分布式日志sleuth+分布式追踪系统zipkin+消息中间件rabbitMQ+MySQL存储跟踪数据
一、了解分布式架构下系统的监控问题
接口监控问题
监测性能瓶颈
解决方案:Sleuth
日志监控问题
日志分散
解决方案:ELK+Kafka
二、使用Sleuth实现大觅网微服务跟踪
1.打开一个分布式项目dm-item-provider,启动,未加sleuth分布式日志时是这样的:
2.在dm-item-provider的pom中添加sleuth依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>1.2.5.RELEASE</version>
</dependency>
3.修改配置文件
修改dm-item-provider项目的application.yml文件,在其中设置日志级别为info
logging:
level: info
4.再次启动比较日志区别,名称变得详细。
5.打开项目dm-item-consumer,添加sleuth依赖,添加logging:info,即重复3、4操作。
启动dm-item-consumer。
6.选一个接口在postman进行请求测试,查看日志输出效果:
获取到了一段较为详尽的日志信息。

三、Spring Cloud Sleuth 整合Zipkin
问题:但是,刚才的日志输出好像用处并不显而易见。
解决:sleuth整合有可视化界面的zipkin。
Zipkin介绍:开源、数据追踪系统
1.创建springboot项目,指定artifactId为dm-sleuth-server
2.pom降版本,添加依赖zipkin-server和zipkin-autoconfigure-ui
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
</dependency>
3.启动类添加注解@EnableZipkinServer
4.application.yml配置服务端口为7700
server:
port: 7700
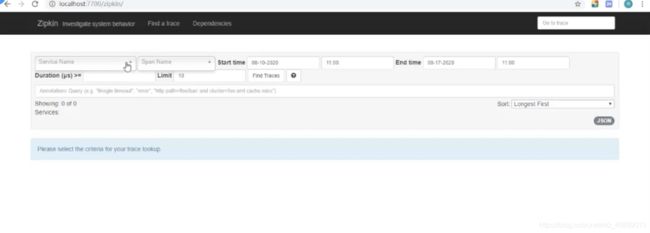
5.启动项目dm-sleuth-server,查看监控http://localhost:7700/,可以看到zipkin的界面
四、微服务整合Zipkin
刚才只能看到zipkin的界面,但是并没有项目信息,接下来进行zipkin的配置。
1.添加依赖
分别为dm-item-consumer、dm-item-provider添加依赖sleuth和zipkin。
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-sleuthartifactId>
<version>1.2.5.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-zipkinartifactId>
dependency>
2.修改配置
分别修改dm-item-consumer、dm-item-provider 的application.yml,在其中指定Zipkin Server地址和采样率
spring:
sleuth:
sampler:
percentage: 1.0
zipkin:
base-url: http://localhost:7700
注意:在开发、测试中配置文件中的spring.sleuth.sampler.percentage属性设置为1.0,代表100%采样,否则可能会忽略掉大量span,可能看不到想要查看的请求
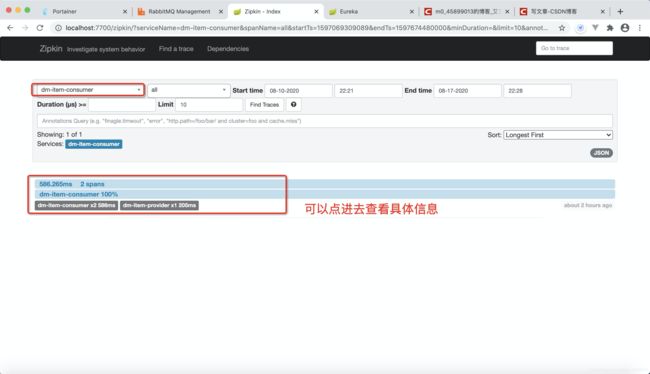
3.重启provider和consumer,刷新zipkin网页,可查看到产生如下数据内容:
可设置请求时间段,单击find traces进行日志追踪。

五、使用消息中间件RabbitMQ收集数据,Zipkin Server整合消息中间件
问题产生:
收集跟踪数据是使用HTTP请求的方式,带来的问题:
耦合性,都需要连接到Zipkin Server
不稳定性,网络出现问题就无法保证收集到跟踪数据。
(之前是通过http传输,http不稳定所以要先给MQ。)
问题解决:
可以使用消息中间件解决。
先将需要收集的数据发送到消息中间件中,然后Zipkin Server再从消息中间件取出数据分析。
这里使用RabbitMQ。
1.在dm-sleuth-server项目中添加依赖zipkin-autoconfigure-ui、sleuth-zipkin-stream、stream-binder-rabbit
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-uiartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-sleuth-zipkin-streamartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-stream-binder-rabbitartifactId>
<version>1.2.1.RELEASEversion>
dependency>
2.在dm-sleuth-server项目中修改启动类注解
将@EnableZipkinServer改为@EnableZipkinStreamServer
3.在dm-sleuth-server项目中修改配置文件
配置RabbitMQ的服务地址和账号
4.分别为dm-user-consumer、dm-user-provider添加依赖
只保留以下依赖sleuth、sleuth-stream、stream-binder-rabbit。starter-zipkin要删掉。
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-sleuthartifactId>
<version>1.2.5.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-sleuth-streamartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-stream-binder-rabbitartifactId>
<version>1.2.1.RELEASEversion>
dependency>
5.修改配置
在dm-item-consumer、dm-item-provider项目的application.yml中删除Zipkin Server连接配置。
在dm-item-consumer、dm-item-provider项目的application.yml中增加RabbitMQ的连接配置。
# zipkin:
# base-url: http://localhost:7700
rabbitmq:
host: 192.168.9.151
port: 5672
username: guest
password: guest
6.启动虚拟机Ubuntu,访问到RabbitMQ可视化界面。

7.依次重启sleuth-server、provider和consumer。
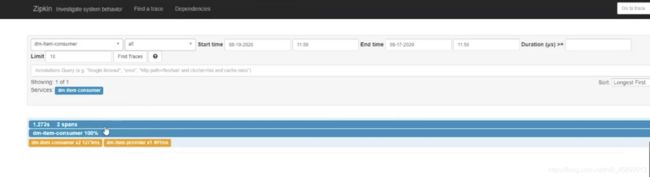
发现刚才请求接口后在zipkin页面展示的接口信息不在了。
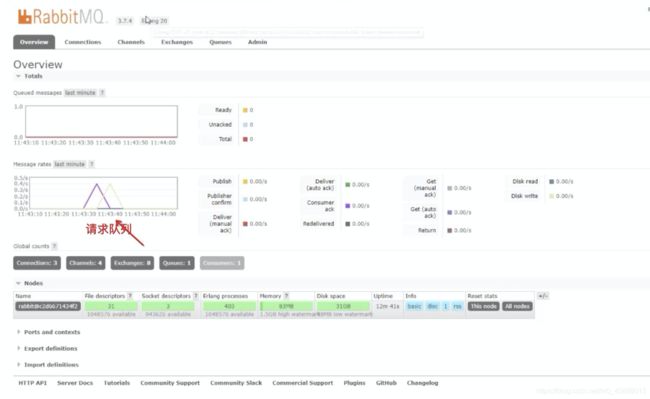
但是,再次访问接口后,zipkin会又有数据,相应的RabbitMQ中也有请求队列:
六、存储跟踪数据
如上,如果sleuth宕机重启,访问接口的数据将丢失。
问题产生:数据丢失
前文示例中Zipkin Server都是将数据保存在内存中,重启Zipkin Server后就不能查看到之前的数据了。
问题解决:数据持久化存储
MySQL
Elasticsearch
…
使用MySQL存储跟踪数据
1.添加依赖
在以上基础上改造Zipkin Server,为dm-sleuth-server添加数据库依赖
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-storage-mysqlartifactId>
<version>1.16.2version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
2.创建数据库:dm_zipkin
使用官方脚本创建表:
https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
创建完毕,数据库中会多出三张空表:

3.修改配置文件
在dm-sleuth-server中添加关于数据库的配置
指定存储方式为MySQL
datasource:
url: jdbc:mysql://rm-bp176tlu16kkssrkkco.mysql.rds.aliyuncs.com:3306/dm_zipkin?useUnicode=true&characterEncoding=gbk&zeroDateTimeBehavior=convertToNull&useSSL=true
username: root
password: 11111
driver-class-name: com.mysql.jdbc.Driver
zipkin:
storage:
type: mysql
4.依次重启sleuth-server、provider和consumer。
zipkin中没有数据,再次访问接口,zipkin中有了数据。
数据库表dm_zipkin.zipkin_annotations中也有了数据:
sleuth-server模拟宕机重启,直接到zipkin刷新,刚才的请求接口信息仍旧在。
通过使用分布式日志sleuth,分布式追踪系统zipkin,消息中间件rabbitMQ,使用MySQL存储跟踪数据后,成功实现消息宕机不丢失。