TensorFlow快速上手实战和可视化
目录
前期准备
实例:训练一元方程
Session
Variable
placehoder
优化器(Optimizer)
实战进阶:灵活使用TensorFlow
添加神经层
建造你的神经网络
结果可视化
全程可视化:tensorboard的使用
关于学习任何一门编程,我的建议是:直接动手干,不要花时间系统去学!一边实践一边学习,进步才最快。等有1~2个项目的实践经历后,再回头系统学习,读一些系统的书籍,事半功倍。现在直接系统地学,很多部分你也看不懂。
前期准备
首先请保证你已经安装了python的开发环境和TensorFlow。
如果还没有的话,请看:傻瓜教程:MacOS系统安装Anaconda+Spyder+TensorFlow
最好,你还能初步了解一些TensorFlow的基本内容:TensorFlow:编程模型和重要基本概念,然后我们就可以开始实战了。
实例:训练一元方程
我们举个例子,我们要让一堆随机的初始数据经过TensorFlow框架下的学习训练后,输出y=0.1x+0.3。
import tensorflow as tf
import numpy as np
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data*0.1 + 0.3
#w和b的初始值
Weights = tf.Variable(tf.random_uniform([1],-1.0,1.0))
biases = tf.Variable(tf.zeros([1]))
y = Weights*x_data + biases
loss = tf.reduce_mean(tf.square(y-y_data))
#建立优化器
optimizer = tf.train.GradientDescentOptimizer(0.5) #学习率,小于1的数,这里取0.5
train = optimizer.minimize(loss) #这里定义了train的算式,即要做什么:使得loss最小!
#初始化我们的变量 使我们设计的学习结构活动起来
init = tf.initialize_all_variables()
sess = tf.Session() #创建一个session
sess.run(init)
for step in range(201): #迭代201次
sess.run(train)
if step % 20 == 0: #每隔20次输出一次信息
print(step,sess.run(Weights),sess.run(biases))上面程序输出是:

发现输出非常接近0.1和0.3了。
当然,因为你还没有系统地学习TensorFlow,目前你不需要深入理解如优化器、初始化等一系列操作的底层原理,你只需要知道它是用来干什么的、能产生什么样的结果,会使用就可以。具体的我们会在之后学习过程中细讲。
上面程序中出现的一些你必须要知道的TensorFlow框架下的知识点:
Session
TensorFlow中的对话模块,or人机会话接口,执行已经创建好的计算图或某些部分。一般很多tf框架下语句都要run一下才可以生效。
例如:计算两个矩阵相乘:
import tensorflow as tf
matrix1 = tf.constant([[3, 3]])
matrix2 = tf.constant([[2],
[2]])
product = tf.matmul(matrix1, matrix2) # matrix multiply np.dot(m1, m2)
# method 1
sess = tf.Session() #创建session
result = sess.run(product) #通过session来运行部分图
print(result)
sess.close() #关闭会话
# method 2
with tf.Session() as sess: #通过with 自动关闭这次会话 降低内存占用
result2 = sess.run(product)
print(result2)Variable
通过tf.Variable定义TensorFlow框架下的变量。
举个例子:
import tensorflow as tf
state = tf.Variable(0, name='counter')
#print(state.name)
one = tf.constant(1)
new_value = tf.add(state, one) #变量加常量1
update = tf.assign(state, new_value) #把new_value赋给state
init = tf.initialize_all_variables()
# 这一步很重要。如果你设置了变量,一定要初始化所有变量 (用session run一下才能生效)
with tf.Session() as sess:
sess.run(init)
for _ in range(3): #3次循环,_此处无实际意义
sess.run(update)
print(sess.run(state)) #注意这里不能直接print(state) 要先run后才能生效除此之外,你还应该掌握的常用的TensorFlow的内容:
placehoder
先开辟一个空间,之后再从外界传入值。用feed_dict传入,它是一个键值对形式的字典,如feed_dict={input1: [7.0], input2: [2.0]}。
import tensorflow as tf
#创建placehoder 就可以先不输入值
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
ouput = tf.multiply(input1, input2)
with tf.Session() as sess:
#用feed_dict,字典的形式传入值
print(sess.run(ouput, feed_dict={input1: [7.0], input2: [2.0]})) 优化器(Optimizer)
TensorFlow提供了不同的优化器。初学者使用GradientDescentOptimizer即可。Momentum、Adam是另外两个常用的优化器。
了解其他优化器,参见:https://www.jianshu.com/p/e6e8aa3169ca。其实不同之处就是对学习率做了不同的定义或限制。
实战进阶:灵活使用TensorFlow
上面讲了一些基础的东西。接下来我们将学习稍微更复杂,更强大的TensorFlow的内容:
添加神经层
import tensorflow as tf
#定义一个添加层的函数
def add_layer(inputs, in_size, out_size, activation_function=None):
# =None意思是 调用时缺省值是None
#生成一个权重的矩阵,随机值比都是0好
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
# b是1行,out_size列的矩阵 推荐初始值不为0
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
#定义计算式子
Wx_plus_b = tf.matmul(inputs, Weights) + biases
#设置激活函数
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b) #将Wx_plus_b传入作为真正激活函数的参数
return outputs建造你的神经网络
继续上面的代码,我们可以搭建自己的一个神经网络了。边做边学,每一个知识点旁边我都写了注释:
# Make up some real data
x_data = np.linspace(-1,1,300)[:, np.newaxis] #300行,-1到1之间均匀分布的数据,np.newaxis使它输出多行一列形式
#一般来说,每一行表示一个样本,每一列表示样本中的一个特征。所以这里每个输入的样本就1个特征。
noise = np.random.normal(0, 0.05, x_data.shape)
y_data = np.square(x_data) - 0.5 + noise #加一个噪声使得它更像现实数据
# define placeholder for inputs to network
xs = tf.placeholder(tf.float32, [None, 1]) #None表示无论输入多少个样本都可以,1是因为就1个特征属性。
ys = tf.placeholder(tf.float32, [None, 1])
# add hidden layer
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
# add output layer
prediction = add_layer(l1, 10, 1, activation_function=None)
# the error between prediciton and real data
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1])) #reduction_indices表示求和的指数,2表示平方和,3表示立方和,以此类推。
#定义训练的工作。建立优化器,设置训练目标。
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 初始化所有变量和生效
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
for i in range(1000):
# training 使用全部的x和y的数据进行训练
sess.run(train_step, feed_dict={xs: x_data, ys: y_data})
if i % 50 == 0:
# to see the step improvement
print(sess.run(loss, feed_dict={xs: x_data, ys: y_data})) 可以看到该程序的loss输出是一直在减小的:
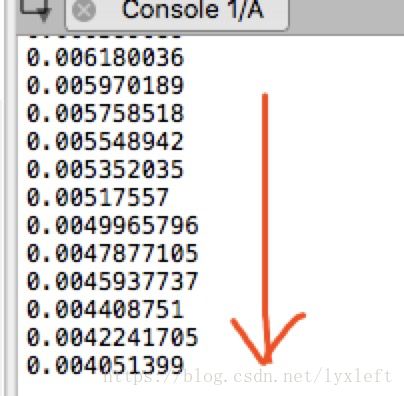
说明训练效果越来越好了,我们即将可以得到y关于x的拟合方程式。
结果可视化
import matplotlib.pyplot as plt :导入输出结果可视化的模块
在上一个程序的后半段,稍作修改:
# plot the real data
fig = plt.figure() #生成一个图片框
ax = fig.add_subplot(1,1,1)
ax.scatter(x_data, y_data) #先把真实的数据画上来
plt.ion() #打开交互模式,使连续画图不暂停。只用show()的话画一次就会暂停
plt.show()
#做一个动态变化的拟合曲线:
for i in range(1000):
# training
sess.run(train_step, feed_dict={xs: x_data, ys: y_data})
if i % 50 == 0:
# to visualize the result and improvement
try:
ax.lines.remove(lines[0]) #在图片中去除掉上一条线;用try防止报错
except Exception:
pass
prediction_value = sess.run(prediction, feed_dict={xs: x_data})
# plot the prediction
lines = ax.plot(x_data, prediction_value, 'r-', lw=5) #曲线形式绘图,线的宽度为5
plt.pause(0.1) #暂停0.1s再继续画下一条线全程可视化
我们要借助一些工具进行整个网络结构的可视化工作。这里推荐:tensorboard。
补充文献:tensorboard详解:https://zhuanlan.zhihu.com/p/36946874,有空可以深入看一看。
我们直接上手干了,在上一个程序基础上做修改:
1)根据逻辑,大量使用with语句,形成层次结构
2)使用writer = tf.summary.FileWriter("logs/", sess.graph) 保存图
import tensorflow as tf
def add_layer(inputs, in_size, out_size, activation_function=None):
# add one more layer and return the output of this layer
# 画图时注意包含和被包含的逻辑关系
# 利用with框架来实现包含
with tf.name_scope('layer'):
with tf.name_scope('weights'):
Weights = tf.Variable(tf.random_normal([in_size, out_size]), name='W')
with tf.name_scope('biases'):
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='b')
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.add(tf.matmul(inputs, Weights), biases)
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b, )
return outputs
# define placeholder for inputs to network
with tf.name_scope('inputs'): #将xs ys装到父类inputs下面
xs = tf.placeholder(tf.float32, [None, 1], name='x_input')
ys = tf.placeholder(tf.float32, [None, 1], name='y_input')
# add hidden layer
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
# add output layer
prediction = add_layer(l1, 10, 1, activation_function=None)
# the error between prediciton and real data
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
with tf.name_scope('train'):
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
sess = tf.Session()
#很重要 把整个图加载到文件中去
writer = tf.summary.FileWriter("logs/", sess.graph)
sess.run(tf.initialize_all_variables())打开位于输出文件夹的终端。(新建终端,用cd命令打开到代码存放的文件夹)
输入tensorboard --logdir = 'logs/',然后在浏览器中输入http://localhost:6006,即可查看到。
除了要看网络结构之外,我们可能还想看参数的可视化,比如loss、weights等。
对代码添加一些修改:
import tensorflow as tf
import numpy as np
def add_layer(inputs, in_size, out_size, n_layer, activation_function=None):
# add one more layer and return the output of this layer
layer_name = 'layer%s' % n_layer
with tf.name_scope(layer_name):
with tf.name_scope('weights'):
Weights = tf.Variable(tf.random_normal([in_size, out_size]), name='W')
tf.summary.histogram(layer_name + '/weights', Weights)
with tf.name_scope('biases'):
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='b')
tf.summary.histogram(layer_name + '/biases', biases)
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.add(tf.matmul(inputs, Weights), biases)
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b, )
tf.summary.histogram(layer_name + '/outputs', outputs)
return outputs
# Make up some real data
x_data = np.linspace(-1, 1, 300)[:, np.newaxis]
noise = np.random.normal(0, 0.05, x_data.shape)
y_data = np.square(x_data) - 0.5 + noise
# define placeholder for inputs to network
with tf.name_scope('inputs'):
xs = tf.placeholder(tf.float32, [None, 1], name='x_input')
ys = tf.placeholder(tf.float32, [None, 1], name='y_input')
# add hidden layer
l1 = add_layer(xs, 1, 10, n_layer=1, activation_function=tf.nn.relu)
# add output layer
prediction = add_layer(l1, 10, 1, n_layer=2, activation_function=None)
# the error between prediciton and real data
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
tf.summary.scalar('loss', loss)
with tf.name_scope('train'):
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
sess = tf.Session()
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("logs/", sess.graph)
# important step
sess.run(tf.initialize_all_variables())
for i in range(1000):
sess.run(train_step, feed_dict={xs: x_data, ys: y_data})
if i % 50 == 0:
result = sess.run(merged,
feed_dict={xs: x_data, ys: y_data})
writer.add_summary(result, i)
即可得到:

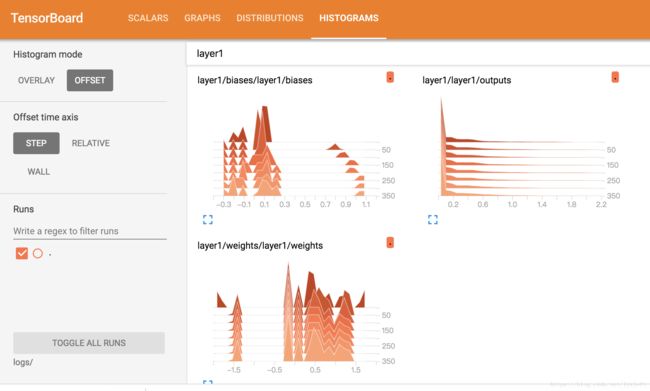
具体来讲,tf.summary的一些功能参见:https://blog.csdn.net/hongxue8888/article/details/79753679
