大数据干货系列(十一)--Spark Streaming总结
本文共计902字,预计阅读时长六分钟
Spark-Streaming总结
一、本质
Spark Streaming是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理
二、Spark Streaming和Spark Core
2.1 逻辑关系:

2.2 物理关系:

1) DStream:Spark Streaming提供了表示连续数据流的、高度抽象的被称为离散流的DStream
2) 任何对DStream的操作都会转变为对底层RDD的操作。
2.3 算子关系:
1) Spark Streaming 算子分为Transformation和Output
2) Transformation包括Spark中的Transform和部分的Action(Reduce、Count等)
3) Output:
• saveAsObjectFile、saveAsTextFile、saveAsHadoopFiles:将一批数据输出到Hadoop文件系统中,用批量数据的开始时间戳来命名
• forEachRDD:允许用户对DStream的每一批量数据对应的RDD本身做任意操作
2.4 DAG和DStream Graph:
DAG(逻辑层):Spark根据Action用作划分stage
DStream Graph(物理层):根据Output,通过DStream Graph的依赖关系,剔除掉其他和Output没有关系的操作,又叫依赖关系图。
实现原理如下:
(1)把程序中对DStream的操作转换成DStream Graph(依赖关系图)
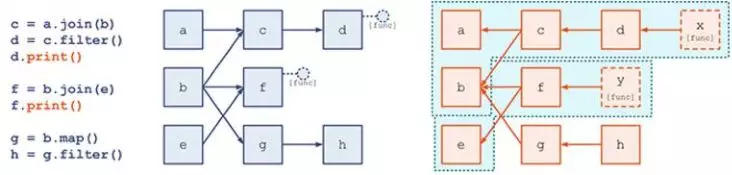
(2)对于每个时间片,DStream Graph都会产生一个RDD Graph
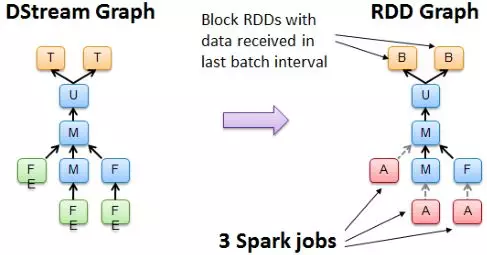
(3)针对每个Output(print,forEachRdd),创建一个Spark Action/Transform进行输出。
(4)输出过程是,Spark Job交给JobManager,JobManager中维护着一个Job Queue,把Job交给Spark scheduler,scheduler负责调度。
三、Spark Streaming系统架构
3.1 系统组件: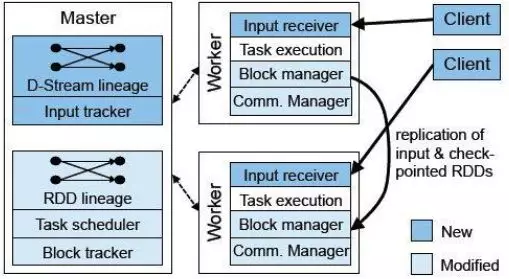
– Master:记录DStream之间的依赖关系或者血缘关系,并负责任务调度以生成新的RDD
– Worker:从网络接收数据,存储并执行RDD计算
– Client:负责向Spark Streaming中灌入数据
3.2 作业提交流程:
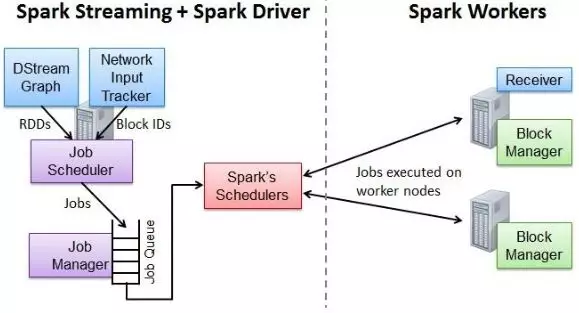
• Network Input Tracker:跟踪每一个网络received数据,并且将其映射到相应的input DStream上
• Job Scheduler:周期性的访问DStream Graph并生成Spark Job,将其交给Job Manager执行
• Job Manager:获取任务队列,并执行Spark任务
3.3 窗口操作:
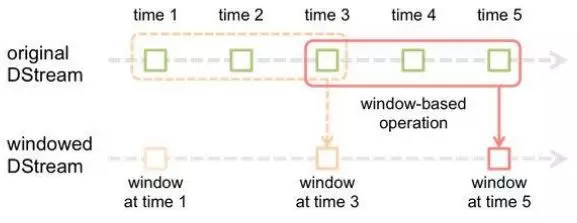
• Spark提供了一组窗口操作,通过滑动窗口技术对大规模数据的增量更新进行统计分析
• Window Operation:定时进行一定时间段内的数据处理
• 任何基于窗口的操作需要指定两个参数:
1) 窗口总长度(window length)
2) 滑动时间间隔(slide interval)

四、Spark容错性分析
4.1 Worker容错:
同Spark:worker挂了将会导致partition失效,如果task依赖的上层partition数据已经失效了,则会先将其依赖的partition计算任务再重算一遍。
4.2 Driver容错:
1.Driver的出错情况
(1)当数据源(InputStream)是HDFS时,driver数据恢复机制不重要
(2)当数据源是kafka、Flume时,由于数据被worker executor接收至内存中,若driver挂了,executor内存中的数据就不可用了,此时需要容错机制——主要依赖预写日志(WAL)和持久化日志。
2.容错原理
step1.
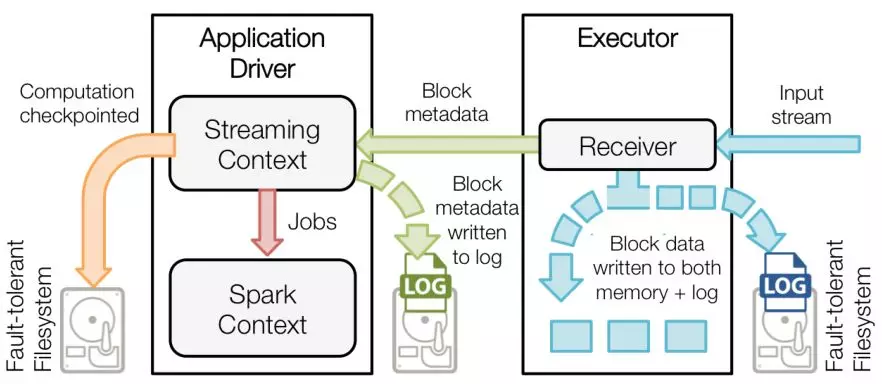
(1)Executor中的Receiver接收到数据后,存入内存,并写入HDFS上的log里
(2)Driver将接收到的Block元信息,①也持久化到日志中,并依据Streaming Context中的DAG生成Jobs的同时,②保存预写日志WAL和Streaming Context的checkpoint信息(a.配置信息,b.DStream操作的集合(即代码) c.未完成一些batches)到HDFS,③最后根据Jobs创建SparkContext
step2.
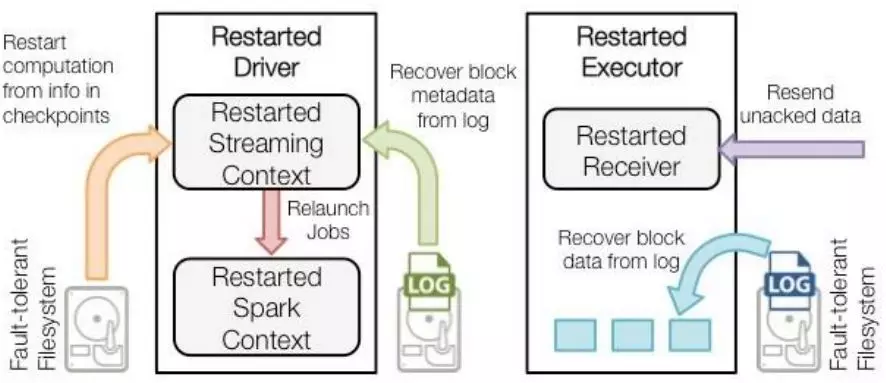
(1)Driver重启后,根据WAL和Streaming的checkpoint,以及log中的block元信息,重新发送Jobs来创建SparkContext
(2)Executor根据SparkContext的信息,从HDFS恢复需要的Block数据,并开始继续从数据源接收数据。
3.启动WAL的配置
(1)给StreamingContext设置checkpoint的目录,该目录必须是HADOOP支持的文件系统,用来保存WAL和做Streaming的checkpoint
(2)Spark.Streaming.receiver.writeAheadLog.enable 设置为true
重要通知:
在公众号内点击菜单
即可看到更全更新的内容
【纯干货】公众号:bigdata_x
点击这里查看往期精彩内容:
大数据干货系列(十)--Kafka总结
大数据干货系列(九)--HBase总结
大数据干货系列(八)--Flume总结
大数据干货系列(七)--Storm总结
大数据干货系列(六)--Spark总结
大数据干货系列(五)--Hive总结
大数据干货系列(四)--ZooKeeper总结
大数据干货系列(三)-- Hadoop2.0总结
大数据干货系列(二)--HDFS1.0
大数据干货系列(一)--MapReduce总结