问题来源
最近公司引入容器技术,按照计划将应用切换至容器平台,应用切换验证过程中发现一个奇怪的问题。原来可以正常解析的XML配置文件,切换后出现了中文乱码问题,如果是纯英文的则可以正常解析,包含中文的要么解析报错,要么解析出来的中文内容乱码。
因为应用层面未做任何调整,所以问题定位还是相对容易,直接对比应用的启动参数就发现了问题。原来应用部署的参数未指定-Dfile.encoding,而切换容器后统一增加了启动参数-Dfile.encoding=UTF-8。而应用中XML配置文件使用的是GBK编码,所以导致了乱码,将启动参数调整为-Dfile.encoding=GBK,XML配置文件解析恢复正常。
虽然问题解决了,但是任然有三个困惑点没有解决:
- 未指定
file.encoding的情况下,默认编码是由什么决定的? - 指定
file.encoding的话,会产生什么影响? - 经常与
file.encoding一起出现的sun.jnu.encoding参数又是什么?两者有什么关系?
于是决定探索一下-Dfile.encoding。
启动参数-Dfile.encoding是什么?
file.encoding 直译:文件编码。
查找 java 源码,只有四个类调用了 file.encoding 这个属性。

- 在
java.nio.Charset.defaultCharset()
/**
* Returns the default charset of this Java virtual machine.
*
* The default charset is determined during virtual-machine startup and
* typically depends upon the locale and charset of the underlying
* operating system.
*
* @return A charset object for the default charset
*
* @since 1.5
*/
public static Charset defaultCharset() {
if (defaultCharset == null) {
synchronized (Charset.class) {
String csn = AccessController.doPrivileged(
new GetPropertyAction("file.encoding"));
Charset cs = lookup(csn);
if (cs != null)
defaultCharset = cs;
else
defaultCharset = forName("UTF-8");
}
}
return defaultCharset;
}
从注释中可以看到,默认字符集是在 java 虚拟机启动时决定的,依赖于 java 虚拟机所在的操作系统的区域以及字符集。
从代码中可以看出,默认字符集就是从 file.encoding 这个属性中获取的。
此处的默认字符集会影响字符串、文件字符流读写等的默认编码。
-
URLEncoder.encode(String)Web环境中最常遇到的编码使用。 -
com.sun.org.apache.xml.internal.serializer.Encoding.getMimeEncodings(String)影响对无编码设置的xml文件的读取 。 -
javax.print.DocFlavor影响打印的编码。
从以上信息可以分析到,file.encoding 会影响无指定编码的字符串、读写文件、URL编码、打印等内容。
分析file.encoding 对字符输入流的影响
无编码设置的字符输入流方法:java.io.InputStreamReader.InputStreamReader(InputStream in)的源码如下:
public InputStreamReader(InputStream in) {
super(in);
try {
sd = StreamDecoder.forInputStreamReader(in, this, (String)null); // ## check lock object
} catch (UnsupportedEncodingException e) {
// The default encoding should always be available
throw new Error(e);
}
}
接着看StreamDecoder.forInputStreamReader的源码:
public static StreamDecoder forInputStreamReader(InputStream var0, Object var1, String var2) throws UnsupportedEncodingException {
String var3 = var2;
if (var2 == null) {
var3 = Charset.defaultCharset().name();
}
try {
if (Charset.isSupported(var3)) {
return new StreamDecoder(var0, var1, Charset.forName(var3));
}
} catch (IllegalCharsetNameException var5) {
}
throw new UnsupportedEncodingException(var3);
}
到这里就发现,如果没有设置编码参数,即上面源码中的if (var2 == null),则又回到了开始说的:Charset.defaultCharset(),获取到的默认编码也就是file.encoding 指定的编码。
那么问题来了,如果启动参数中没有指定file.encoding 的值,那jvm启动的时候file.encoding 指定的默认值是什么呢?
分析file.encoding 参数默认值
说明: 由于很多场景
file.encoding和sun.jnu.encoding总是被一起提及,所以下面一起分析这两个参数。以下测试中,操作系统编码:GBK,java类文件编码:UTF-8。
先看一下未指定启动参数值的情况下输出系统参数file.encoding和sun.jnu.encoding的值。代码如下:
public class FileEncodeTest {
public static void main(String[] args) {
System.out.println("file.encoding : "+System.getProperty("file.encoding"));
System.out.println("sun.jnu.encoding : "+System.getProperty("sun.jnu.encoding"));
}
}
执行结果:
$ javac FileEncodeTest.java
$ java FileEncodeTest
file.encoding : GBK
sun.jnu.encoding : GBK
确认一下操作系统当前的编码:
$ env | grep LANG=
LANG=zh_CN.GBK
从结果来看,file.encoding和sun.jnu.encoding的值与操作系统的编码值一致。但是并不能说明file.encoding和sun.jnu.encoding的默认值值由操作系统的编码决定。
需要进一步验证,将操作系统默认编码调整为UTF-8:
$ export LANG=zh_CN.UTF-8
$ env|grep LANG=
LANG=zh_CN.UTF-8
重新运行得出测试结果:
$ java FileEncodeTest
file.encoding : UTF-8
sun.jnu.encoding : UTF-8
调整操作系统编码为UTF-8后,file.encoding和sun.jnu.encoding的值也变为UTF-8。
到这里可以得出结论,file.encoding和sun.jnu.encoding的默认值由操作系统的当前编码决定。
分析file.encoding对读写文件内容的影响
通过不设置编码格式的FileReader读取一个UTF-8编码的文件FileEncodeTest副本.java,打印文件名和文件内容。【操作系统编码为:GBK】
import java.io.*;
public class FileEncodeTest {
public static void main(String[] args) throws Exception {
System.out.println("file.encoding : "+System.getProperty("file.encoding"));
System.out.println("sun.jnu.encoding : "+System.getProperty("sun.jnu.encoding"));
// sun.jnu.encoding不会影响文件名的读取
// java -Dfile.encoding=utf-8 -Dsun.jnu.encoding=GBK FileEncodeTest 正常读取文件
// java -Dfile.encoding=utf-8 -Dsun.jnu.encoding=UTF-8 FileEncodeTest 正常读取文件
File file = new File("D:\\FileEncode\\UTF8\\FileEncodeTest副本.java");
System.out.println(file.getName());
// java -Dfile.encoding=utf-8 -Dsun.jnu.encoding=UTF-8 FileEncodeTest 正常创建文件
// java -Dfile.encoding=utf-8 -Dsun.jnu.encoding=GBK FileEncodeTest 正常创建文件
// java -Dfile.encoding=utf-8 -Dsun.jnu.encoding=ISO-8859-1 FileEncodeTest 正常创建文件
File file01 = new File("E:\\xstl\\中文01.txt");
file01.createNewFile();
// file.encoding会影响文件内容的读取
FileReader fileReader = new FileReader( "D:\\FileEncode\\UTF8\\FileEncodeTest副本.java");
System.out.println("FileReader Encode : " + fileReader.getEncoding());
BufferedReader br = new BufferedReader(fileReader);
String line;
while((line = br.readLine()) != null) {
System.out.println(line);
}
br.close();
}
}
在不添加file.encoding启动参数的情况下,文件名正常,文件内容乱码。
$ javac -encoding utf-8 FileEncodeTest.java
$ java FileEncodeTest
file.encoding : GBK
sun.jnu.encoding : GBK
FileEncodeTest副本.java
FileReader Encode : GBK
public class FileEncodeTest鍓湰 {
public static void main(String[] args) throws Exception {
System.out.println("file.encoding : "+System.getProperty("file.encoding"));
System.out.println("sun.jnu.encoding : "+System.getProperty("sun.jnu.encoding"));
System.out.println("FileEncodeTest鍓湰 ");
}
}
调整运行时参数,增加-Dfile.encoding=UTF-8后执行,不再乱码。
$ java -Dfile.encoding=UTF-8 FileEncodeTest
file.encoding : UTF-8
sun.jnu.encoding : GBK
FileEncodeTest副本.java
FileReader Encode : UTF8
public class FileEncodeTest副本 {
public static void main(String[] args) throws Exception {
System.out.println("file.encoding : "+System.getProperty("file.encoding"));
System.out.println("sun.jnu.encoding : "+System.getProperty("sun.jnu.encoding"));
System.out.println("FileEncodeTest副本 ");
}
}
根据上面的验证,可以得出结论,'file.encoding'参数设置的编码会影响读取文件的内容,'sun.jnu.encoding'参数设置不会影响读取文件的文件名。
那是否有可能在读取文件内容之前先设置一下'file.encoding'的值,然后再读取文件内容,就可以了呢?
JVM启动后再System.setProperty("file.encoding")是否有效果?
稍微调整一下代码,在读取文件内容之前,先将'file.encoding'的值设为UTF-8,设置系统属性值的代码:System.setProperty("file.encoding", "UTF-8")。
import java.io.*;
public class FileEncodeTest {
public static void main(String[] args) throws Exception {
System.out.println("file.encoding : "+System.getProperty("file.encoding"));
System.out.println("sun.jnu.encoding : "+System.getProperty("sun.jnu.encoding"));
System.setProperty("file.encoding", "UTF-8");
System.out.println("file.encoding : "+System.getProperty("file.encoding"));
FileReader fileReader = new FileReader( "D:\\FileEncode\\UTF8\\FileEncodeTest副本.java");
System.out.println("FileReader Encode : " + fileReader.getEncoding());
BufferedReader br = new BufferedReader(fileReader);
String line;
while((line = br.readLine()) != null) {
System.out.println(line);
}
br.close();
}
}
根据输出结果可以看出,虽然系统值改变了,System.getProperty("file.encoding")的值变为了UTF-8,但是并没有改变默认字符集的值,FileReader的编码依然是GBK。
$ java FileEncodeTest
file.encoding : GBK
sun.jnu.encoding : GBK
file.encoding : UTF-8
FileEncodeTest副本.java
FileReader Encode :GBK
public class FileEncodeTest鍓湰 {
public static void main(String[] args) throws Exception {
System.out.println("file.encoding : "+System.getProperty("file.encoding"));
System.out.println("sun.jnu.encoding : "+System.getProperty("sun.jnu.encoding"));
System.out.println("FileEncodeTest鍓湰 ");
}
}
因此可以得出结论,JVM启动后设置系统配置值System.setProperty("file.encoding", "UTF-8")不会影响到默认字符集的编码。如果需要指定读取文件内容的编码,需要通过字符流的构造器InputStreamReader(InputStream in, Charset cs)设置。
对类编译、加载的影响(内容和文件名)
既然file.encoding的值会影响文件内容读取的编码,而类加载的过程也需要读取class文件的内容,那file.encoding是否会影响类加载过程呢?我们先试一下。下面是测试代码【FileEncodeTest.java文件是UTF-8编码】:
public class FileEncodeTest {
public static void main(String[] args) {
System.out.println("file.encoding : "+System.getProperty("file.encoding"));
System.out.println("sun.jnu.encoding : "+System.getProperty("sun.jnu.encoding"));
System.out.println("中文");
}
}
不带-encoding utf-8,编译执行,运行结果:
$ javac FileEncodeTest.java
$ java FileEncodeTest
file.encoding : GBK
sun.jnu.encoding : GBK
涓枃
从结果来看,java类文件是UTF-8编码,file.encoding是GBK,从而导致了乱码,似乎印证了file.encoding会影响class文件的加载。
然而事实并非如此,即使加上参数'-Dfile.encoding=utf-8',执行结果依然会乱码。
$ java -Dfile.encoding=utf-8 Test02
file.encoding : utf-8
sun.jnu.encoding : GBK
涓枃
细心的读者可能会注意到,前面编译代码的时候都增加了参数-encoding utf-8,事实上此处会乱码并不是加载的时候引起的,而是编译时引起的。
调整编译参数,增加-encoding utf-8,重新测试。
$ javac -encoding utf-8 FileEncodeTest.java
$ java FileEncodeTest
file.encoding : GBK
sun.jnu.encoding : GBK
中文
编译恢复正常。
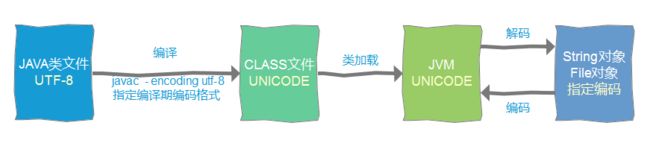
在类编译过程中需要指定编译代码的编码,也就是java类文件的编码。编译后形成的class文件被统一编码为UNICODE格式,类加载过程中自然也是使用UNICODE编码,file.encoding影响的是未指定字符编码时的默认字符集。
接下来进一步验证,先调整测试代码:
public class FileEncodeTest {
public static void main(String[] args) throws Exception {
System.out.println("file.encoding : "+System.getProperty("file.encoding"));
System.out.println("sun.jnu.encoding : "+System.getProperty("sun.jnu.encoding"));
String test = "中文";
System.out.println(new String(test.getBytes(), "UTF-8"));
}
}
运行结果:
$ javac -encoding utf-8 FileEncodeTest.java
$ java FileEncodeTest
file.encoding : GBK
sun.jnu.encoding : GBK
????
因为默认的字符编码集是GBK,new String(test.getBytes(), "UTF-8")这段代码,实际上是new String(test.getBytes("GBK"), "UTF-8")。
调整执行参数,增加-Dfile.encoding=utf-8,重新运行,中文正常输出:
$ javac -encoding utf-8 FileEncodeTest.java
$ java -Dfile.encoding=utf-8 FileEncodeTest
file.encoding : utf-8
sun.jnu.encoding : GBK
中文
或者将new String(test.getBytes(), "UTF-8"),调整为new String(test.getBytes(), "GBK"),乱码问题也可以解决,其实好的实践应该是:new String(test.getBytes("UTF-8"), "UTF-8")。
以上可以得出结论,编译期间的字符编码由javac -encoding utf-8决定,运行期间的默认字符编码由file.encoding决定,而class文件和JVM的字符编码统一使用UNICODE编码。
那说半天,sun.jnu.encoding一点存在感都没有,那sun.jnu.encoding究竟起什么作用呢?
中文类名?
研究到这里,file.encoding参数的作用已经比较清楚了,那sun.jnu.encoding又有什么作用呢?我们先试着运行如下测试代码:
public class FileEncodeTest副本 {
public static void main(String[] args) throws Exception {
System.out.println("file.encoding : "+System.getProperty("file.encoding"));
System.out.println("sun.jnu.encoding : "+System.getProperty("sun.jnu.encoding"));
}
}
运行结果,一切正常:
$ javac -encoding utf-8 FileEncodeTest副本.java
$ java FileEncodeTest副本
file.encoding : GBK
sun.jnu.encoding : GBK
调整一下运行参数,增加'-Dsun.jnu.encoding=utf-8',提示“错误: 找不到或无法加载主类 FileEncodeTest????”。
$ java -Dsun.jnu.encoding=utf-8 FileEncodeTest副本
错误: 找不到或无法加载主类 FileEncodeTest????
这是因为测试场景的操作系统编码是GBK,当sun.jnu.encoding未配置使用和操作系统一致编码(GBK),编码统一不会引起乱码。而手动设置sun.jnu.encoding为utf-8编码时,与操作系统的GBK编码不一致,因而无法加载指定的类。
这说明-Dsun.jnu.encoding的编码会影响类加载时定位中文类。
另外,我们来看一下下面这个测试代码:
public class FileEncodeTest {
public static void main(String[] args) throws Exception {
System.out.println("file.encoding : "+System.getProperty("file.encoding"));
System.out.println("sun.jnu.encoding : "+System.getProperty("sun.jnu.encoding"));
System.out.println("args0 : " + args[0]);
System.out.println(System.getProperties().getProperty("test"));
}
}
运行结果如下:
$ javac -encoding utf-8 FileEncodeTest.java
$ java -Dsun.jnu.encoding=GBK -Dtest=中文 FileEncodeTest 中文
file.encoding : GBK
sun.jnu.encoding : GBK
args0 : 中文
中文
重新调整运行参数,将sun.jnu.encoding的值从GBK改为UTF-8,再执行结果如下:
$ javac -encoding utf-8 FileEncodeTest.java
$ java -Dsun.jnu.encoding=UTF-8 -Dtest=中文 FileEncodeTest 中文
file.encoding : GBK
sun.jnu.encoding : UTF-8
args0 : ????
中文
从上面的测试结果可以看出,'-Dsun.jnu.encoding' 除了影响读取类名,还会影响传入参数的编码。
总结
-
file.encoding不主动配置的情况下,默认是操作系统的编码; -
file.encoding在JVM启动后再修改其值,只会修改配置项值,不会改变默认字符集编码; - 运行时配置
file.encoding,影响java默认字符集编码:
- Charset.defaultCharset() Java环境中非常关键的编码设置
- URLEncoder.encode(String) Web环境中最常遇到的编码使用
- com.sun.org.apache.xml.internal.serializer.Encoding 影响对无编码设置的xml文件的读取
- javax.print.DocFlavor 影响打印的编码
-
sun.jnu.encoding影响类加载时类名的编码
文件操作涉及到字节操作和字符操作,在字符操作的时候应该明确指定操作的编码,而不是依赖默认配置,从而避免很多的不确定性,降低外部依赖(耦合)。
注意:Eclipse或IDEA在编译或运行时,会默认增加编译、运行时参数,会影响代码效果,建议在命令行验证如上测试代码。