Densely Connected Convolutional Networks论文解析
最近一段时间在学习computer vision等方面的知识,每周大概会看两篇论文左右,因此想把自己看论文所收获的东西与大家分享。文中的内容都是我主观的看法,因此如有理解错误的地方,欢迎大家指出。转载请注明出处Densely Connected Convolutional Networks论文阅读。(知乎账号为小胖鱼https://www.zhihu.com/people/tu-tu-50-40-9/activities)
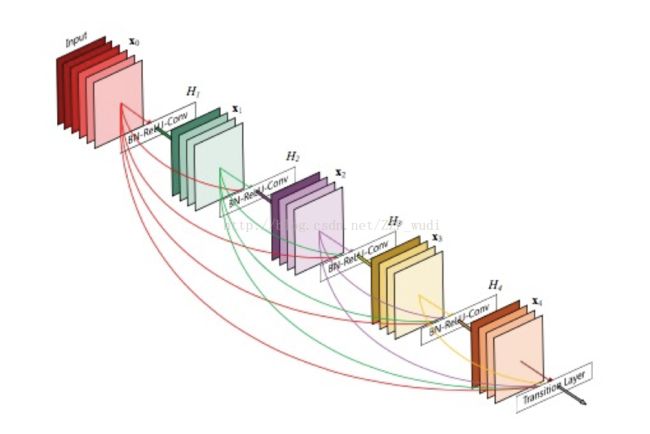
一、解决的问题
随着网络结构的加深,梯度与信息消失现象也就越明显。为了解决这一问题,人们设计出ResNet,Highway Network,FractalNets等。这些网络结构都有一个共同的特点:在每一层与之后的层之间建立捷径来缓解梯度消失这种现象。但是这样也会带来一些问题:巨量的网络参数,网络结构的利用率不高(一些层被有选择地drop掉了) 。因此作者提出了这种新的网络结构,利用当前层与后面层的连结(concatenate)使得每一层的信息得到充分的利用,缓解了梯度消失的同时,极大地减少了参数。
二、网络结构
1. 紧密连接(Dense connectivity)
在DenseNet结构中,讲每一层的输出都导入后面的所有层,与ResNet的相加不同的是,DenseNet结构使用的是连结结构(concatenate)。这样的结构可以减少网络参数,避免ResNet中可能出现的缺点(例如某些层被选择性丢弃,信息阻塞等)。
2. 组成函数(Composite function)
Batch Normalization + ReLU + 3*3 Conv层
3. 过渡层(Transition Layer)
过渡层包含瓶颈层(bottleneck layer,即1*1卷积层)和池化层。
1)瓶颈层
1*1的卷积层用于压缩参数。每一层输出k个feature maps,理论上将每个Dense Block输出为4k个feature maps,然而实际情况中会大于这个数字。卷积层的作用是将一个Dense Block的参数压缩到4k个。
2)池化层
由于采用了Dense Connectivity结构,直接在各个层之间加入池化层是不可行的,因此采用的是Dense Block组合的方式,在各个Dense Block之间加入卷积层和池化层。如图所示:

4. 增长率(Growth rate)
这里的增长率代表的是每一层输出的feature maps的厚度。ResNet,GoogleNet等网络结构中经常能见到输出厚度为上百个,其目的主要是为了提取不同的特征。但是由于DenseNet中每一层都能直接为后面网络所用,所以k被限制在一个很小的数值。
5. 压缩(Compression)
跟1*1卷积层作用类似,压缩参数。作者选择压缩率(theta)为0.5。
包含bottleneck layer的叫DenseNet-B,包含压缩层的叫DenseNet-C,两者都包含的叫DenseNet-BC。
三、创新点
Dense Connectivity
Growth Rate:由于DenseConnectivity结构,可以使得feature maps以较小的厚度达到ResNet等很深厚度才能表达的信息。
四、评估方法
在CIFAR、SVHN、ImageNet进行测试,并比较参数。
五、结果分析
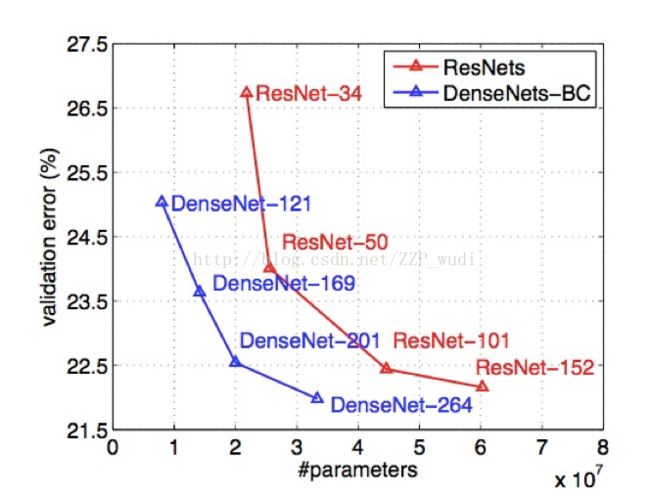
ImageNet测试结果
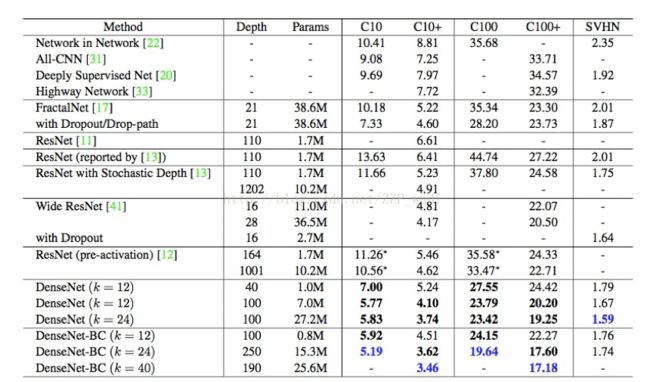
CIFAR/SVHN数据集测试结果(粗体字代表DenseNet结构超过其他网络结构,蓝字代表最好的结果)
1. 准确度
L=190, k=24/40的DenseNet-BC是所有结果中最好的。
L=100, k=24的DenseNet也超过了其它结构的网络。
2. 模型容量
可以通过更深的层数L和厚度k来提高准确度,但也会带来参数数量的大幅增加。可以通过BC来减少参数。
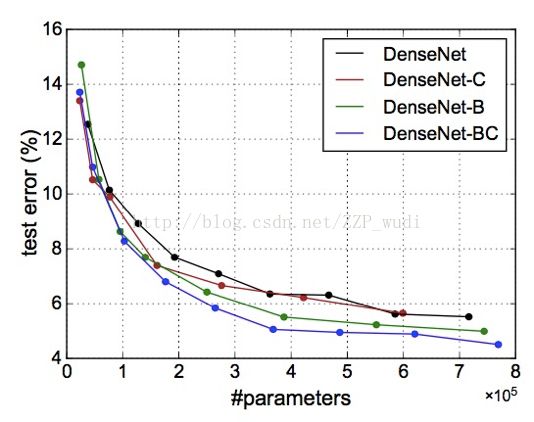
3. 参数
在C10+数据集上各种形式的DenseNet的参数对比结果。
ResNet与DenseNet的参数对比,可以看出相似的精度下,ResNet的参数约为DenseNet-BC的三倍。
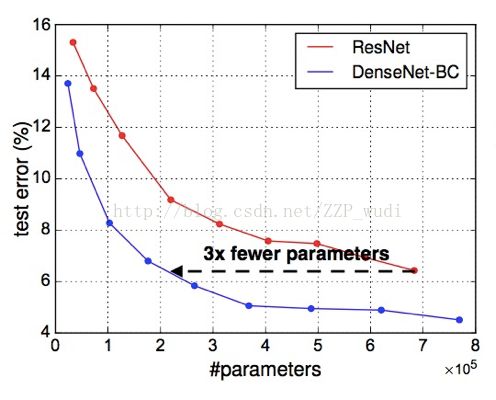
1001层预激活(pre-activationResNet)与DenseNet-BC-100的对比
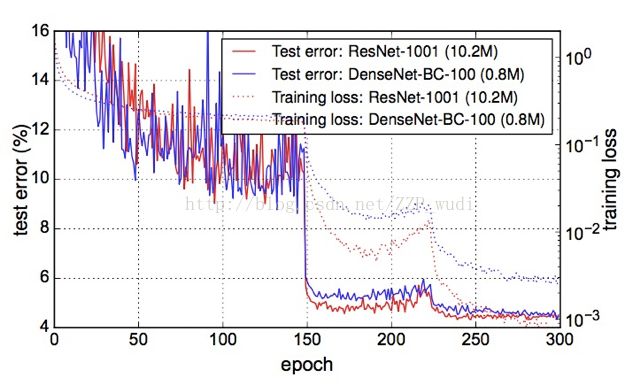
4. 过拟合
在DenseNet的C10数据集中,作者观察到过拟合(5.77-->5.89),但是DenseNet-BC中并没有此现象。因此BC层可能有抑制过拟合的作用。
附录
数据集
1)C10(CIFAR-10数据集)
CIFAR-10数据集包含60000个32*32的彩色图像,共有10类。有50000个训练图像和10000个测试图像。
数据集分为5个训练块和1个测试块,每个块有10000个图像。测试块包含从每类随机选择的1000个图像。训练块以随机的顺序包含这些图像,但一些训练块可能比其它类包含更多的图像。训练块每类包含5000个图像。
类间完全互斥。汽车和卡车类没有重叠。“Automobile”只包含sedans,SUVs等等。“Truck”只包含大卡车。两者都不包含皮卡车。
2)C100 (CIFAR-100数据集)
数据集包含100小类,每小类包含600个图像,其中有500个训练图像和100个测试图像。100类被分组为20个大类。每个图像带有1个小类的“fine”标签和1个大类“coarse”标签。
3)C10+、C100+
代表对C10和C100数据集进行标准的数据增强(dataaugmentation:translation and/or mirroring)
4) SVHN
SVHN是一个真实世界的街道门牌号数字识别数据集.The Street ViewHouse Numbers (SVHN) Dataset。(类似于MNIST)
5)ImageNet
ImageNet 是一个计算机视觉系统识别项目名称, 是目前世界上图像识别最大的数据库。是美国斯坦福的计算机科学家,模拟人类的识别系统建立的。
参考链接
1. https://arxiv.org/abs/1608.06993
2. http://blog.csdn.net/shadow_guo/article/details/48995081