android+lucene实现全文检索并高亮关键字
这里先假设读者对Lucene的使用比较熟悉的。
由于代码量比较多,这里我只写出一些关键的代码,全部源码请到这里下载:
android+lucene实现全文检索并高亮关键字
android+lucene实现全文检索并高亮关键字索引库
请将下载到的索引库解压后放到sdcard根目录下
源码里边的注释写的也比较详细
在andorid里实现字体高亮,若单独实现其实不是很难,但若和lucene结合使用,实现被搜索的关键字高亮,就有些麻烦事。原因在于,关键字高亮是有lucene提供的一个类(Highlighter)来管理。它的实现方式其实很简单,就是将关键字用html标签包裹起来。下边先来看一下几段关键性的代码
1.先定义一对html标签,用两个String常量来保存
private static final String STARTTAG = "";
private static final String ENDTAG = "";2.通过SimpleHTMLFormatter类,我们可以设置高亮文本的样式,它返回一个Formatter类
Formatter formatter = new SimpleHTMLFormatter(STARTTAG, ENDTAG);3.设置query对象,在query对象中,有查询的关键字
Scorer scorer = new QueryScorer(query);4.新建一个Highlighter类,并设置参数
Highlighter highlighter = new Highlighter(formatter, scorer);
// 设置高亮后的字符长度
highlighter.setTextFragmenter(new SimpleFragmenter(length));String result = highlighter.getBestFragment(LuceneConfigurationUtil.getAnalyzer(), null, text);首先我们需要将Document对象里边的数据转换成我们自定义的对象,先看一段代码
public static Book DocumentToBook(Document doc) {
Book book = new Book();
book.setId(Integer.parseInt(doc.get("id")));
book.setName(doc.get("name"));
book.setFirstTitle(doc.get("firstTitle"));
book.setSecondTitle(doc.get("secondTitle"));
book.setContent(doc.get("content"));
book.setUrl(doc.get("url"));
return book;
} this.nameTv.setText(Html.fromHtml(name));
this.firstTitleTv.setText(Html.fromHtml(firstTitle));
this.secondTitleTv.setText(Html.fromHtml(secondTitle));
this.contentTv.setText(Html.fromHtml(content));
这样进过解析的文本信息就可以直接放到Textview中,并在Activity中显示
这是运行的效果图:
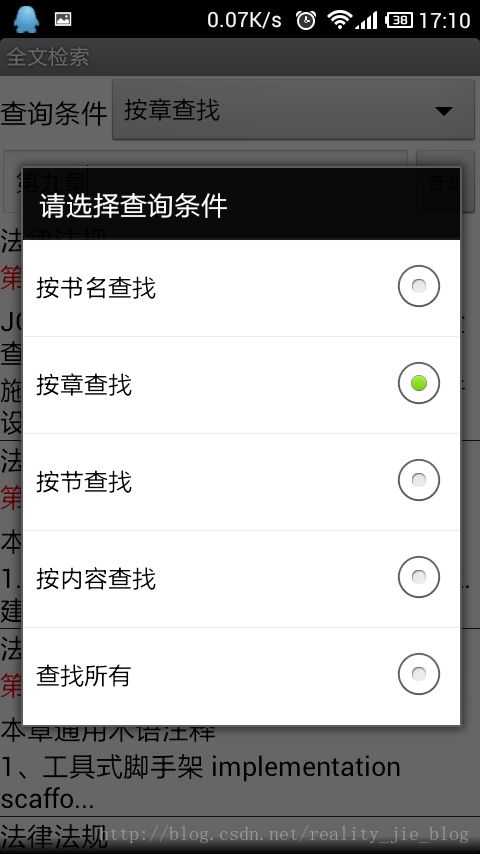
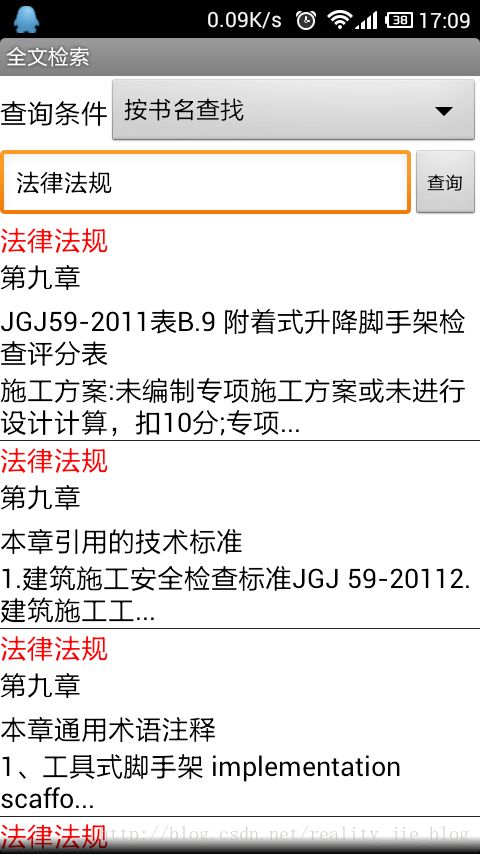
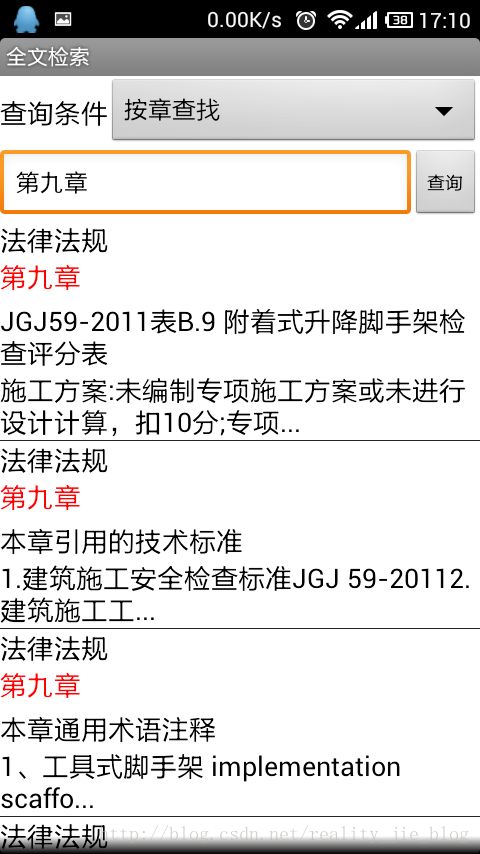
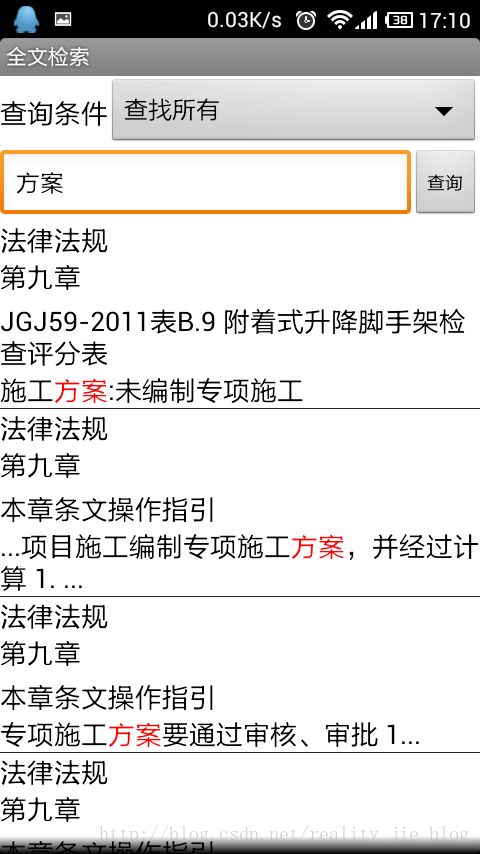
我要说的还没有完呢,从上边的显示结果可以看出,搜索出来的结果集是放在ListView中的。如果我们用简单的SimpleAdapter来装载ListView是不能实现高亮的。这时候我们需要自定义一个适配器,先看一下代码
public class ListViewAdapter extends BaseAdapter {
private Context context = null;
private ArrayList> listItem = null;
private TextView nameTv = null;
private TextView firstTitleTv = null;
private TextView secondTitleTv = null;
private TextView contentTv = null;
public ListViewAdapter(Context context,
ArrayList> listItem) {
super();
this.context = context;
this.listItem = listItem;
}
@Override
public int getCount() {
return listItem.size();
}
@Override
public Object getItem(int arg0) {
return listItem.get(arg0);
}
@Override
public long getItemId(int position) {
return position;
}
@Override
public View getView(int position, View convertView, ViewGroup parent) {
// 取出数据
String name = listItem.get(position).get("name").toString();
String firstTitle = listItem.get(position).get("firstTitle").toString();
String secondTitle = listItem.get(position).get("secondTitle")
.toString();
String content = listItem.get(position).get("content").toString();
View view;
// 获取四个Textview控件
if (convertView == null) {
RelativeLayout relativeLayout = (RelativeLayout) View.inflate(
context, R.layout.law_item, null);
this.nameTv = (TextView) relativeLayout.findViewById(R.id.name);
this.firstTitleTv = (TextView) relativeLayout
.findViewById(R.id.firstTitle);
this.secondTitleTv = (TextView) relativeLayout
.findViewById(R.id.secondTitle);
this.contentTv = (TextView) relativeLayout
.findViewById(R.id.content);
view = relativeLayout;
} else {
view = convertView;
this.nameTv = (TextView) view.findViewById(R.id.name);
this.firstTitleTv = (TextView) view.findViewById(R.id.firstTitle);
this.secondTitleTv = (TextView) view.findViewById(R.id.secondTitle);
this.contentTv = (TextView) view.findViewById(R.id.content);
}
// 解析在LuceneConfigurationUtil设置的html格式代码
this.nameTv.setText(Html.fromHtml(name));
this.firstTitleTv.setText(Html.fromHtml(firstTitle));
this.secondTitleTv.setText(Html.fromHtml(secondTitle));
this.contentTv.setText(Html.fromHtml(content));
return view;
}
} 自定义适配器继承了BaseAdapter抽象类。我们这么做目的是通过重写getView()方法来获取当前的view,,进而获取到view下边的各个控件,最后才能执行那段解析html格式的代码
好啦,说到这里就差不多了,具体的就看我上传的源码吧。
多说几句,这里侧重的是功能的实现,对于lucene的索引库我没有去做怎样的优化。还有,分词器用的是中国人自己开发的IKAnalyzer。老外的太蛋疼了,用过lucene的人,你们懂的。。。。
给些下载连接
lucene-3.0.0
IKAnalyzer3.2.8