Python爬虫:短视频平台无水印下载

本博客所写爬取规则最近更新日期为:2020/8/18
新增:快手用户视频下载,抖音火山版/火山极速版用户下载,最右单个视频下载
日常跳转:
- 导入:
- 分平台解释:
- 皮皮虾
- 皮皮搞笑
- 抓包分析
- 源码及结果
- 抖音 / 抖音极速版
- 抓包分析
- 代码及结果
- 小优化:
- 腾讯微视
- 抓包及分析
- 代码及结果
- 开眼 Eyepetizer
- 抓包分析
- 代码及结果
- 快手/快手极速版
- 单个视频下载
- 抓包分析
- 代码及结果
- 用户视频下载
- 抓包分析
- 代码及结果
- 抖音火山版/火山极速版
- 单个视频下载
- 代码及结果:
- 用户视频下载
- 抓包分析
- 代码及结果:
- 最右
- 单个视频下载
- 代码及结果
- 编写中。。。
导入:
虽然目前有些软件还没适配,但是,我发了 Blink 后有一写人留言或者私信找我要源码,不过我还在增加适配的软件,所以还没有时间写这篇博客,今天呢,就先把我目前适配了的代码拿出来,后续还会继续适配的!
分平台解释:
皮皮虾
皮皮虾的话,我之前就已经写过一个单独的博客了,这里就不再赘述:—> Python爬虫:皮皮虾短视频无水印下载
皮皮搞笑
皮皮搞笑与皮皮虾很类似,也是先获取分享链接,在电脑端进行分析:

抓包分析

我们可以很容易的在抓包资源 HXR 中找到某一固定的链接: https://h5.ippzone.com/ppapi/share/fetch_content ,在该链接中的 video 字段可以看到有两个链接,分别打开尝试一下可以发现: 后缀含有 wm 的链接是含有水印的视频,另一个则是我们的目标链接了,但是我们又发现,在 video 字段下,还有一个全是数字的字符串,我们在当前 json 文件中搜索额可以发现:

在上一个标签 img 下,有一个 id 字段,和字符串标签一样。
知道了视频链接的存放位置和获取方式,接下来开始分析请求:


在尝试过几次抓包后发现,请求 URL 始终都没有变化,只是下面的 请求负载 有所变化,第三个参数 post 默认不变就好,至于前两个参数,都在分享链接跳转的链接中:
https://h5.ippzone.com/pp/post/350259149175?zy_to=copy_link&share_count=1&m=0cd13da8548a1bc85813d8c60d331e22&app=&type=post&did=d2bddf23159ae495&mid=1270840711117&pid=350259149175
源码及结果
一切准备工作做好后,开始编写代码:
class PPGX(): # 皮皮搞笑
def __init__(self, url):
s_url = url
self.headers = {
'Host': 'share.ippzone.com',
'Origin': 'http://share.ippzone.com',
'Referer': s_url,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.52'
}
self.JSON = {
"pid": int(str(s_url).split('=')[-1]),
"mid": int(str(s_url).split('&')[-2].split('=')[-1]),
"type": "post"
}
def ppgx_download(self):
URL = 'http://share.ippzone.com/ppapi/share/fetch_content'
r = requests.post(URL, proxies=proxy, headers=self.headers, json=self.JSON)
video_name = r.json()['data']['post']['content'].replace(' ','')
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = r.json()['data']['post']['videos'][str(r.json()['data']['post']['imgs'][0]['id'])]['url']
video = requests.get(video_url, proxies=proxy).content
with open(path + str(video_name) + '.mp4', 'wb') as f:
f.write(video)
print("【皮皮搞笑】: {}.mp4 无水印视频下载完成!".format(video_name))
结果:

抖音 / 抖音极速版
接下来以 抖音 为例(抖音极速版的解析方式和抖音相同):
同样的思路,拿到分享链接到电脑浏览器中抓包分析:

拿到如下信息:
摆摊的第二天……#架子鼓演奏 #架子鼓 #乐器 #听心 https://v.douyin.com/JMKHkqt/ 复制此链接,打开【抖音短视频】,直接观看视频!
所以为了方便,使用正则表达式来提取该内容中的链接:
url = re.findall('(https?://[^\s]+)', s_url)[0] # 正则提取字符串中的链接
抓包分析

我们可以在抓包资源 HXR 中找到某一请求,在该 json 文件中 play_addr 字段下可以找到视频链接,用浏览器打开:

该链接跳转到了视频是没错,不过直接跳转到了又水印的链接上,这就有点卡住了。
不过,按照皮皮搞笑的链接区分来看, wm 是含有水印的视频的话。
https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f750000bsegsdpphaglno4mqd8g&ratio=720p&line=0
当我们删掉链接中的 wm 字段后:

没有加载??????? 而且我们可以发现链接根本都还没有跳转。
但是: 当我们把设备切换为手机时: 链接跳转到了无水印的视频链接:

代码及结果
当一切都分析完后,开始编写代码:
注意: 当我们去掉 wm 字段后,下载视频时,需要带上模拟手机端的请求头!
class DY(): # 抖音
headers = { # 模拟手机端
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1 Edg/84.0.4147.105'
}
def __init__(self, s_url):
self.url = re.findall('(https?://[^\s]+)', s_url)[0] # 正则提取字符串中的链接
def dy_download(self):
rel_url = str(requests.get(self.url, proxies=proxy, headers=self.headers).url)
if 'video' == rel_url.split('/')[4]:
URL = 'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=' + rel_url.split('/')[5] + '&dytk='
r = requests.get(URL, proxies=proxy, headers=self.headers)
video_url = r.json()['item_list'][0]['video']['play_addr']['url_list'][0].replace('/playwm/', '/play/')
video_name = r.json()['item_list'][0]['share_info']['share_title'].split('#')[0].split('@')[0].replace(' ','')
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video = requests.get(video_url, proxies=proxy, headers=self.headers).content
with open(path + str(video_name) + '.mp4', 'wb') as f:
f.write(video)
print("【抖音短视频】: {}.mp4 无水印视频下载完成!".format(video_name))成!".format(video_name))
结果:由于抖音和抖音极速版的分享内容是一样的,无法分辨哪个平台,所以统一输出。

但是: 我发现抖音没事就爱搞幺蛾子,有时分享链接是上文所示:
有时又是一段原链接…所以我,做了一点小小的优化:
小优化:
if 'www.iesdouyin.com' in self.s_url:
print("【抖音短视频】: {}.mp4 无水印视频下载完成!".format(video_name))
if 'v.douyin.com' in self.s_url:
print("【抖音短视频/抖音极速版】: {}.mp4 无水印视频下载完成!".format(video_name))
腾讯微视
套路依旧,获取分享链接:

拿到链接:
上不上班无所谓,主要是想蹦迪>>https://h5.weishi.qq.com/weishi/feed/6XSB277Nr1K5nIKb6/wsfeed?wxplay=1&id=6XSB277Nr1K5nIKb6&spid=8813798054214369280&qua=v1_and_weishi_8.0.6_588_312028000_d&chid=100081014&pkg=3670&attach=cp_reserves3_1000370011
抓包及分析
注意: 这里是一个写爬虫的常用思路:将设备切换为手机,因为相对于电脑端,手机端的健壮性没有电脑端好,所以很多东西都可以通过这种方式来抓取,就如这个例子:
未切换:
已切换:

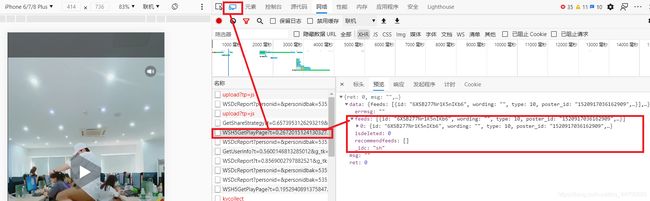
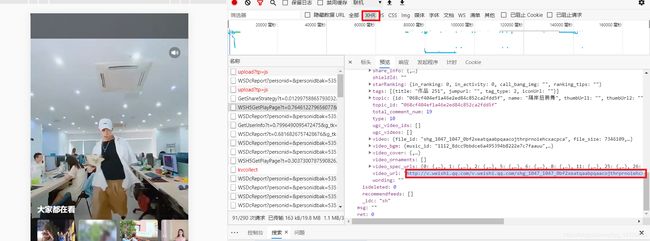
依次检查请求后发现:链接也就摆放在 json 数据中。
那么,接下来直接分析请求:

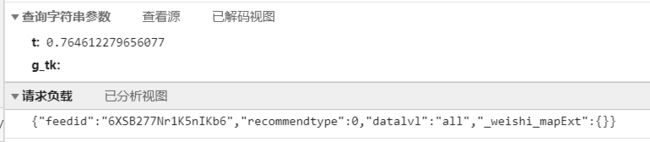
对于 请求负载 中的参数,我们可以直接在请求链接中截取:
https://h5.weishi.qq.com/weishi/feed/6XSB277Nr1K5nIKb6/wsfeed?wxplay=1&id=6XSB277Nr1K5nIKb6&spid=8813798054214369280&qua=v1_and_weishi_8.0.6_588_312028000_d&chid=100081014&pkg=3670&attach=cp_reserves3_1000370011
其他的参数默认就好,而至于请求链接,同一个视频刷新几次,参数 t 就有多少个值:
https://h5.weishi.qq.com/webapp/json/weishi/WSH5GetPlayPage?t=0.764612279656077&g_tk=
https://h5.weishi.qq.com/webapp/json/weishi/WSH5GetPlayPage?t=0.3168301677339891&g_tk=
https://h5.weishi.qq.com/webapp/json/weishi/WSH5GetPlayPage?t=0.8888910469548954&g_tk=
…
而且,有时候长度都不一样,这就把我吓到了!什么加密?这么复杂!
既然同一个视频每次刷新都不一样,是不是跟时间戳有关系???但是这明显不是啊!
正在我为这个参数发愁时,我也不知道我当时是怎么想的,无聊,随机修改了参数 t 的几个数字发现,仍然能够获取到视频!!!!!!!
然后我发现:所有的数全是在 0—1 之间变化,我用Python的 random 产生了一组随机数来看:
import random
print(random.random())
# 结果:
# 0.5890812460827893
我都惊呆了!!就是这种数据啊!我用这个随机数去请求时,结果居然是可行的,这…
居然误打误撞的给破解了…
代码及结果
class TXWS(): # 腾讯微视
headers = { # 模拟手机端
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1 Edg/84.0.4147.105'
}
def __init__(self, s_url):
self.url = re.findall('(https?://[^\s]+)', s_url)[0] # 正则提取字符串中的链接
self.data = {
'datalvl': "all",
'feedid': str(self.url).split('/')[5],
'recommendtype': '0',
'_weishi_mapExt': '{}'
}
def txws_download(self): # 参数 t 为随机数
url = 'https://h5.weishi.qq.com/webapp/json/weishi/WSH5GetPlayPage?t={}&g_tk='.format(random.random())
r = requests.post(url, proxies=proxy, headers=self.headers, data=self.data)
video_name = r.json()['data']['feeds'][0]['feed_desc'].replace(' ','')
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = r.json()['data']['feeds'][0]['video_url']
video = requests.get(video_url, proxies=proxy, headers=self.headers).content
with open(path + str(video_name) + '.mp4', 'wb') as f:
f.write(video)
print("【腾讯微视】: {}.mp4 无水印视频下载完成!".format(video_name))
结果:

开眼 Eyepetizer
虽然 开眼 下载的视频,并没有水印,但是下载好的视频只能在软件内观看,但是我还是想让它下载到它该下载的地址:
套路,套路,还是套路:

抓包分析
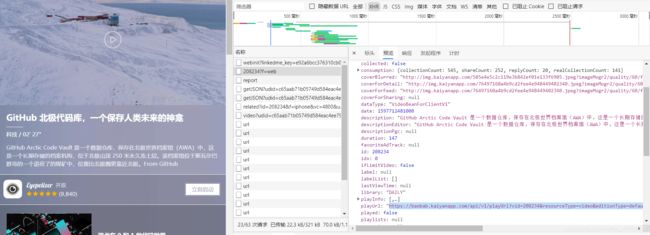
还是很简单的,没什么反爬机制,很容易就会找到了视频的下载地址,接下来直接分析请求:

请求链接中只有几个数字需要解析,但是我们发现,它就出现在分享链接中:
https://www.eyepetizer.net/detail.html?vid=208234&utm_campaign=routine&utm_medium=share&utm_source=others&uid=0&resourceType=video&udid=c65aab71b05749d584eac4ee7944bb6274e17596&vc=6030061&vn=6.3.6&size=1080X2070&deviceModel=9&first_channel=xiaomi&last_channel=xiaomi&system_version_code=27
代码及结果
class KY_Eyepetizer(): # 开眼
def __init__(self, url):
self.vid = str(url).split('=')[1].split('&')[0]
self.headers = {
'origin': 'https://www.eyepetizer.net',
'referer': url,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.58'
}
def ky_download(self):
url = 'https://baobab.kaiyanapp.com/api/v1/video/{}?f=web'.format(self.vid)
r = requests.get(url, proxies=proxy, headers=self.headers)
video_name = r.json()['title'].replace(' ','')
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = r.json()['playUrl']
video = requests.get(video_url, proxies=proxy, headers=self.headers).content
with open(path + str(video_name) + '.mp4', 'wb') as f:
f.write(video)
print("【开眼 Eyepetizer】: {}.mp4 无水印视频下载完成!".format(video_name))
结果:

快手/快手极速版
单个视频下载
我们还是以快手为例(快手极速版的解析规则和快手一样):
依旧按照套路来,不过因为快手的限制,必须登录才能分享:

抓包分析
按照以前的套路,将链接粘贴到浏览器,F12 抓包,结果并没有获取到任何与当前视频链接相关的信息,既然不在 json 文件中,难道在网页源码中???去挨个儿查看后,也不是,这该怎么爬取呢??
别忘了我前面提到的方法:更改设备。
当我把设备换成手机端后,json 数据中也还是没有相关数据,不过!!我在网页源码中找到了我们想要的链接:

到这里我们也已经找到了链接存放的地址,接下来则是,如何在这么多的字符里将链接提取出来呢???
答案是: 使用正则表达式 。
代码及结果
class KS(): # 快手
def __init__(self, s_url):
self.s_url=s_url.replace('\n','')
self.url = re.findall('(https?://[^\s]+)', s_url)[0] # 正则提取字符串中的链接
self.headers = {
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1 Edg/84.0.4147.105'
}
def ks_download(self):
html = requests.get(self.url, headers=self.headers).text
video_name = re.findall('name":"(.*?)"', html)[0].replace(' ','')
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = re.findall('srcNoMark":"(.*?)"', html)[0]
video = requests.get(video_url, proxies=proxy, headers=self.headers).content
with open(path + str(video_name) + '.mp4', 'wb') as f:
f.write(video)
if '【快手App】' in self.s_url:
print("【快手】: {}.mp4 无水印视频下载完成!".format(video_name))
elif '【快手极速版App】' in self.s_url:
print("【快手极速版】: {}.mp4 无水印视频下载完成!".format(video_name))
结果:

用户视频下载
同样的我们拿到用户首页的分享地址:
看了这么多快手,还是「贝贝兔很」最好玩了! https://v.kuaishou.com/69cjtE 复制此链接,打开【快手】直接观看!
抓包分析
还是一贯的套路,更改设备,模拟手机向下刷新发现:

在新加载出的 json 文件中,含有两个重要信息:
- feeds :包含第19条到37条的视频信息(不是链接,而是一个中亚参数,我后面会提到怎么使用)。
- pcursor :请求某一部分视频的重要参数。
既然包含了第19条到37条的视频,那么第1到第18条的视频信息在哪里呢?
根据前面的教训,我直接查看了切换到移动设备时的源码发现:

这里确实是有18条数据,而且每一个链接直接导向了该视频的首页,那么解析方式就和单个视频的下载方式一样了!
对于这18条数据,我们同样可以用正则表达式直接提取,但是后面的几十条数据就需要我们来进行解析了。
我们从新加载的 json 文件中可以看到,这里面包含了很多信息,但是却没有视频的链接,但是,既然刷新又必须加载它,说明肯定有什么重要的东西:
后来我发现正则表达式提取出的链接都有像是之处,所以我拿出了几个用正则表达式提取出的链接。(默认前缀)
/fw/photo/3x3m9e644ep95qg?cc=share_copylink&fid=574031739&shareId=227013708994&shareToken=X8rcLJByeLfC10c_A&appType=21&kpn=KUAISHOU
/fw/photo/3xggwttf4kquza9?cc=share_copylink&fid=574031739&shareId=227013708994&shareToken=X8rcLJByeLfC10c_A&appType=21&kpn=KUAISHOU
…
我发现对于同一个用户,所有视频的基本形式除了黄色部分不一样以外,其余的都是固定的!这不就是一个参数的问题嘛, json 文件中那么多的数据,不信找不到:我一一尝试后终于找到了那个参数:
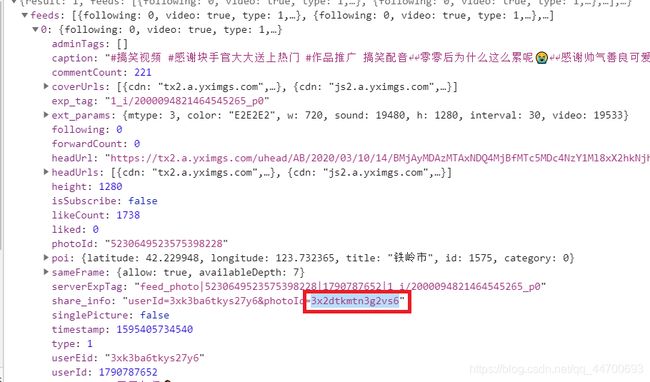
既然我们已经知道如何拼接每个视频的链接,那么,最主要的就是如何获取那个视频的关键参数。
我前面已经说了,在 json 文件中的 pcursor 字段很是重要!
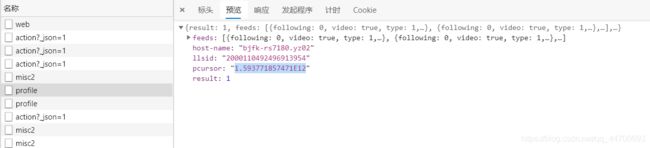
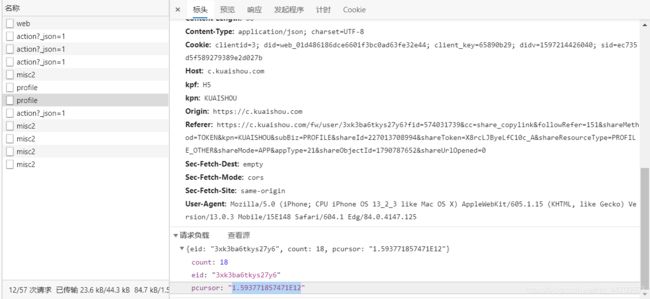
我尝试多次后终于发现发现:前一个 post 请求所返回数据中的 pcursor 字段的值,就是下一次请求所需要的参数!而两次请求中,视频的顺序刚好和用户的一样,所以如何请求后续的视频信息,我们已经知道方法了,不过,第一次的请求的参数是怎么来的呢??

解决: 在编写代码时,我给第一次 post 请求的参数 pcursor 赋了个空值,也是能够请求成功的!
而请求结束的标志就是:pcursor 字段的值等于 no_more:

代码及结果
class KS(): # 快手
def __init__(self, s_url):
self.s_url=s_url.replace('\n','')
self.url = re.findall('(https?://[^\s]+)', s_url)[0] # 正则提取字符串中的链接
self.headers = {
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1 Edg/84.0.4147.105'
}
self.video_list = []
self.rel_url = requests.get(self.url, proxies=proxy, headers=self.headers) # 真实网址
def ks_download(self):
if 'user' != self.rel_url.url.split('/')[4]:
self.ks_download_video()
if 'user' == self.rel_url.url.split('/')[4]:
self.ks_download_user()
def ks_download_video(self):
video_name = re.findall('name":"(.*?)"', self.rel_url.text)[0].replace(' ', '')
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = re.findall('srcNoMark":"(.*?)"', self.rel_url.text)[0]
video = requests.get(video_url, proxies=proxy, headers=self.headers).content
with open(path + str(video_name) + '.mp4', 'wb') as f:
f.write(video)
if '【快手App】' in self.s_url:
print("【快手】: {}.mp4 无水印视频下载完成!".format(video_name))
elif '【快手极速版App】' in self.s_url:
print("【快手极速版】: {}.mp4 无水印视频下载完成!".format(video_name))
def ks_download_user(self):
global user_name
headers = {
'Cookie': '粘贴自己的Cookie信息',
'Origin': 'https://c.kuaishou.com',
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1 Edg/84.0.4147.125'
}
rel_url = requests.get(self.url, proxies=proxy, headers=headers) # 真实网址
user_name = re.findall('(.*?)', rel_url.text)[-1]
if os.path.exists(path + user_name + '/'):
pass
else:
os.makedirs(path + user_name + '/')
videos = re.findall(' + video1)
pcursor = ''
url = 'https://c.kuaishou.com/rest/kd/feed/profile'
flag = 1
while flag:
data = {"eid": str(rel_url.url).split('/')[-1].split('?')[0], "count": 18, "pcursor": pcursor}
r = requests.post(url, proxies=proxy, headers=headers, json=data)
for video2 in tqdm(r.json()['feeds'], desc='正在准备视频链接: '):
photoId = video2['share_info'].split('=')[-1]
temp_last = '?' + self.video_list[0].split('?')[-1]
self.video_list.append('https://c.kuaishou.com/fw/photo/' + photoId + temp_last)
pcursor = r.json()['pcursor']
if r.json()['pcursor'] == "no_more":
flag = 0
print('用户 {} 共 {} 个视频!'.format(user_name,len(self.video_list)))
for video_url in self.video_list:
html = requests.get(video_url, headers={
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X)'}) # 真实网址
print(html.text)
video_name = int(random.random() * 2 * 1000)
video_url = re.findall('srcNoMark":"(.*?)"', html.text)[0]
video = requests.get(video_url, proxies=proxy, headers=headers).content
with open(path + user_name + '/' + str(video_name) + '.mp4', 'wb') as f:
f.write(video)
print("【快手】: {}.mp4 无水印视频下载完成!".format(video_name))
结果:
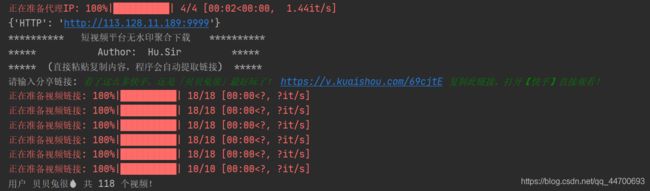
抖音火山版/火山极速版
单个视频下载
对于这两个软件的解析,其实我是偷懒了,嘿嘿嘿,我翻看以前别人的博客,细细研究后发现了一个快手视频解析的接口:
其实很抱歉我忘记了我在哪个地方看到的那片文章,通过那篇文章,我们可以获取到原火山小视频的视频加载api :
https://api-hl.huoshan.com/hotsoon/item/video/_source/?item_id=6859730122820291840 原火山小视频无水印接口
https://api.huoshan.com/hotsoon/item/video/_reflow/?item_id=6859730122820291840 抖音火山版水印接口
https://api.huoshan.com/hotsoon/item/video/_source/?item_id=6859730122820291840 抖音火山版无水印接口
现在,已经知道视频加载的 api 后,就只需获取视频的 item_id 参数了。这个参数在跳转链接中就可以找到。
代码及结果:
所以我直接写出来解析代码:
class DY_HSB():
headers = { # 模拟手机
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1 Edg/84.0.4147.105'
}
def __init__(self, s_url):
self.s_url=s_url
self.url = re.findall('(https?://[^\s]+)', s_url)[0] # 正则提取字符串中的链接
def dyhsb_download(self):
rel_url = str(requests.get(self.url, proxies=proxy, headers=self.headers).url)
video_name = int(random.random() * 2 * 1000)
video_url = 'https://api.huoshan.com/hotsoon/item/video/_source/?item_id=' + \
rel_url.split('=')[1].split('&')[0]
video = requests.get(video_url, proxies=proxy, headers=self.headers).content
with open(path + str(video_name) + '.mp4', 'wb') as f:
f.write(video)
if '【抖音火山版】' in self.s_url:
print("【抖音火山版】: {}.mp4 无水印视频下载完成!".format(video_name))
elif '【火山极速版】' in self.s_url:
print("【火山极速版】: {}.mp4 无水印视频下载完成!".format(video_name))
结果:因为这个 api 无法获取其余信息,所以就以随机数来命名。


用户视频下载
我们还是拿到用户首页的分享链接:
「天使航拍」也在抖音火山版,快来看 TA 的精彩作品吧!「天使航拍」上传了 173 个视频作品,一起来围观>>https://share.huoshan.com/hotsoon/s/FJ0C7M5rWa8/ 复制此链接,打开【抖音火山版】,直接找到TA~
抓包分析

我们可以很快地找到一个用户视频的请求接口,然后拿到视频的 item_id 参数。但是!这个接口好像有参数去限制请求视频的数量,目前我只是试了一下修改请求参数,不过也只能最多爬取该用户40—50 个视频,如果以后有时间,我再去研究一下。
虽然请求参数较多,但是经过我的尝试,只有两个参数是必须的:
- encrypted_id : 在请求跳转链接中以 to_user_id 的参数存在。
- count :请求数量。(但是最多只能请求40—50个??这是怎么回事,我目前还没弄清楚!)
https://share.huoshan.com/pages/user/index.html?to_user_id=MS4wLjABAAAA6iUfN2mZ0H4Z7iLtZQ73TYdXoyTUIjk6oDdVWuRtn_g×tamp=1597806131&share_ht_uid=0&did=67279005018&iid=3113420875114797&utm_medium=huoshan_android&tt_from=copy_link&app=live_stream&utm_source=copy_link&schema_url=sslocal%3A%2F%2Fprofile%3Fid%3D75014355319

代码及结果:
class DY_HSB():
headers = { # 模拟手机
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1 Edg/84.0.4147.105'
}
def __init__(self, s_url):
self.s_url=s_url
self.url = re.findall('(https?://[^\s]+)', s_url)[0] # 正则提取字符串中的链接
def dyhsb_download(self):
rel_url = str(requests.get(self.url, proxies=proxy, headers=self.headers).url)
if 'item' == rel_url.split('/')[4]: # 单个视频
video_name = int(random.random() * 2 * 1000)
video_url = 'https://api.huoshan.com/hotsoon/item/video/_source/?item_id=' + \
rel_url.split('=')[1].split('&')[0]
video = requests.get(video_url, proxies=proxy, headers=self.headers).content
with open(path + str(video_name) + '.mp4', 'wb') as f:
f.write(video)
if '【抖音火山版】' in self.s_url:
print("【抖音火山版】: {}.mp4 无水印视频下载完成!".format(video_name))
elif '【火山极速版】' in self.s_url:
print("【火山极速版】: {}.mp4 无水印视频下载完成!".format(video_name))
if 'user' == rel_url.split('/')[4]: # 用户视频
##########
# 缺陷:最多支持下载 40--50 个该用户视频。
##########
to_user_id = rel_url.split('=')[1].split('&')[0]
info_json = requests.get('https://share.huoshan.com/api/user/info?encrypted_id={}'.format(to_user_id))
item_count = info_json.json()['data']['item_count']
user_name = info_json.json()['data']['nickname']
if os.path.exists(path + user_name + '/'):
pass
else:
os.makedirs(path + user_name + '/')
videos_url = 'https://share.huoshan.com/api/user/video?encrypted_id={}&count={}'.format(to_user_id,
item_count)
video_info = requests.get(videos_url, proxies=proxy, headers=self.headers).json()['data']
for info in tqdm(video_info, desc='正在下载用户 {} 的视频:'.format(user_name)):
video_name = int(random.random() * 2 * 1000)
video_url = 'https://api.huoshan.com/hotsoon/item/video/_source/?item_id=' + info['item_id']
video = requests.get(video_url, proxies=proxy, headers=self.headers).content
with open(path + user_name + '/' + str(video_name) + '.mp4', 'wb') as f:
f.write(video)
if '【抖音火山版】' in self.s_url:
print("【抖音火山版】: 用户 {} 的无水印视频下载完成!".format(user_name))
elif '【火山极速版】' in self.s_url:
print("【火山极速版】: 用户 {} 的无水印视频下载完成!".format(user_name))
结果:


最右
依旧是通过拿到分享链接,然后抓包分析:
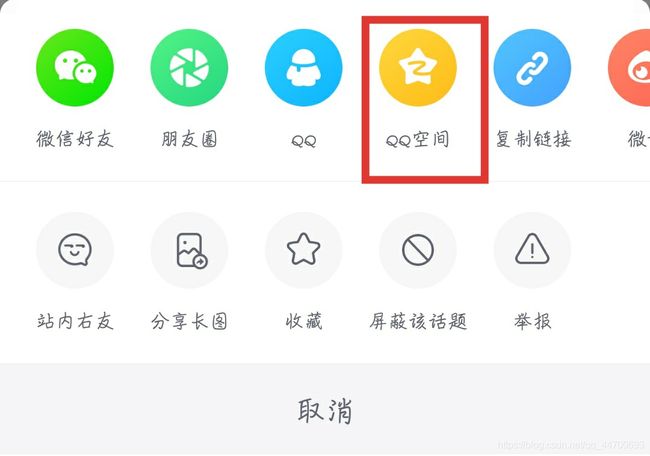
拿到分享链接:
#最右#分享一条有趣的内容给你,不好看算我输。请戳链接>> https://share.izuiyou.com/hybrid/share/post?pid=191652885&zy_to=applink&share_count=1&m=ce86942098b72ec745e740e69ab9f6ec&d=fd238824d489ba3c1d65dfb74793074fd42ce27cafa76630b9eecfd7d657f50c&app=zuiyou&recommend=top_ctr&name=use_push_only&title_type=post
单个视频下载
基本思路也还是不变,更改设备后查看源码,将部分源码提取出来:

…
![]()
将这部分源码拿到 JSON在线解析的网站上去:

虽然提示有错误,不过我们可以编辑一下源码,改正这个错误:
先搜索错误的信息:
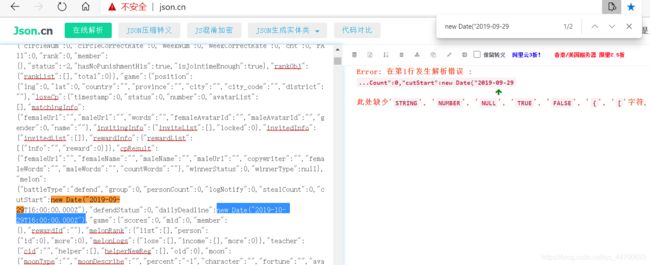
然后修改:

因为这个参数不影响我们的爬取,所以,无论改成什么字符都可以,切记一定要双引号!
随后,经过我的一番查找,终于找到了视频的无水印链接:

由于这并不是标准的 json 数据,所以,我们还是直接用正则表达式来提取。
代码及结果
class ZY(): # 最右
headers = { # 模拟成手机
'Host': 'share.izuiyou.com',
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1 Edg/84.0.4147.105'
}
def __init__(self, s_url):
self.url = re.findall('(https?://[^\s]+)', s_url)[0] # 正则提取字符串中的链接
def zy_download(self):
url_flag = str(self.url).split('/')[3]
html = requests.get(self.url, proxies=proxy, headers=self.headers).text
flag = re.findall('"imgs":\[{"id":(.*?),"h":', html)[0]
video_name = re.findall('{"id":.*?,"share":.*?,"content":"(.*?)","title":"', html)[0].replace(' ','')
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = re.findall(',"thumb":' + flag + ',"playcnt":.*?"url":"(.*?)","prior', html)[0] \
.replace('u002F', '').replace('\\', '/')
video = requests.get(video_url, proxies=proxy).content
with open(path + str(video_name) + '.mp4', 'wb') as f:
f.write(video)
print("【最右】: {}.mp4 无水印视频下载完成!".format(video_name))
结果:
