它也可以被视作一个独立的BitTorrent群、在同一个Git仓库中交换对象。因此,IPFS被认为在未来有可能取代HTTP协议。
最简单的总结就是,它是一个分布式文件存储项目,同时也是一个底层协议。IPFS当前的一个实现采用Go和JavaScript,并有Python的实现正在发展。
IPFS的特征
IPFS = HTTP + git + BitTorrent
其显著特性有:
- 永久的、去中心化保存和共享文件 (区块链模式下的存储Distributed HashTable)
- 点对点超媒体:P2P 保存各种各样类型的数据(BitTorrent)
- 版本化:可追溯文件修改历史(Git - Merkle DAG默克尔有向无环图))
- 内容可寻址:通过文件内容生成独立哈希值来标识文件,而不是通过文件保存位置来标识。相同内容的文件在系统中只会存在一份,节约存储空间 (区块链模式)
IPFS是一个版本化的分布式文件系统(类似git)
具有git等分布式版本控制系统的特性:提供上传下载文件等管理功能、能跟踪文件版本的变化且自动删除重复的文件版本的理解:对同一个文件修改,提交到ipfs后产生的是新的文件,旧的文件还会存在,这样,在ipfs库里就记录了两个版本(旧版和新版),记录了多个版本,自然就方便不同的版本的切换。
我们常用的版本控制软件比如svn ,git。
- svn是c/s架构,s端(服务端)出现问题,那么意味着svn就不能用了
- git有个最大的好处是每个开发者的电脑即是客户端也是服务器(P2P网络),就不存在单点故障的问题(服务器出现故障就不能访问的问题)
同时,IPFS的版本化特征还有一个好处就是自动去重,比如有两个目录,a和b ,a目录里有文件a1 b目录里也有a1 ,在ipfs只会记录一个a1
IPFS的数据存储
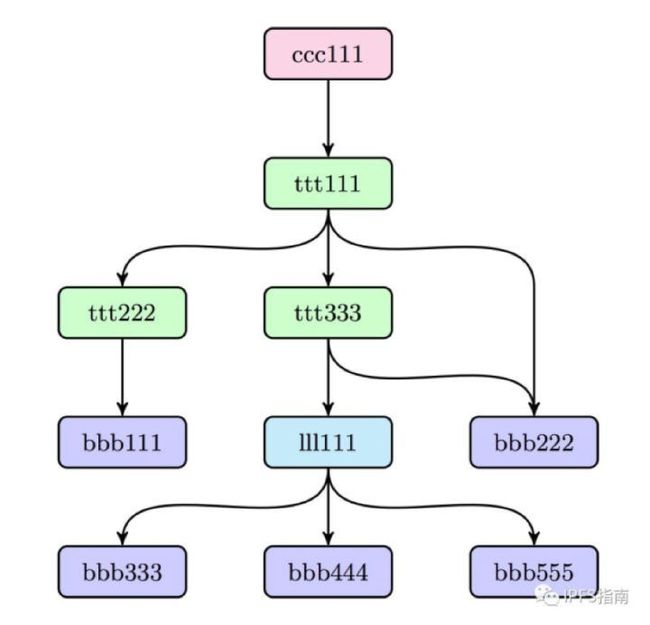
- 存储方式: 它是分布式存储的, 为了方便传输,文件被切分成多个block, 每个block 通过hash运算得到唯一的ID, 方便在网络中进行识别和去重。 考虑到传输效率, 同一个block 可能有多个copy, 分别存储在不同的网络节点上。
- 内容寻址方式: 每个block都有唯一的ID,我们只需要根据节点的ID 就可以获取到它所对应的block。
IPFS可溯源的保存与共享文件是利用了区块链系统的;内容可寻址则是利用了区块链的中的Merkle DAG,与RLP编码快速验证重复内容以及快速定位内容特性有点相似。简单来说, 就是2种数据结构merkle 和DAG(有向无环图)的结合
- 内容寻址: 使用hash ID来唯一识别一个数据块的内容
- 防篡改: 可以方便的检查哈希值来确认数据是否被篡改
- 去重: 由于内容相同的数据块哈希是相同的,可以很容去掉重复的数据,节省存储空间
IPFS的数据分发
如何把数据分发到不同的网络节点上, 达到分布式存储和共享的目的? 我们先思考一下, 通过网络,比如HTTP, 访问某个文件的步骤,
- 首先我们要知道存储这个文件的服务器地址,
- 然后我们需要知道这个文件对应的ID,
- 比如文件名。前者我们可以抽象成网络节点寻址,
- 后者我们抽象成文件对象寻址;
很多P2P网络的实现都采用DHT分布式哈希表的方式实现查找,其中Kademlia(简称Kad)算法由于其简单性、灵活性、安全性成为主流的实现方式,其结构与字典树有些相似。在IPFS中,这两种寻址方式使用了相同的算法: KAD
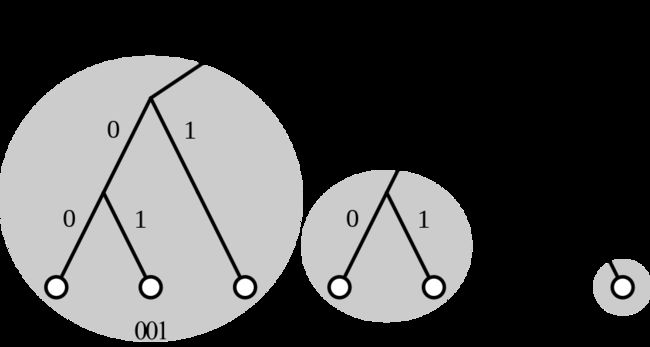
通过KAD算法,IPFS 把不同ID的数据块分发到与之距离较近的网络节点中,达到分布式存储的目的。
通过IPFS获取文件时,只需要根据merkledag, 按图索骥,根据每个block的ID, 通过KAD算法从相应网络节点中下载block数据, 最后验证是否数据完整, 完成拼接即可。
 IPFS的系统架构
IPFS的系统架构
IPFS的系统架构图,除去应用层之外, 从中间到下面,分为5层:
- 一层为naming, 基于PKI的一个命名空间;
- 第二层为merkledag, IPFS 内部的逻辑数据结构;
- 第三层为exchange, 节点之间block data的交换协议;
- 第四层为routing, 主要实现节点寻址和对象寻址;
- 第五层为network, 封装了P2P通讯的连接和传输部分。
站在数据的角度来看, 又可以分为2个大的模块:
- IPLD( InterPlanetary Linked Data) 主要用来定义数据, 给数据建模;
- libp2p 解决数据如何传输的问题。
IPLD(InterPlanetary Linked Data)描述数据
通过hash 值来实现内容寻址的方式在分布式计算领域得到了广泛的应用, 比如区块链, 再比如git repo。 虽然使用hash 连接数据的方式有相似之处, 但是底层数据结构并不能通用, IPFS 是个极具野心的项目, 为了让这些不同领域之间的数据可互操作, 它定义了统一的数据模型IPLD, 通过它, 可以方便地访问来自不同领域的数据。
数据的逻辑结构是用merkledag表示的, 那么它是如何实现的呢? 围绕merkledag作为核心, 它定义了以下几个概念:
- merkle link 代表dag 中的边
- merkel-dag 有向无环图
- merkle-path 访问dag节点的类似unix path的路径
- IPLD data model 基于json 的数据模型
- IPLD serialized format 序列化格式
- canonical 格式: 为了保证同样的logic object 总是序列化为一个同样的输出, 而制定的确定性规则
围绕这些定义它实现了下面几个components
- CID 内容ID
- data model 数据模型
- serialization format 序列化格式
- tools & libraries 工具和库
- IPLD selector 类似CSS 选择器, 方便选取dag中的节点
- IPLD transformation 对dag 进行转换计算
同时,数据是多样性的,为了给不同的数据建模, 我们需要一种通用的数据格式, 通过它可以最大程度地兼容不同的数据, IPFS 中定义了一个抽象的集合, multiformat, 包含multihash、multiaddr、multibase、multicodec、multistream几个部分。具体每个数据设计不赘述,我们把目光放回IPFS是如何定义数据的
IPLD 是IPFS 的数据描述格式, 解决了如何定义数据的问题
下面这张图是结合源代码整理的一份逻辑图,我们可以看到上面是一些高级的接口, 比如file, mfs, fuse 等。 下面是数据结构的持久化部分,节点之间交换的内容是以block 为基础的, 最下面就是物理存储了。比如block 存储在blocks 目录, 其他节点之间的信息存储在leveldb, 还有keystore, config 等。

lipP2P 传输数据
libP2P 是个模块化的网络协议栈,和socket传输数据类似
- 获取目标服务器地址
- 和目标服务器建立连接
- 握手协议
- 传输数据
- 关闭连接
libP2P将其进行模块化,定义了通用的接口, 可以很方便的进行扩展。
分别是:
- Peer Routing 路由
- Swarm (传输和连接)
- Distributed Record Store 记录存储
- Discovery 发现
Peer Routing
libP2P定义了routing 接口,目前有2个实现,分别是KAD routing 和 MDNS routing
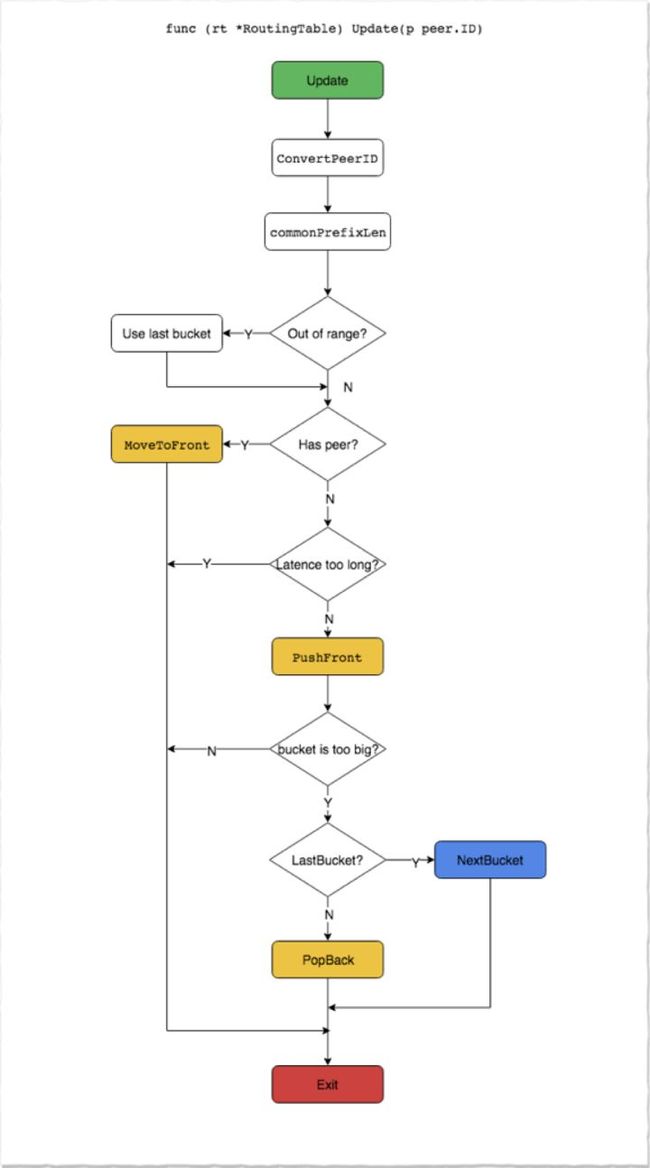
ipfs 中的节点路由表是通过维护多个K-BUCKET来实现的
- 每次新增节点, 会计算节点ID 和自身节点ID 之间的common prefix,
- 根据这个公共前缀把节点加到对应的KBUCKET 中, KBUCKET 最大值为20,
- 当超出时,再进行拆分
更新路由表的流程如下:
除了KAD routing 之外, IPFS 也实现了MDNS routing, 主要用来在局域网内发现节点, 这个功能相对比较独立, 由于用到了多播地址, 在一些公有云部署环境中可能无法工作。
Swarm(传输和连接)
swarm 定义了以下接口:
- transport 网络传输层的接口
- connection 处理网络连接的接口
- stream multiplex 同一connection 复用多个stream的接口
动态协商stream protocol,和socket的三次握手相似,多出了协议部分内容
- 默认先通过multistream-select 完成握手
- 发起方尝试使用某个协议, 接收方如果不接受, 再尝试其他协议, 直到找到双方都支持的协议或者协商失败。
另外为了提高协商效率, 也提供了一个ls 消息,用来查询目标节点支持的全部协议。
Distributed Record Store
record 表示一个记录, 可以用来存储一个键值对,比如ipns name publish 就是发布一个objectId 绑定指定 node id 的record 到ipfs 网络中, 这样通过ipns 寻址时就会查找对应的record, 再解析到objectId, 实现寻址的功能。
Discovery
目前系统支持3种发现方式, 分别是:
bootstrap 通过配置的启动节点发现其他的节点
random walk 通过查询随机生成的peerID, 从而发现新的节点
mdns 通过multicast 发现局域网内的节点
bootstrap与repo仓库的关系
当要向ipfs申请数据时,ipfs先会去本地的repo目录下去查找需要的数据,repo目录里的数据分两部分,一部分是metadata(元数据)一部分是block数据(真正的内容)。metadata想像成是商店的账本,账本上记录了所有商店的产品清单(目录),而block就是摆放在商店里的具体的内容。
如果ipfs只是通过自己的仓库查找数据,那就太狭隘了,ipfs还会根据bootstrap 列表,了解网络上其他节点的对等体列表,如果自己的仓库里没有需要的数据,就通过bootstrap列表,查到其它的节点是否有需要的数据。 IPFS自带有默认的受信任对等列表。
总的来说
总的来说,IPFS实现的协议如下图:
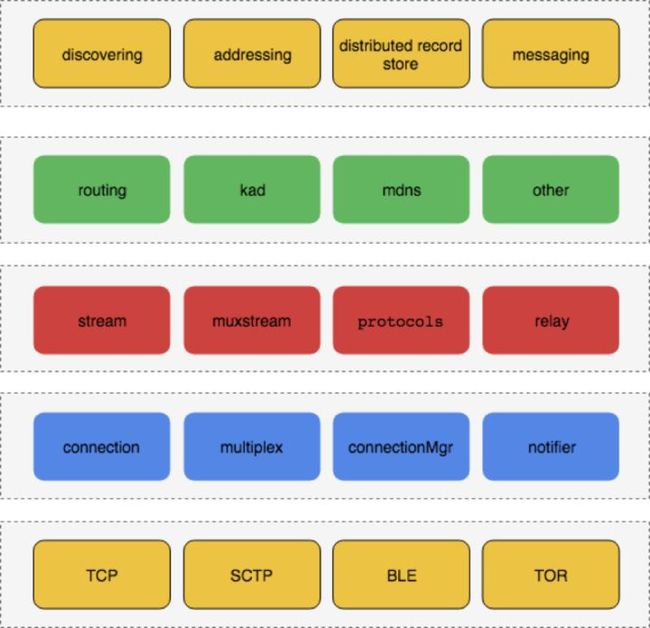
从下到上分为5个层次:
- 最底层为传输层, 主要封装各种协议, 比如TCP,SCTP, BLE, TOR 等网络协议
- 传输层上面封装了connection连接层,实现连接管理和通知等功能
- 连接层上面是stream 层, 实现了stream的多路复用
- stream层上面是peer routing路由层
- 最上层是discovery, messaging以及record store 等
本文从定义数据和传输数据的角度分别介绍了IPFS的2个主要模块IPLD 和 libP2P:
- IPLD 主要用来定义数据, 给数据建模
- libP2P 解决数据传输问题
IPFS的远景目标就是替换现在浏览器使用的 HTTP 协议, 目前项目还在迭代开发中, 一些功能也在不断完善。为了解决数据的持久化问题, 引入了filecoin 的token激励机制,和区块链中的token一样,其根本作用是 通过token激励,让更多的节点加入到网络中来,从而提供更稳定的服务。
附录
本文引用:
美图技术团队: 从数据的角度带你深入了解IPFS
https://zhuanlan.zhihu.com/p/37455540 2018-05-31百度百科: 星际文件系统IPFS https://baike.baidu.com/item/%E6%98%9F%E9%99%85%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F/22695381?fr=aladdin 2019-08-18
xutaotao: 通过三大机制揭秘IPFS的工作原理 https://www.jianshu.com/p/e4703ad30f65 2018-05-26
xutaotao: HTTP+git+BitTorrent=IPFS https://www.jianshu.com/p/74d5b11cc365 2018-05-24