Python学习笔记——输入输出
一、标准输入输出
1、打印到屏幕
产生输出的最简单方法是使用print语句,可以通过用逗号分隔零个或多个表达式。这个函数传递表达式转换为一个字符串,如下结果写到标准输出 -
print ("Python is really a great language,", "isn't it?")- 1
这将产生以下结果标准屏幕上 :
Python is really a great language, isn't it?- 1
2、读取键盘输入
Python2中有两个内置的函数可从标准输入读取数据,它默认来自键盘。这些函数分别是:input() 和 raw_input()。
但在Python3中,raw_input()函数已被弃用。此外, input() 函数是从键盘作为字符串读取数据,不论是否使用引号(”或“”)。
示例:
x=input("请输入x=")
y=input("请输入y=")
z=x+y
print("x+y="+z)
- 1
- 2
- 3
- 4
- 5
运行结果:
请输入x=111
请输入y=222
x+y=111222- 1
- 2
- 3
可以看到input的返回值永远是字符串,当我们需要返回int型时需要使用int(input())的形式,例如:
x=int(input("请输入x="))
y=int(input("请输入y="))
z=x+y
print("x+y=",z)
- 1
- 2
- 3
- 4
- 5
运行结果如下:
请输入x=111
请输入y=222
x+y= 333- 1
- 2
- 3
3、格式化输出
一般来说,我们希望更多的控制输出格式,而不是简单的以空格分割。这里有两种方式:
第一种是由你自己控制。使用字符串切片、连接操作以及 string 包含的一些有用的操作。
示例:
# 第一种方式:自己控制
for x in range(1, 11):
print(str(x).rjust(2), str(x*x).rjust(3), end=' ')
print(str(x*x*x).rjust(4)) - 1
- 2
- 3
- 4
输出:
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
第一种方式中,字符串对象的 str.rjust() 方法的作用是将字符串靠右,并默认在左边填充空格,所占长度由参数指定,类似的方法还有 str.ljust() 和 str.center() 。这些方法并不会写任何东西,它们仅仅返回新的字符串,如果输入很长,它们并不会截断字符串。
第二种是使用str.format()方法。
用法:它通过{}和:来代替传统%方式
- 使用位置参数
要点:从以下例子可以看出位置参数不受顺序约束,且可以为{},只要format里有相对应的参数值即可,参数索引从0开,传入位置参数列表可用*列表的形式。
>>> li = ['hoho',18]
>>> 'my name is {} ,age {}'.format('hoho',18)
'my name is hoho ,age 18'
>>> 'my name is {1} ,age {0}'.format(10,'hoho')
'my name is hoho ,age 10'
>>> 'my name is {1} ,age {0} {1}'.format(10,'hoho')
'my name is hoho ,age 10 hoho'
>>> 'my name is {} ,age {}'.format(*li)
'my name is hoho ,age 18'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 使用关键字参数
要点:关键字参数值要对得上,可用字典当关键字参数传入值,字典前加**即可
>>> hash = {'name':'hoho','age':18}
>>> 'my name is {name},age is {age}'.format(name='hoho',age=19)
'my name is hoho,age is 19'
>>> 'my name is {name},age is {age}'.format(**hash)
'my name is hoho,age is 18'- 1
- 2
- 3
- 4
- 5
- 填充与格式化
格式:{0:[填充字符][对齐方式 <^>][宽度]}.format()
>>> '{0:*>10}'.format(20) ##右对齐
'********20'
>>> '{0:*<10}'.format(20) ##左对齐
'20********'
>>> '{0:*^10}'.format(20) ##居中对齐
'****20****'- 1
- 2
- 3
- 4
- 5
- 6
- 精度与进制
>>> '{0:.2f}'.format(1/3)
'0.33'
>>> '{0:b}'.format(10) #二进制
'1010'
>>> '{0:o}'.format(10) #八进制
'12'
>>> '{0:x}'.format(10) #16进制
'a'
>>> '{:,}'.format(12369132698) #千分位格式化
'12,369,132,698'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 使用索引
>>> li
['hoho', 18]
>>> 'name is {0[0]} age is {0[1]}'.format(li)
'name is hoho age is 18- 1
- 2
- 3
- 4
二、文件IO
Python提供了基本的功能和必要的默认操作文件的方法。使用一个 file 对象来做大部分的文件操作。
1、open 函数
在读取或写入一个文件之前,你必须使用 Python 内置open()函数来打开它。 该函数创建一个文件对象,这将被用来调用与它相关的其他支持方式。
语法:
file object = open(file_name [, access_mode][, buffering])- 1
下面是参数的详细信息:
file_name: 文件名(file_name )参数是包含您要访问的文件名的字符串值。
access_mode: access_mode指定该文件已被打开,即读,写,追加等方式。可能值的完整列表,在表中如下。这是可选的参数,默认文件访问模式是读(r)。 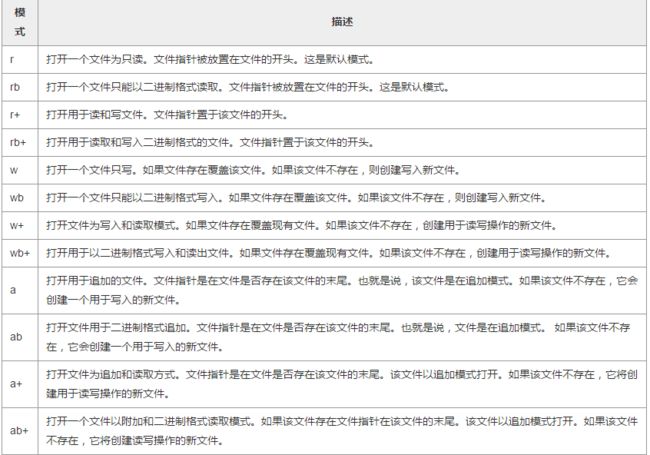
buffering: 如果该缓冲值被设置为0,则表示不使用缓冲。如果该缓冲值是1,则在访问一个文件进行时行缓冲。如果指定缓冲值大于1的整数,缓冲使用所指示的缓冲器大小进行。如果是负数,缓冲区大小是系统默认的(默认行为)。
通常,文件以文本的形式打开,这意味着,你从文件读出和向文件写入的字符串会被特定的编码方式(默认是UTF-8)编码。
模式后面可以追加参数 ‘b’ 表示以二进制模式打开文件:数据会以字节对象的形式读出和写入。这种模式应该用于所有不包含文本的文件。在文本模式下,读取时默认会将平台有关的行结束符(Unix上是 \n , Windows上是 \r\n)转换为 \n。在文本模式下写入时,默认会将出现的 \n 转换成平台有关的行结束符。这种暗地里的修改对 ASCII 文本文件没有问题,但会损坏 JPEG 或 EXE 这样的二进制文件中的数据。使用二进制模式读写此类文件时要特别小心。
2、file 对象属性
一旦文件被打开,则就会有一个文件对象,你就可以得到有关该文件的各种信息。
file.closed:如果文件被关闭返回true,否则为false
file.mode :返回文件打开访问模式
file.name :返回文件名
测试:
# Open a file
fo = open("foo.txt", "wb")
print ("Name of the file: ", fo.name)
print ("Closed or not : ", fo.closed)
print ("Opening mode : ", fo.mode)
fo.close()
print ("Closed or not : ", fo.closed)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
运行结果:
Name of the file: foo.txt
Closed or not : False
Opening mode : wb
Closed or not : True- 1
- 2
- 3
- 4
3、file对象的方法
假设已经创建了一个称为 f 的文件对象。
- f.read()
为了读取一个文件的内容,调用 f.read(size), 这将读取一定数目的数据, 然后作为字符串或字节对象返回。
size 是一个可选的数字类型的参数。 当 size 被忽略了或者为负, 那么该文件的所有内容都将被读取并且返回。
以下实例假定文件 foo.txt 已存在且内容如下:
Hello World!
Hello Python!- 1
- 2
代码如下:
# 打开一个文件
f = open("foo.txt", "r",encoding= 'UTF-8')
str = f.read()
print(str)
# 关闭打开的文件
f.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
执行以上程序,输出结果为:
Hello World!
Hello Python!- 1
- 2
- f.readline()
f.readline() 会从文件中读取单独的一行。换行符为 ‘\n’。f.readline() 如果返回一个空字符串, 说明已经已经读取到最后一行。
# 打开一个文件
f = open("foo.txt", "r",encoding= 'UTF-8')
str = f.readline()
print(str)
# 关闭打开的文件
f.close()- 1
- 2
- 3
- 4
- 5
- 6
执行以上程序,输出结果为:
Hello World!- 1
- f.readlines()
f.readlines() 将返回该文件中包含的所有行。
如果设置可选参数 sizehint, 则读取指定长度的字节, 并且将这些字节按行分割。
# 打开一个文件
f = open("foo.txt", "r",encoding= 'UTF-8')
str = f.readlines()
print(str)
# 关闭打开的文件
f.close()- 1
- 2
- 3
- 4
- 5
- 6
执行以上程序,输出结果为:
['Hello World!\n', 'Hello Python!']- 1
另一种方式是迭代一个文件对象然后读取每行:
# 打开一个文件
f = open("foo.txt", "r",encoding="UTF-8")
for line in f:
print(line, end='')
# 关闭打开的文件
f.close()- 1
- 2
- 3
- 4
- 5
- 6
执行以上程序,输出结果为:
Hello World!
Hello Python!- 1
- 2
这个方法很简单, 但是并没有提供一个很好的控制。 因为两者的处理机制不同, 最好不要混用。
- f.write()
f.write(string) 将 string 写入到文件中, 然后返回写入的字符数。
# 打开一个文件
f = open("foo.txt", "w",encoding="UTF-8")
num = f.write( "Python 是一个非常好的语言。\n是的,的确非常好!!\n" )
print(num)
# 关闭打开的文件
f.close()- 1
- 2
- 3
- 4
- 5
- 6
执行以上程序,输出结果为:
29- 1
打开foo.txt其内容如下:
Python 是一个非常好的语言。
是的,的确非常好!!
- 1
- 2
- 3
如果要写入一些不是字符串的东西, 那么将需要先进行转换:
# 打开一个文件
f = open("foo.txt", "w",encoding="UTF-8")
value = ('www.baidu.com', 666)
s = str(value)
f.write(s)
# 关闭打开的文件
f.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
执行以上程序,打开 foo.txt 文件:
('www.baidu.com', 666)- 1
- f.tell()
f.tell() 返回文件对象当前所处的位置, 它是从文件开头开始算起的字节数。
- f.seek()
如果要改变文件当前的位置, 可以使用 f.seek(offset, from_what) 函数。
from_what 的值, 如果是 0 表示开头, 如果是 1 表示当前位置, 2 表示文件的结尾,例如:
seek(x,0) : 从起始位置即文件首行首字符开始移动 x 个字符
seek(x,1) : 表示从当前位置往后移动x个字符
seek(-x,2):表示从文件的结尾往前移动x个字符
from_what 值为默认为0,即文件开头。下面给出一个完整的例子:
>>> f = open('foo.txt', 'rb+')
>>> f.write(b'0123456789abcdef')
16
>>> f.seek(5) # 移动到文件的第六个字节
5
>>> f.read(1)
b'5'
>>> f.seek(-3, 2) # 移动到文件的倒数第三字节
13
>>> f.read(1)
b'd'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在文本文件中 (那些打开文件的模式下没有 b 的), 只会相对于文件起始位置进行定位。
当你处理完一个文件后, 调用 f.close() 来关闭文件并释放系统的资源,如果尝试再调用该文件,则会抛出异常。
>>> f.close()
>>> f.read()
Traceback (most recent call last):
File "" , line 1, in ?
ValueError: I/O operation on closed file- 1
- 2
- 3
- 4
- 5
当处理一个文件对象时, 使用 with 关键字是非常好的方式。在结束后, 它会帮你正确的关闭文件。 而且写起来也比 try - finally 语句块要简短:
>>> with open('/tmp/foo.txt', 'r') as f:
... read_data = f.read()
>>> f.closed
True- 1
- 2
- 3
- 4
4、使用 json 存储结构化数据
从文件中读写字符串很容易。数值就要多费点儿周折,因为 read() 方法只会返回字符串,应将其传入 int() 这样的函数,就可以将 ‘123’ 这样的字符串转换为对应的数值 123。当你想要保存更为复杂的数据类型,例如嵌套的列表和字典,手工解析和序列化它们将变得更复杂。
Python 允许你使用常用的数据交换格式 JSON(JavaScript Object Notation)。标准模块 json 可以接受 Python 数据结构,并将它们转换为字符串表示形式;此过程称为 序列化。从字符串表示形式重新构建数据结构称为 反序列化。序列化和反序列化的过程中,表示该对象的字符串可以存储在文件或数据中,也可以通过网络连接传送给远程的机器。
如果你有一个对象 x,你可以用简单的一行代码查看其 JSON 字符串表示形式:
>>> json.dumps([1, 'simple', 'list'])
'[1, "simple", "list"]'- 1
- 2
dumps() 函数的另外一个变体 dump(),直接将对象序列化到一个文件。所以如果 f 是为写入而打开的一个 文件对象,我们可以这样做:
json.dump(x, f)- 1
为了重新解码对象可以采用:
x = json.load(f)- 1
我们来编写一个存储一组数字的简短程序,再编写一个将这些数字读取到内存中的程序,第一个程序使用json.dump()来储存这组数字,第二个程序将使用json.load()
函数json.dump()接受两个实参:要储存的数据以及可以用于存储数据的文件对象。下面是演示
- 示例一
import json
number = [1,2,3,5]
file_name = 'number.json' #通过扩展名指纹文件存储的数据为json格式
with open(file_name,'w') as file_object:
json.dump(number,file_object)- 1
- 2
- 3
- 4
- 5
我们先导入json模块,再创建一个是数字列表,我们指定存放在number.json里,文件后缀是.json来指出文件存储的数据是json格式,我们再以写入模式打开文件,让json能见数据写入其中使用json.dump()将数据写入,我们没有写输出语句,打开这个文件查看,数据存储的格式与python一样。
注意json.dump()方法,传递两个参数 第一个要写入的数据,第二个要存储的位置的文件对象。
- 示例二
再写一个程序,使用json.load()读取到内存中
import json
file_name = 'number.json' #通过扩展名指纹文件存储的数据为json格式
with open(file_name,'r') as file_object:
contents = json.load(file_object)
print(contents)- 1
- 2
- 3
- 4
- 5
这是在程序间共享数据的简单方式
- 保存和读取用户生成的数据
对于用户输入的数据,用json来保存大有裨益,因为如果不以某种方式进行存储,等程序停止运行时用户的信息将丢失。 看一个例子
用户首次运行程序时被提示输入自己的名字,再次运行程序时就记住他了,我们先储存名字
ipt = input('enter your name')
filename1 = 'name.json'
with open(filename1,'w') as file_object:
json.dump(ipt, file_object)- 1
- 2
- 3
- 4
再读取之前存储的名字
with open(filename1,'r') as file_object:
name_ipt = json.load(file_object)
print('wleccome %s'%name_ipt)- 1
- 2
- 3
我们将这两个程序合并到一个内,在执行的时候先去name.json尝试获得用户名,如果没有这文件,用try-except处理这个错误,并入用户输入名字并保存到name.json中
import json
filename1 = 'name.json'
try:
with open(filename1)as file_object:
username = json.load(file_object)
except FileNotFoundError:
with open(filename1,'w') as file_object2:
user_ipt = input('enter your name i will rember you: ')
json.dump(user_ipt,file_object2)
else:
print(username)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
三、OS模块常用方法
Python的os模块提供了执行文件处理操作,如重命名和删除文件的方法。要使用这个模块,需要先导入它,然后就可以调用任何相关的功能了。
1、重命名和删除文件
- rename() 方法
rename()方法有两个参数,当前文件名和新的文件名。
os.rename(current_file_name, new_file_name)- 1
示例
以下为例子用来重命名现有文件 test1.txt 为 test2.txt:
#!/usr/bin/python3
import os
# Rename a file from test1.txt to test2.txt
os.rename( "test1.txt", "test2.txt" )- 1
- 2
- 3
- 4
- 5
- remove() 方法
可以使用 remove()方法通过提供参数文件名称(file_name)来删除文件。
os.remove(file_name)- 1
示例
下面是删除现有文件 test2.txt 的例子 -
#!/usr/bin/python3
import os
# Delete file test2.txt
os.remove("text2.txt")- 1
- 2
- 3
- 4
- 5
2、Python目录
所有的文件都包含不同的目录中,Python处理这些目录操作也没有什么问题。os模块中有用于创建,删除和更改目录的几种方法。
- mkdir() 方法
可以使用os模块中的 mkdir()方法在当前目录下创建目录。需要提供一个参数到这个方法指定要创建的目录名。
os.mkdir("newdir")- 1
示例
下面是在当前目录创建 test 目录的例子 -
#!/usr/bin/python3
import os
# Create a directory "test"
os.mkdir("test")- 1
- 2
- 3
- 4
- 5
- chdir() 方法
可以使用 chdir() 方法来改变当前目录。chdir() 方法接受一个参数,就是你想在当前目录创建的目录的目录名称。
os.chdir("newdir")- 1
示例
以下是进入 “/home/newdir” 目录的例子-
#!/usr/bin/python3
import os
# Changing a directory to "/home/newdir"
os.chdir("/home/newdir")- 1
- 2
- 3
- 4
- 5
- getcwd()方法
getcwd()方法显示当前的工作目录。
os.getcwd()- 1
示例
以下是获得当前目录的例子 -
#!/usr/bin/python3
import os
# This would give location of the current directory
os.getcwd()- 1
- 2
- 3
- 4
- 5
- rmdir() 方法
rmdir()方法删除目录,这是作为方法的参数传递。
删除目录前,它的所有内容应该先删除。
os.rmdir('dirname')- 1
示例
以下是删除 “/tmp/test” 目录的例子。它需要给定目录的完全合格的名称,否则会从当前目录搜索目录。
#!/usr/bin/python3
import os
# This would remove "/tmp/test" directory.
os.rmdir( "/tmp/test" )