HashMap
实现了Map接口,线程不安全。
实现原理:
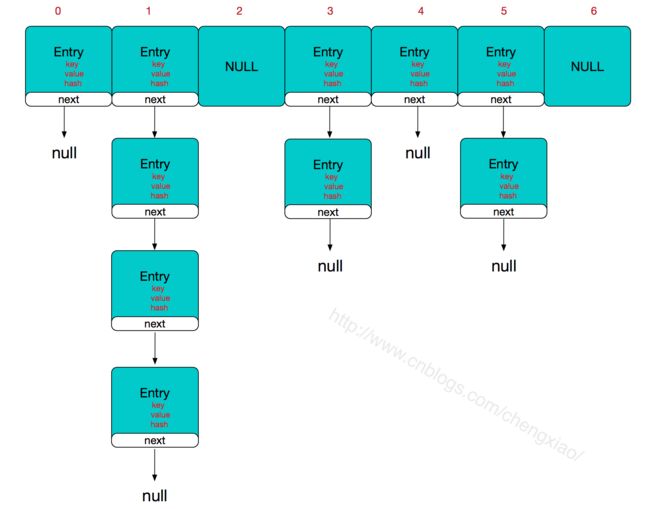
HashMap由数组+链表组成,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的。
如果通过hash定位到数组位置没有链表,则查找、添加速度很快。否则,就要解决hash冲突,操作链表。遍历链表时,通过key对象的equals方法逐一比对。
构造hashmap的时候有两个参数,initialCapacity初始容量(默认16)、loadFactor装载因子(默认0.75)。
向容器中添加元素的时候,如果元素个数达到阈值(元素个数=数组长度*loadFactor),就要自动扩容。
使用一个新的数组代替已有的数组,每次扩容为先前的两倍。
经过 rehash 之后,元素的位置要么在原位置,要么在原位置再移动2次幂的位置。
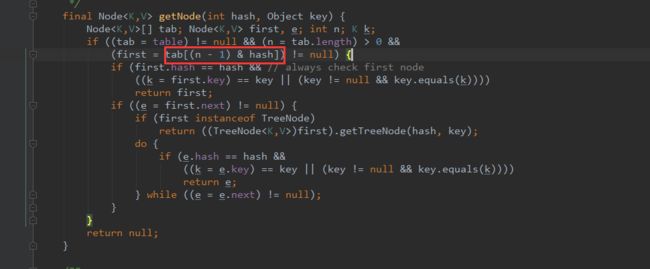
hash函数

调用对象key自带的hashCode(),hashCode()返回intl类型值。
右位移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。
散列值不能直接使用,还要对数组长度取模(异或实现散列值映射到数组,^代替%,效果一样),得到余数才能访问数组下标。如下:
https://www.hollischuang.com/archives/2091
Hashtable
Hashtable对外提供的public函数几乎都是同步的(synchronized关键字修饰),线程安全。
key和value都不能为null。
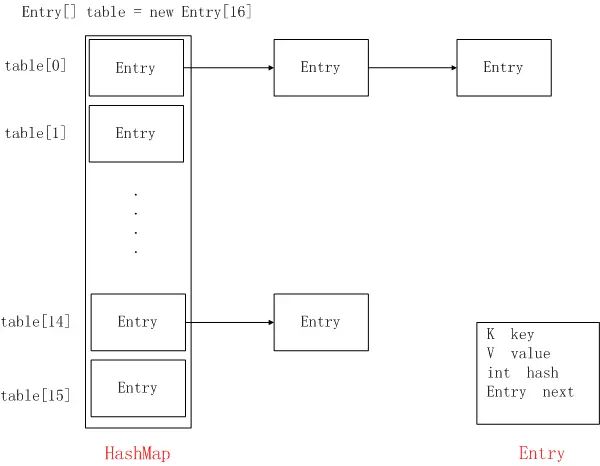
HashTable的数据结构和HashMap一样,采用Entry数组 + 链表的方法实现。
HashTabale初始的容量为11,负载因子为0.75,这点和HashMap不同,HashMap初始化时容量大小总是2的幂次方,即使给定一个不是2的幂次方容量的值,也会自动初始化为最接近其2的幂次方的容量。
哈希值计算方式是:int hash = key.hashCode()
数组索引计算方式是:int index = (hash & 0x7FFFFFFF) % tab.length; // 0x7FFFFFFF 即 Integer.MAX_VALUE(01111111 11111111 11111111 11111111)确保index为正数。
让HashMap同步:Map m =Collections.synchronizedMap(hashMao);
HashMap的迭代器(Iterator)是fail-fast迭代器,Hashtable的iterator遍历方式支持fast-fail,用Enumeration不支持fast-fail。
TreeMap
https://edu.csdn.net/course/play/5386/98487
TreeMap的数据结构是红黑树。
HashMap和Hashtable不保证数据有序,LinkedHashMap保证数据可以保持插入顺序,而TreeMap可以按key的大小顺序排序。
LinkedHashMap
LinkedHashMap保证数据可以保持插入顺序
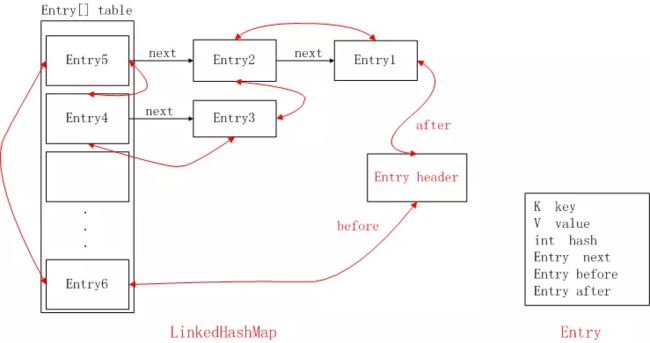
LinkedHashMap在HashMap的基础上多了一个双向链表来维持顺序。