Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Ledig C, Theis L, Huszar F, et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network[J]. 2016.
Abstract
尽管采用更快更深的卷积神经网络的单幅图像超分辨率的准确性和速度 有了突破,一个核心问题仍然尚未解决:当在大的放大因子下的超分辨时我们如何恢复细小的纹理细节?基于最优化的超分辨率方法主要由目标函数的选择所影响.最近的工作主要集中在最小化均方重构误差.结果评价有较高的峰值信噪比,但是他们往往缺乏高频细节和感官满意度,无法达到超分辨率的预期逼真度.在本文中,我们提出SRGAN,一个为image super-resolution(SR)的generative adversarial network (GAN).据我们所知,这是第一个能够推导出 4*放大因子 的实感自然图像.为了实现这一目标,我们提出一个感知损失函数,它包含了一个adversarial loss(对抗损失)和一个content loss(),对抗损失用一个判别网络将我们的方案推向自然图像manifold(复印本,流形?),判别网络被训练来区分超分辨率图像和原始图像.此外,由于perceptual similarity感知相似而不是像素空间中的 similarity类似,我们使用一个content loss.我们的深度残差网络可以从严重下采样图像中恢复实感图像纹理.扩展平均意见得分(MOS)测试显示使用SRGAN在视觉质量上有显著的提升.用SRGAN获得的MOS得分比那些用其他的先进方法相比,更接近原始高分辨率图像的得分.
Introduction
由低分辨率(LR)图像预测它的高分辨率(HR)图像这一高难度任务被称为超分辨率super-resolution(SR).AR获得了来自计算机视觉研究界的大量关注并有广泛的应用. 
超分辨率问题的病态求逆过程尤其表现在较高的放大因子上,以至重构的超分辨率图像的纹理细节通常缺失.有监督的超分辨率算法的优化目标通常是最小化恢复的高分辨率图像和实物图像的 均方误差(MSE),最小化MSE时最大化峰值信噪比很方便,这是一种常用的用来评价和比较SR算法的方法.然而,MSE和PSNR捕获感知相关差异的能力是极有限的,因为他们是定义在像素级的图像差异上的.如图2所示,最高的PSNR值并不一定对应感知效果更好的超分辨率结果.

从左到右:(双三次)立方体插值,优化MSE的深度残差网络,深度残差生成对抗网络优化人类感知更为敏感的损失,原始高分辨率图像.对应的PSNR和SSIM(结构相似性)值在括号中显示.
超分辨率和原始图像之间的感知差异意味着恢复图像并不是Ferwerda定义的photo-realistic(实感图像) .
在此工作中,我们提出一个超分辨率生成对抗网络SRGAN,在SRGAN中我们试用一个带skip-connection(跳跃连接?)和diverge from MSE(偏离MSE?)的深度残差网络作为唯一的优化目标..与之前工作不同的是,我们用VGG网络的高层特征图定义了一个新的与分类器结合的perceptual loss(感知损失),它可以促使方案很难区分出高分辨率参考图像.一个超分辨率实感图像样例如图1所示.
1.相关工作
图像超分辨率
最新的关于图像超分辨率的综述文章包括Nasrollahiand Moeslund or Yang et al. .这里我们关注单幅图像超分辨率 single image super-resolution (SISR),对从多幅图像中恢复高分辨率图像方法不作更深的讨论.
处理SISR传统的是基于预测的方法.然而这些滤波方法的速度很快,比如线性,立方体或Lanczos滤波器,他们简化SISR问题并通常生成有极度光滑的纹理的解决方案.着重关注边界保护的方法被提了出来.
更强大的方法旨在建立低分辨率和高分辨率图像信息间的复杂的mapping映射,并通常依赖于训练数据.许多基于样本对的方法依赖于低分辨率training patches训练块,因为对应的高分辨率 counterparts(副本?)未知.
早期的工作是由Freeman等人提出的,SR问题的相关方法起源于压缩知,Glasner等人利用图像内的patch redundancies across scales 来驱动SR.这种自相似的范例也应用在黄等人的工作中,考虑到微小转变和形状的变化,self dictinaries 做了进一步扩展.Gu等人提出一种卷积稀疏编码的方法,通过处理整幅图像而不是overlapping patches提升了一致性.
为了重建逼真的纹理细节同时避免边缘效应,Tai等人结合了基于梯度轮廓优先的边缘传播SR算法和基于学习的细节合成的益处.zhang等人提出一种 multi-scale dictionary(多尺度字典)来捕获在不同尺度上的相似图像块的冗余,yue等人从网上检索带相似内容的有相关性的高分辨率图像,提出一种structure-aware matching criterion(结构感知匹配准则).
领域嵌入法通过在低维流行中寻找相似的低分辨率训练块来上采样一个低分辨率图像块并结合他们相应的高分辨率块来重建.在 Kim and Kwon的文章中强调领域方法趋向过拟合并利用kernel ridge regression制定了一个样本对更通用的map.回归问题可以用高斯过程回归,树,或随机森林解决.在Dai等人文中,学习了大量 patch-specific regressors回归元,测试中选择了最适用的回归元.
最近基于超分辨率算法的卷积神经网络展现出优异的性能.在王等人文章中,将一个稀疏表示优先编码进基于学习迭代收缩和阈值算法(LISTA)的前馈网络结构中.Dong等人用双立方插值来upscale输入图像并训练一个三层首尾相连的深度全卷积网络以获得最新的超分辨率性能.后来表明,使网络直接学习放大过滤器可以促进增强精度和速度两项性能.Kim等人利用深度地柜卷积网络(DRCN)提出一种高性能架构,允许远程像素依赖同时保持少量的模型参数.与我们文章特别相关的是Tohnson 和 Bruna等人的工作,他们依靠一个更接近感知相似性的损失函数来形象地恢复更有说服力的高分辨率图像.
卷积神网络设计
随着Krizhevsky等人工作的成功,许多计算机视觉的最新问题通过特殊设计的CNN结构受到重视.
结果表明,网络结构越深越难训练,但有极大增强网络精确性的潜力,因为他们允许建复杂性很高的映射.为了有效得训练这些深度网络结构,批处理归一化通常用来抵消内部internal covariate shift(协变量变化).更深层次的网络结构也显示出可提高SISR性能.另一个简化了深度卷及神经网络的训练的强大设计选型是最近提出的residual blocks(残差块)和skip-connection的概念.跳跃连接缓解了构建identity mapping(恒等映射)模型的网络结构,恒等映射在本质上是微不足道的,然而,potentially non-trivial to represent with convolutional kernels.
在SISR情况下,学习 upscaling(高级?升级?放大?尺度上升?倍线?) 过滤器有利于精度和速度两方面.This is an improvement over Dong et al. [9] where bicubic interpolation is employed to upscale the LR observation before feeding the image to the CNN.
损失函数
pixel-wise(逐像素?图像?)损失函数(比如MSE)很难处理恢复丢失的高频细节(比如纹理)中固有的不确定性:最小化均方误差促进找出貌似可行的pixel-wise 平均(通常是过度平滑因此感知质量很差).不同感知质量的重建结果与相应的PSNR示例如图2所示.在图3中我们阐释最小化均方误差问题 ,将高纹理细节平均以生成一个平滑的重建结果的多个可能的解决方案. 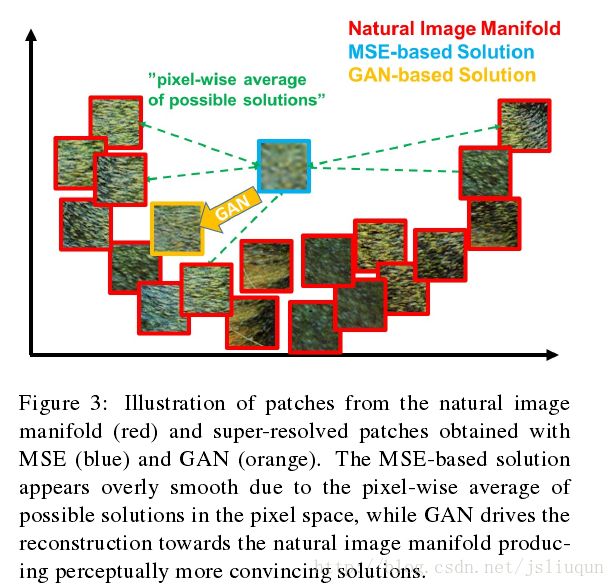
在Mathieu 和 Denton 等人的文献中,他们通过运用生成对抗网络GANs来生成图像.Yu和Porikl增大pixel-wise均方误差和判别器误差来训练网络(有大尺度放大因子(8*)的超分辨率人脸图像).Radford等人也把GANs用作无监督表达学习.用GANs来学习由一个manifold(流形)到另一个流形的映射的想法是由Li和wang提出的,用作style transfer(风格转换).Yeh等人用作图像修复.Bruna等人在特征空间和散射网络中最小化平方误差.
Dosovitskiy and Brox等人联合生成式训练,在神经网络的特征空间用基于欧氏距离计算的损失函数.结果表明提出的损失allows(容许?)视觉出众的图像生成并可以用来解决解码非线性特征表达的病态求逆问题.与这个工作类似的,Johnson等人提出用来自预训练的VGG网络提取的特征代替低级pixel-wise误差测量.作者基于提取的特征图与VGG网络间的欧式距离制定了一个损失函数,在超分辨率和艺术风格转换上都获得了感官上更令人信服的结果.最近Li和Wang也研究了在像素空间或VGG特征空间里进行比较和混合的影响.
贡献
GANs为生成看起来合理的高感知质量的自然图像提供了一个强大的框架.GAN过程促使重建接近有极大可能包含实感图像的搜索空间并由此接近自然图像如图3所示.
本文中,我们将介绍第一个用GANs概念的very deep ResNet结构为实感SISR构成一个感知损失函数.主要贡献如下:
- 对于 image SR 来说,我们取得了新的顶尖效果,提升 4倍的分辨率,衡量标准为:PSNR 和 structure similarity (SSIM)。用16块深度ResNet来优化MSE.
- 我们提出一个基于GAN网络的SRGAN,优化一个新的感知损失perceptual loss.在理我们把基于MSE的content loss替换为一个在VGG网络的特征图上计算出的loss,这样对像素空间中的变化更稳定.
-
我们认为,在来自三个公开基准数据集的图片上测试extensive平均意见得分(MOS),SRGAN的效果最好,估算的4倍实感超分辨率图像.
在第2部分描述网络结构和perceptual loss.第3部分是在公共基准数据集和视觉插图上的量化评价.第4,5部分包含讨论和结语.
2.方法
SISR的目的是估计高分辨率,来自低分辨率输入图像I_lr的超分辨率图像I_sr.这里的I_lr是它高分辨率(对应I_hr)的低分辨率版本.高分辨率图像智能在训练中得到.在训练中,I_lr是对I_hr进行高斯过滤,然后进行下采样得到的(下采样系数r).对一个有C个彩色通道的图像,我们用一个W*H*C大小的实值张量real-valued tensor来描述I_lr,同样的方法描述I_hr和I_sr, rW*rH*C.
我们的最终目标是训练一个生成式函数G,来为给定的LR输入图像估算它相应的HR副本.因此,我们训练一个生成网络作为前馈CNN记为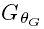 参数化表示为
参数化表示为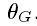 ,这里
,这里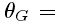
 ,表示层深度网络的权重和偏置,由最优化SR-specific loss function : L_sr 获得.为了训练图像
,表示层深度网络的权重和偏置,由最优化SR-specific loss function : L_sr 获得.为了训练图像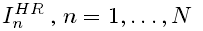
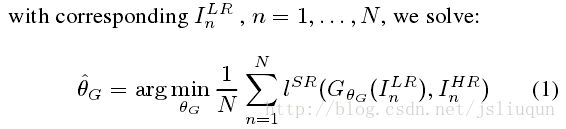
我们将专门设计一个感知损失 L_sr 作为几个损失分量的加权组合,构建恢复超分辨率图像的不同期望特征.独立损失函数在2.2中详细描述.
2.1对抗网络结构
在Goodfellow等人的基础上,我们进一步定义了一个判别网络D, 我们用一种交互的方式优化D和G,以解决对抗性的min-max 问题. 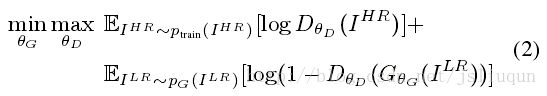
公式的大意是,它允许训练一个生成式模型G,目的是欺骗一个可分辨的判别器D,D被训练来区分是真实图像还是超分辨率图像.用这种方法我们的生成器可以学习生成与真实图像高度相似的结果,因此让D很难区分出来.这促使在子空间中存在最优解,自然图像的复印本.这与最小化pixel-wise 误差测量获得的超分辨率解决方案形成对比,如MSE.
图4所示深度生成器网络G的核心是 B 相同布局的残差块,灵感来源于Johnson等人,我们应用Gross 和Wilber 提出的block layout.我们用两个小的3*3核的卷积层和64张特征图,然后是batch-normalization layers和ReLU 作为激活函数.像Shi等人提出的那样,我们用2个trained sub-pixel 卷积层增加输入图像的分辨率.
为了区分生成的SR样本和真实HR图像,我们训练判别器网络.结构如图4所示.我们用Radford 等人总结的结构指南,并用Leaky (Rectified Linear Units)Re LU 激活,避免整个网络max-pooling最大池化.判别器网络训练来解决方程2中的最大化问题.它包含8个过滤核函数递增的卷积层,按从2到64到512个核函数增长,和VGG网络一样. 每当特征数翻倍的时候,strided convolution 用来降低图像分辨率.作为结果的512个特征图后是2个密集层dense layers和一个final sigmoid 激活函数来得到样本类别的概率. 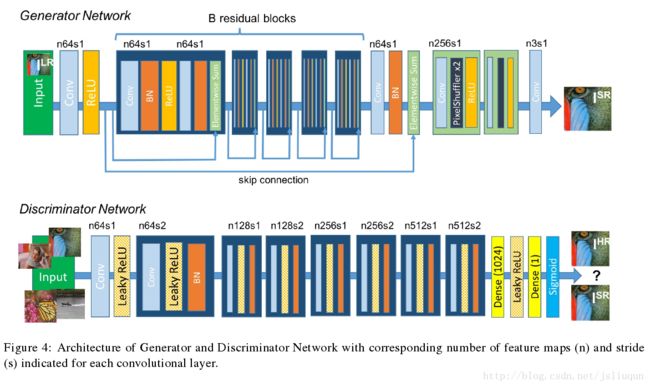
感知损失函数
我们 的感知损失函数 L_sr 的定义对我们的生成网络的性能至关重要.因为通常 L_sr 是基于MSE建模的.我们在Johnson 和 Bruna 等人的工作做了改进并设计了一个损失函数,以感知上的相关特征来评价一个方案.我们制定的感知损失作为content loss (内容损失)的加权和及一个对抗损失分量: 
下面将介绍content loss和 adversarial loss:
content loss

这是图片超分辨率用得最多的优化目标,然而,当获得高的PSNR值的时候,MSE最优化问题的解决方案通常缺乏高频内容,这导致纹理过于光滑而视觉感知不令人满意.如图2
我们用一个接近感知相似性的损失函数,而不是依靠pixel-wise loss.我们基于预训练的19层VGG网络的ReLU激活层来定义VGG loss, 结合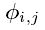 我们预测feature map 特征图由VGG19 network 内的第i个maxpooling layer前 的第j层卷积(after activation)得到
我们预测feature map 特征图由VGG19 network 内的第i个maxpooling layer前 的第j层卷积(after activation)得到
[原文:With we indicate the feature map obtained by the j-th convolution(after activation) before the i-th maxpooling layer within the VGG19 network,which we consider given]
然后我们定义VGG loss 为 重构图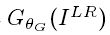 和参考图
和参考图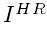 的特征表示间的欧式距离.
的特征表示间的欧式距离. 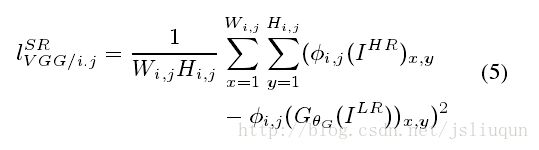
这里Wi,j和Hi,j描述VGG网络中各自特征图的维度.
对抗损失 adversarial loss
我们也将 GAN的生成分量加入到感知损失中去 ,这促使我们的网络支持存在于自然图像的manifold上的解决方案,(通过试图欺骗判别网络).generative loss 生成式损失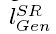 由在全部训练样本上的判别器D的概率定义,如下:
由在全部训练样本上的判别器D的概率定义,如下: 
3.实验
数据及相似性测量
我们在3个被广泛试用的基准数据集 Set5,Set14,BSD100,上进行实验.所有实验在低分辨率和高分辨率图像间的4倍系数上进行.这相当于在图像像素上降低16倍.为了对比公正性,所有的PSNR[dB]和SSIM测量在enter-cropped (中心剪裁)的y 通道上计算,在每条边界上移除4像素宽的条带,图像用 daala package.https://github.com/xiph/daala (commit: 8d03668)
超分辨率图像相关算法包括最近邻,双三次插值,SRCNN和SelfExSR.
Huang等人的在线材料 https://github.com/jbhuang0604/SelfExSR
Kim等人的 DRCN http://cv.snu.ac.kr/research/DRCN/
结果由SRResNet得到,SRGAN变量可以在线获得
:https://twitter.box.com/s/lcue6vlrd01ljkdtdkhmfvk7vtjhetog
Statistical tests were performed as paired two-sided Wilcoxon signed-rank tests and significance determined at p < 0.05.
读者可能会对Git Hub上独立研发的基于GAn的解决方案感兴趣 https://github.com/david-gpu/srez但是.只提供了一组有限的脸部实验结果.
训练细节和参数
所有网络都是在NVIDIA Tesla M40 GPU上训练的,用一组350000张图像的随机样本,图像来自ImageNet 数据集.这些图像与测试图像不同.我们通过下采样HR图像来获得LR图像,用下采样系数r=4的bicubic kernel.对每个mini-batch,剪裁16个不同训练图像的96*96的子图(随机).注意,我们可以把生成器模型应用到任意大小的图像上,因为它是全卷积的.我们用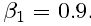 的Adam来最优化,用学习率=0.0001和用10^6次更新迭代来训练SRResNet networks .当训练真实的GAN时,用训练好的基于MSE的SRResNET network 作为生成的的初始化,从而避免出现局部最优.所有的SRGAN变量经过10^5次更新迭代训练(学习率=0.0001),另外进行了学习率=0.00001,迭代次数为10^5的训练.我们交替更新生成器和判别器网络,相当于Goodfellow等人用到的k=1.我们的生成器网络有16个相同的残差块(B=16).在测试时,我们我们turn batch-normalization off 来获得一个确定只依赖于输入的输出. 实现基于 Theano and Lasagne.
的Adam来最优化,用学习率=0.0001和用10^6次更新迭代来训练SRResNet networks .当训练真实的GAN时,用训练好的基于MSE的SRResNET network 作为生成的的初始化,从而避免出现局部最优.所有的SRGAN变量经过10^5次更新迭代训练(学习率=0.0001),另外进行了学习率=0.00001,迭代次数为10^5的训练.我们交替更新生成器和判别器网络,相当于Goodfellow等人用到的k=1.我们的生成器网络有16个相同的残差块(B=16).在测试时,我们我们turn batch-normalization off 来获得一个确定只依赖于输入的输出. 实现基于 Theano and Lasagne.
平均意见得分(MOS)测试
我们进行了MOS测试来量化不同方法重构感知上令人信服的图像的能力.具体来说,我们要求26个评分者对超分辨率图像打分,分数为从1(bad quality)到5(excellent quality)的整数.评分者对Set5 ,Set14 ,BSD100数据集上的每张图像打12个版本的分数(以下12个算法产生的图像):
nearest neighbor (NN),bicubic, SRCNN , SelfExSR , DRCN, ESPCN, SRResNet-MSE, SRRes Net-VGG22(not rated on BSD100), SRGAN-MSE, SRGAN-VGG22, SRGAN-VGG54 and the original HR image.
因此每个评分者评价了1128个例子(19张图片的12个版本+100张图片的9个版本),这些例子以随机的方式呈现.
评分者在来自BSD300训练集的20个图像的NN(评分1)和HR(5)版本上校准。在初步研究中,我们通过将一个方法的图像放入两次以到一个更大的测试集,来评估来自BSD100的10张图像的子集上的26个评分者的校准过程和重测可靠性.我们发现可靠性良好,并且相同图像的评分之间没有显著的偏差.如图5所示: 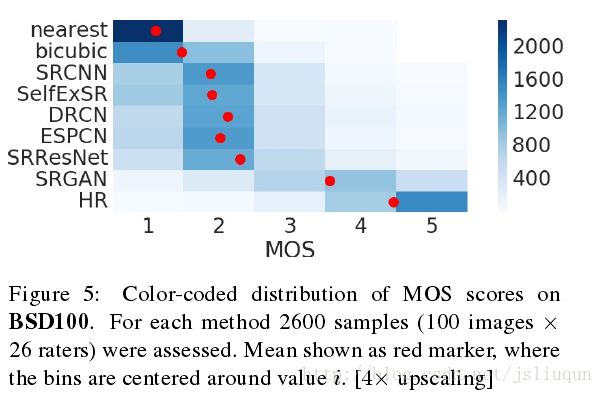
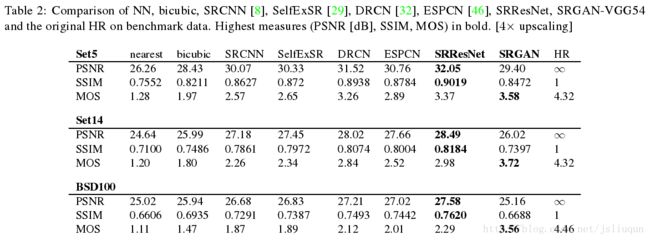
MOS测试的实验结果总结在表1,表2和图5中。
表1:

表2:
Investigation of content loss
我们研究了了不同的content loss choices 在基于GAN网络的感知损失上的影响。具体地说,我们为下面的content loss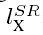 研究
研究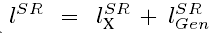 :
:
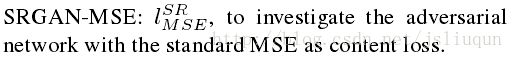 用标准MSE作为content loss来研究对抗网络
用标准MSE作为content loss来研究对抗网络-
 定义在特征图上的loss ,代表着更低级的特征.
定义在特征图上的loss ,代表着更低级的特征. -
 在来自更深层网络层的 更高级特征的 特征图上定义的损失,更可能注重图像的内容.我们在下面将这个网络称为SRGAN。
在来自更深层网络层的 更高级特征的 特征图上定义的损失,更可能注重图像的内容.我们在下面将这个网络称为SRGAN。我们也对没有对抗分量的生成网络的性能进行了评估,两个损失:


把SRResNet-MSE记为SRResNet.结果见表1和图6.
即使加上对抗损失,MSE提供的解决方案的PSNR值最大,然而,视觉感知上更平滑而且比那些对视觉感知更敏感的损失分量所获得的结果更难令人信服.这是由于基于MSE的content loss和adversarial loss之间的竞争,我们进一步把较小的重构块效应(在少数SRGAN-MSE-based重构上观测到)归于那些竞争目标.我们不能确定一个极好的损失函数(SRResNet or SRGAN的)与Set5上的MOS得分有关.然而.在Set4 上,SRGAN-VGG54在MOS得分上显著优于其他SRGAN和SRResNet的变型.我们观察到一个趋势:用更高级的VGG特征图产生更好的纹理细节.(如图6中CGG54和VGG22).在补充材料中提供了通过SRGAN感知改善超过SRResNet的其他示例。网络性能
我们将SRResNet和SRGAN 与NN,双三次插值及4种最先进的方法的性能作比较.定量结果综合在表2中,(在PSNR/SSIM方面)SRResNet在3个基准数据集上效果最拔尖.注意,我们用了一个公共框架来评估(见3.1节),文章呈现的数据因此与原先的文章呈现的那些数据有些微不同.
在BSD100上,我们进一步获得了SRGAN和所有参考方法的MOS评分.SRResNet 和SRGAN的图像超分辨率样本在补充材料中描述.表2显示的结果表明SRGAN以极大优势胜过所有参考方法,成为实感图像超分辨率的最顶尖的技术.如表2,在平均意见得分MOS方面,所有差异在数据集BSD100上极为显著.所有收集到的MOS评分分布如图5所示.
4.讨论和展望
我们用MOS测试证实了SRGAN的优秀感知性能.更进一步表明,标准定量测量,如PSNR和SSIM,就人类视觉系统而言,未能捕获或精准地评估图像质量.这项工作的重点是超像素图像的感知质量而不是计算效率.与Shi等人提出的模型相反,本模型不是对实时视频超分辨率的优化.然而,网络结构的初步实验表明,在质量性能稍微降低的情况下,浅层网络是个非常有效的替代品.与Dong等人相反,我们发现乌拉圭人结构越深越有利.我们推测,ResNet设计在深度网络的性能上有.重大影响.我们发现更深的网络(B>16)可以更进一步增强SRResNet的性能.然而,代价是训练和测试时间更长(见补充材料).我们进一步发现SRGAN更深层的网络变型越来越难训练,由于出现高频块效应.
在针对超分辨率问题的实感解决方案是,content loss 的选择显得尤为重要,如图6所示.工作中,我们发现 产生了感官上最令人信服的结果,我们归功于更深的网络层表达远离像素空间的更高抽象的特征的潜能.我们推测,这些更深的网络层的特征图只专注于内容,而让对抗损失集中在纹理细节上.这是没有对抗损失的超分辨率图像和实感图像的主要差别.我们还注意到,理想的损失函数取决于实际运用.比如,出现精细细节(幻觉)的方法可能感知上令人信服,但不适用于医疗应用或监控.content loss的发展.content loss function(描述图像空间内容,但在像素空间中对变化更不敏感) 的发展将进一步提升实感图像超分辨率结果.
产生了感官上最令人信服的结果,我们归功于更深的网络层表达远离像素空间的更高抽象的特征的潜能.我们推测,这些更深的网络层的特征图只专注于内容,而让对抗损失集中在纹理细节上.这是没有对抗损失的超分辨率图像和实感图像的主要差别.我们还注意到,理想的损失函数取决于实际运用.比如,出现精细细节(幻觉)的方法可能感知上令人信服,但不适用于医疗应用或监控.content loss的发展.content loss function(描述图像空间内容,但在像素空间中对变化更不敏感) 的发展将进一步提升实感图像超分辨率结果.
5.结论
我们描绘了一个深度残差网络SRResNet,用PSNR测量时在公共基准数据集上取得了顶尖的效果.我们强调了这种专注于PSNR值的 图像超分辨率的一些局限性并介绍了SRGAN.SRGAN通过训练一个GAN给content loss funtion 增加了一个adversarial loss.用扩展的MOS测试,我们证实对于大的放大因子(4*)SRGAN重构比目前顶尖的参考方法获得的重构更逼真