Python爬虫-MongoDB
- Python爬虫-MongoDB
- 前言
- 与MySQL对比
- 启动/关闭MongoDB
- 操作
- 数据库操作
- 集合操作
- 数据操作
- 增
- 删
- 改
- 查
- 保存
- 运算符
- 高级操作
- 聚合
- 常用管道
- 常用表达式
- 安全性
- 与python交互
前言
如果仅考虑自己爬虫自己使用,我是推崇MongoDB的——暴力直接。一个字典insert下去,世界从混沌归于一片宁静。况且与MySQL相比,MongoDB的结构不用固定,其域(也就是MySQL中的列),可以在这个文档中6个,下个文档里4个。也不用考虑数据类型匹不匹配。当然不得不说其实各有千秋的,这里就不深究啦!
由于操作起来着实简单,上篇【二进制记得】也试演过一次,这里就不再实战了。
与MySQL对比
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接/mongodb不支持 | |
| primary key | primary key | 主键/mongodb自动将_id设置主键 |
三原素:数据库,集合,文档
启动/关闭MongoDB
- win :
mongod.exe --dbpath=D:\mongodb\data\db(指定存放路径) - linux :
mongod start/stop
操作
进入shell:mongo
退出shell:exit 
数据库操作
- 查看当前数据库名字:
db - 查看当前数据状态:
db.stats() - 显示所有数据库:
show dbs - 切换数据库:
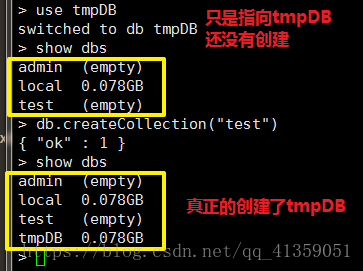
use 数据库名(如果数据库不存在,就指向数据库但不会创建,直到插入数据或是创建集合之后才会创建数据库) - 删除数据库:
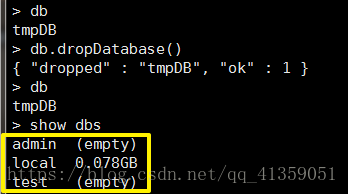
db.dropDatabase()(先切换到将要删除的数据库,删除数据库之后并不会立马退出,但被删除的数据库已经不存在了)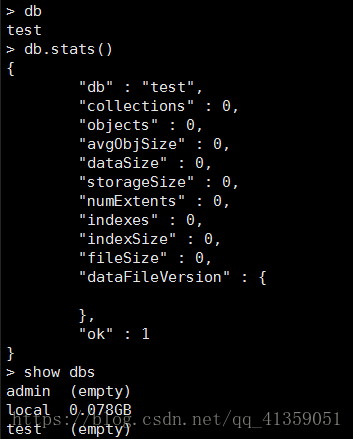
集合操作
- 创建集合:
db.createCollection(name, options)
举例:
a.db.createCollection("comments", {capped:true, size:10, max:2})
b.db.createCollection("comments")(capped默认false,即无上限;size指大小,单位字节;max指数量上限)只有在用了size的情况下才能用max - 查看当前所有集合:
show collections
- 删除集合:
db.集合名.drop()
数据操作
增
db.集合名.insert(document)document是构建的一个json文件(可以类比python中的字典) 
删
db.集合名.remove({条件})db.集合名.remove({条件}, {justOne:true})
以上都不能对创建集合时设置了capped:true的集合删除;对于capped:true的集合,只能删除文档
改
- 更新数据:
db.集合名.update({原属性}, {修改属性}, {multi:true})(默认multi值为false,只更新一条;如果true,表示更新区配到的整个文档)
如果原属性存在,但修改属性里没写,这个属性在修改后就不存在了;相反,如果原属性不存在,但修改属性里有,修改后增加相应的属性 - 指定属性更新数据:
db.集合名.({原属性}, {$set:{属性}}, {multi:true})
与1不同的是,在指定属性更新里面,原属性存在,修改属性里没写不会消失;而原属性不存在,修改属性里写了的,会增加
查
db.集合名.find()显示全部文档 db.集合名.findOne()显示第一条文档 
保存
db.集合名.save{文档}
保存是指,如果主键已经存在,就执行更新(update)功能;如果不存在,就执行插入(insert)功能(主键就是_id,如果没写,系统会自动分配一个)
运算符
$lt/lte/gt/gte/ne,小于/小于等于/大于/大于等于/不等于,默认则等于
用法:db.集合名.find({条件})- and:
db.集合名.find({条件1, 条件2, ...})
满足条件1并且满足条件2,如果没有符合条件的数据,则无返回 - or:
db.集合名.find({$or:[{条件1}, {条件2}]})
满足条件1或者条件2 - and, or的组合使用:
db.集合名.find({$or:[条件1, 条件2...], 条件3, ...})
满足条件1或者条件2的同时,必须满足条件3 - 范围:
db.集合名.find({a:{$in:[1, 2, 3]}})
a的值的范围应该是中括号里枚举出来的范围 - 支持正则,以下图数据为例

使用正则有以下两种方法,结果都是一样的
a.db.comments.find({name:/^黄/})
b.db.comments.find({name:{$regex:"^黄"}})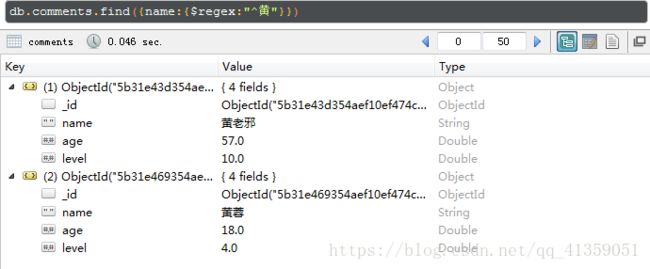
- 自定义查询:
db.集合名.find({$where:function(){return this.age<25}})这里其实利用的是javascript的知识,function(){…}是js中的匿名函数。有编程基础的应该能够看懂,就是返回age值小于25的数据
- 读取指定数量的文档:
db.集合名.find(...).limit(n)表示显示满足条件的前n条数据 跳过指定数量的文档:
db.集合名.find(...).skip(n)表示跳过前n条满足条件的数据,再显示
limit和skip可以一起使用,不分先后顺序
投影(显示自己需要的字段):
db.集合名.find({条件...}, {字段1:1,字段2:1}),这里1表示显示的意思,0为默认值,即不显示,但针对_id字段,必须指定0,才会不显示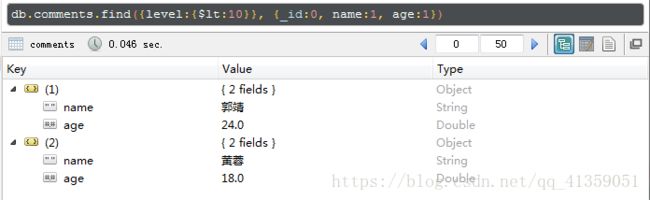
排序:
db.集合名.find().sort({age:1, level:-1})(1表示升序,-1表示降序;先按照age升序,再按照level降序)- 统计个数:
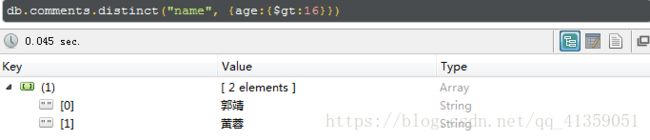
db.集合名.count({条件}) - 消除重复:
db.集合名.distinct("预设字段", {条件}),按条件返回预设字段,如果预设的字段出现重复就去重
高级操作
聚合
db.集合名.aggregate([{管道:{表达式}}])
常用管道
$group:将集合中的文档分组,可用于统计结果
$match:过滤数据,只输出符合条件的文档
$project:修改输入文档的结构,如重命名、增加、删除字段、创建计算结果
$sort:将输入文档排序后输出
$limit:限制聚合管道返回的文档数
$skip:跳过指定数量的文档,并返回余下的文档
$unwind:将数组类型的字段进行拆分
常用表达式
$sum:计算总和,$sum:1同count表示计数
$avg:计算平均值
$min:获取最小值
$max:获取最大值
$push:在结果文档中插入值到一个数组中
$first:根据资源文档的排序获取第一个文档数据
$last:根据资源文档的排序获取最后一个文档数据
==这里不深入,因为我认为爬虫暂时用不到这些功能,用不到的知识,学了只是负担,对一般人而言的话==
安全性
MongoDB是默认不需要密码的,但为了安全性,可以设置
第一步:use admin
第二步:db.createUser({user:..., pwd:..., roles:[role:..., db:...]}) 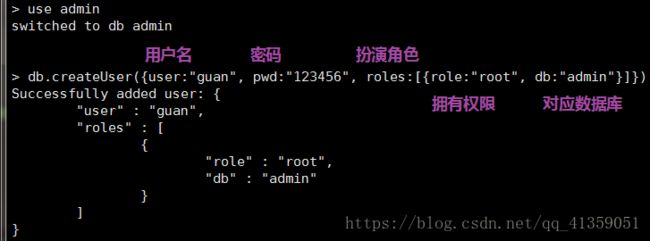
针对role:
root:只在admin数据库中可用,超级账号,超级权限
Read:允许用户读取指定数据库
readWrite:允许用户读写指定数据库
第三步:sudo vim /etc/mongodb.conf 开启认证 
第四步:重启mongodb
此时如果mongo,切换admin,对这个数据库操作将会报错 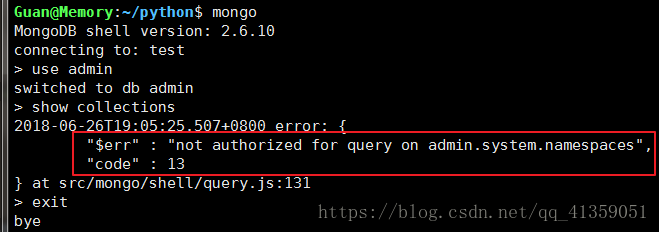
所以需要认证的方式登陆 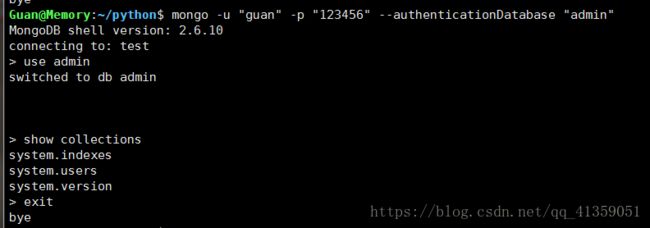
语句:mongo -u "" -p "" --authenticationDatabase "数据库"
修改用户密码:db.updateUser("用户名", {pwd:"..."})
与python交互
- 导入模块:
import pymongo - 连接mongo:
client = pymongo.MongoClient("localhost", 27017) - 指定数据库:
db = clients.数据名 - 指定集合:
collection = db.集合名
内置方法1: insert_one()insert_many() update_one()/update_many() delete_one()/delete_many() find_one()/find() remove_one()/remove_many()
在mongodb中,insert({“name”:”郭靖”})和insert({name:”郭靖”})效果是一样的;但是在与python的交互中,必须前者,后者会报错(其实就是参数得是字典啦)
利用find()函数,返回的是一个迭代器,需要用next或者for遍历 
内置方法2: count() 统计总数 sort() 排序 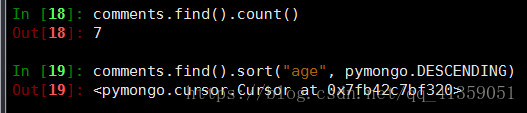
如果是pymon.ASCENDING则为升序;多属性排序:sort([(...), (...)])