160. 相交链表
编写一个程序,找到两个单链表相交的起始节点。
示例 1:

image.png
- 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
- 输出:Reference of the node with value = 8
- 输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:
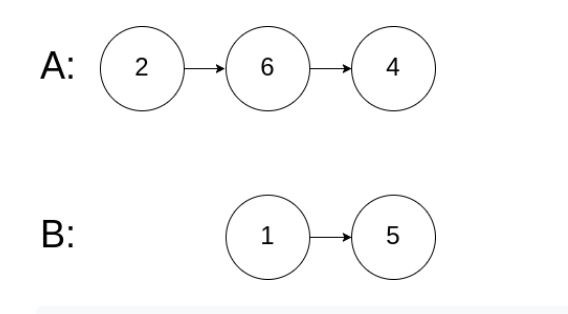
image.png
- 输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
- 输出:null
- 输入解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
- 解释:这两个链表不相交,因此返回 null。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/intersection-of-two-linked-lists
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
-
1.常规解法
思路:
1.分别计算出链表 A 和 B 的长度 lenA 和 lenB
2.|lenA - lenB| 计算出长度差 abs,让长度较长的链表先走 abs
3.在比较 pA == pB 相等返回即可
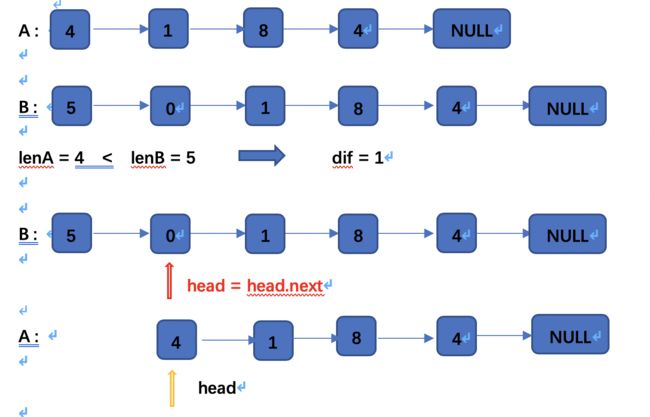
image.png
public static class ListNode {
private int val;
private ListNode next;
public ListNode(int val) {
this.val = val;
}
}
public static ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) return null;
ListNode pA = headA;
ListNode pB = headB;
int lenA = 0, lenB = 0;
while (pA != null) {
lenA++;
pA = pA.next;
}
while (pB != null) {
lenB++;
pB = pB.next;
}
pA = headA;
pB = headB;
int dif = lenA - lenB;
if (dif > 0) {
while (dif != 0) {
dif--;
pA = pA.next;
}
} else {
int abs = Math.abs(dif);
while (abs != 0) {
abs--;
pB = pB.next;
}
}
while (pA != pB) {
pA = pA.next;
pB = pB.next;
}
return pA;
}
复杂度分析:
时间复杂度:O(n)
空间复杂度:O(1),只需要常数级别的空间
-
2.双指针法
思路:
1.初始化两个指针 pA pB 分别指向两个链表的头节点
2.分别遍历这两个链表,如果 pA == null,则把 pA = headB;而 pb == null 时,把 pB = headA
这样做的目的是消除两个链表的长度差
3.当 pA == pB 时,就是我们要找的相交链表
public static ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) return null;
ListNode pA = headA, pB = headB;
while (pA != pB) {
pA = pA == null ? headB : pA.next;
pB = pB == null ? headA : pB.next;
}
return pA;
}
复杂度分析:
时间复杂度:O(n)
空间复杂度:O(1)
-
3.set集合法
思路:
1.将链表 A 添加到set集合中
2.遍历链表 B, 判断set中是否包含 pB, 如果包含,返回pB即可,不包含则 pB = pB.next
public static ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) return null;
Set set = new HashSet<>();
ListNode pA = headA;
ListNode pB = headB;
while (pA != null) {
set.add(pA);
pA = pA.next;
}
while (pB != null) {
if (set.contains(pB)) {
return pB;
} else {
pB = pB.next;
}
}
return null;
}
复杂度分析:
时间复杂度:O(n)
空间复杂度:O(n),由于使用了set 存储链表元素,所以空间复杂度为O(n)
-
4.入栈法
思路:
1.将两个链表分别压入栈
2.每次比较栈顶元素是否相同, 如果相同,则出栈,直到元素不相同位置,返回上一个出栈的元素即可
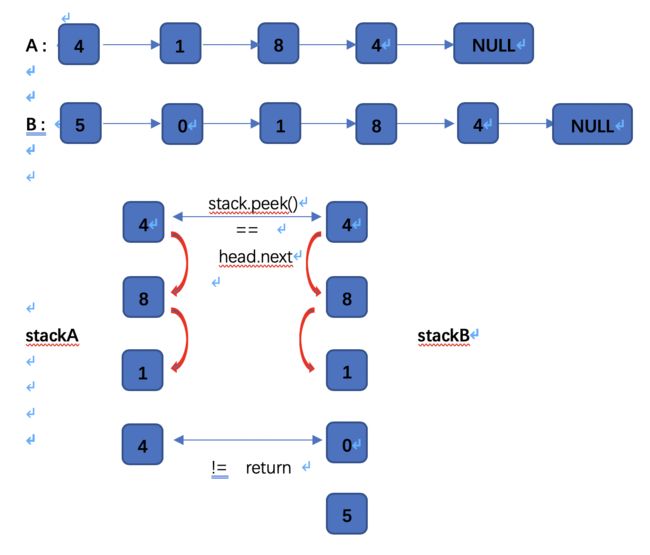
image.png
public static ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) return null;
Stack stackA = new Stack<>();
Stack stackB = new Stack<>();
ListNode pA = headA;
ListNode pB = headB;
while (pA != null) {
stackA.push(pA);
pA = pA.next;
}
while (pB != null) {
stackB.push(pB);
pB = pB.next;
}
ListNode res = null;
while (!stackA.empty() && !stackB.empty() && stackA.peek() == stackB.peek()) {
res = stackA.peek();
stackA.pop();
stackB.pop();
}
return res;
}
复杂度分析:
时间复杂度:O(n)
空间复杂度: O(n),由于开辟了多余的栈空间,导致时间复杂度很高
-
源码
-
我会随时更新新的算法,并尽可能尝试不同解法,如果发现问题请指正
- Github