Python 学习笔记 函数与Lambda表达式 DAY6
函数与Lambda表达式
一. 函数
1.函数的定义
-
函数以
def关键词开头,后接函数名和圆括号()。 -
函数执行的代码以冒号起始,并且缩进。
-
return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回
None。 -
函数也是一个对象
-
对象是内存中专门用来存储数据的一块区域
-
函数可以用来保存一些可执行的代码,并且可以在需要时,对这些语句进行多次的调用
-
创建函数:
def 函数名([形参1,形参2,…形参n]) :
代码块- 函数名必须要符号标识符的规范
(可以包含字母、数字、下划线、但是不能以数字开头)
- 函数名必须要符号标识符的规范
-
函数中保存的代码不会立即执行,需要调用函数代码才会执行
-
调用函数:
函数对象() -
定义函数一般都是要实现某种功能的
# 比如有如下三行代码,这三行代码是一个完整的功能
# print('Hello')
# print('你好')
# print('再见')
# 定义一个函数
def fn() :
print('这是我的第一个函数!')
print('hello')
print('今天天气真不错!')
# 打印fn
print(fn) # 2.函数文档
def MyFirstFunction(name):
"函数定义过程中name是形参"
# 因为Ta只是一个形式,表示占据一个参数位置
print('传递进来的{0}叫做实参,因为Ta是具体的参数值!'.format(name))
MyFirstFunction('老马的程序人生')
# 传递进来的老马的程序人生叫做实参,因为Ta是具体的参数值!
print(MyFirstFunction.__doc__)
# 函数定义过程中name是形参
help(MyFirstFunction)
# Help on function MyFirstFunction in module __main__:
# MyFirstFunction(name)
# 函数定义过程中name是形参3.函数参数
Python 的函数具有非常灵活多样的参数形态,既可以实现简单的调用,又可以传入非常复杂的参数。从简到繁的参数形态如下:
-
位置参数 (positional argument)
-
默认参数 (default argument)
-
可变参数 (variable argument)
-
关键字参数 (keyword argument)
-
命名关键字参数 (name keyword argument)
-
参数组合
-
在定义函数时,可以在函数名后的()中定义数量不等的形参,
多个形参之间使用,隔开 -
形参(形式参数),定义形参就相当于在函数内部声明了变量,但是并不赋值
-
实参(实际参数)
- 如果函数定义时,指定了形参,那么在调用函数时也必须传递实参,
实参将会赋值给对应的形参,简单来说,有几个形参就得传几个实参
- 如果函数定义时,指定了形参,那么在调用函数时也必须传递实参,
1. 位置参数
def functionname(arg1):
"函数_文档字符串"
function_suite
return [expression]arg1- 位置参数 ,这些参数在调用函数 (call function) 时位置要固定。
2. 默认参数
def functionname(arg1, arg2=v):
"函数_文档字符串"
function_suite
return [expression]arg2 = v- 默认参数 = 默认值,调用函数时,默认参数的值如果没有传入,则被认为是默认值。- 默认参数一定要放在位置参数 后面,不然程序会报错。
def printinfo(name, age=8):
print('Name:{0},Age:{1}'.format(name, age))
printinfo('小马') # Name:小马,Age:8
printinfo('小马', 10) # Name:小马,Age:10- Python 允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
def printinfo(name, age):
print('Name:{0},Age:{1}'.format(name, age))
printinfo(age=8, name='小马') # Name:小马,Age:83. 可变参数
顾名思义,可变参数就是传入的参数个数是可变的,可以是 0, 1, 2 到任意个,是不定长的参数。
def functionname(arg1, arg2=v, *args):
"函数_文档字符串"
function_suite
return [expression]*args- 可变参数,可以是从零个到任意个,自动组装成元组。- 加了星号(*)的变量名会存放所有未命名的变量参数。
def printinfo(arg1, *args):
print(arg1)
for var in args:
print(var)
printinfo(10) # 10
printinfo(70, 60, 50)
# 70
# 60
# 504. 关键字参数
def functionname(arg1, arg2=v, *args, **kw):
"函数_文档字符串"
function_suite
return [expression]**kw- 关键字参数,可以是从零个到任意个,自动组装成字典。
def printinfo(arg1, *args, **kwargs):
print(arg1)
print(args)
print(kwargs)
printinfo(70, 60, 50)
# 70
# (60, 50)
# {}
printinfo(70, 60, 50, a=1, b=2)
# 70
# (60, 50)
# {'a': 1, 'b': 2}「可变参数」和「关键字参数」的同异总结如下:
- 可变参数允许传入零个到任意个参数,它们在函数调用时自动组装为一个元组 (tuple)。
- 关键字参数允许传入零个到任意个参数,它们在函数内部自动组装为一个字典 (dict)。
5. 命名关键字参数
def functionname(arg1, arg2=v, *args, *, nkw, **kw):
"函数_文档字符串"
function_suite
return [expression]*, nkw- 命名关键字参数,用户想要输入的关键字参数,定义方式是在nkw 前面加个分隔符 *。- 如果要限制关键字参数的名字,就可以用「命名关键字参数」
- 使用命名关键字参数时,要特别注意不能缺少参数名。
def printinfo(arg1, *, nkw, **kwargs):
print(arg1)
print(nkw)
print(kwargs)
printinfo(70, nkw=10, a=1, b=2)
# 70
# 10
# {'a': 1, 'b': 2}
printinfo(70, 10, a=1, b=2)
# TypeError: printinfo() takes 1 positional argument but 2 were given- 没有写参数名
nkw,因此 10 被当成「位置参数」,而原函数只有 1 个位置函数,现在调用了 2 个,因此程序会报错。
# 定义一个函数
# 定义形参时,可以为形参指定默认值
# 指定了默认值以后,如果用户传递了参数则默认值没有任何作用
# 如果用户没有传递,则默认值就会生效
def fn(a = 5 , b = 10 , c = 20):
print('a =',a)
print('b =',b)
print('c =',c)
# fn(1 , 2 , 3)
# fn(1 , 2)
# fn()
# 实参的传递方式
# 位置参数
# 位置参数就是将对应位置的实参复制给对应位置的形参
# 第一个实参赋值给第一个形参,第二个实参赋值给第二个形参 。。。
# fn(1 , 2 , 3)
# 关键字参数
# 关键字参数,可以不按照形参定义的顺序去传递,而直接根据参数名去传递参数
# fn(b=1 , c=2 , a=3)
# print('hello' , end='')
# 位置参数和关键字参数可以混合使用
# 混合使用关键字和位置参数时,必须将位置参数写到前面
# fn(1,c=30)
def fn2(a):
print('a =',a)
# 函数在调用时,解析器不会检查实参的类型
# 实参可以传递任意类型的对象
b = 123
b = True
b = 'hello'
b = None
b = [1,2,3]
# fn2(b)
fn2(fn)
def fn3(a , b):
print(a+b)
# fn3(123,"456")
def fn4(a):
# 在函数中对形参进行重新赋值,不会影响其他的变量
# a = 20
# a是一个列表,尝试修改列表中的元素
# 如果形参执行的是一个对象,当我们通过形参去修改对象时
# 会影响到所有指向该对象的变量
a[0] = 30
print('a =',a,id(a))
c = 10
c = [1,2,3]
fn4(c)
fn4(c.copy())
fn4(c[:])
print('c =',c,id(c))6. 参数组合
在 Python 中定义函数,可以用位置参数、默认参数、可变参数、命名关键字参数和关键字参数,这 5 种参数中的 4 个都可以一起使用,但是注意,参数定义的顺序必须是:
- 位置参数、默认参数、可变参数和关键字参数。
- 位置参数、默认参数、命名关键字参数和关键字参数。
要注意定义可变参数和关键字参数的语法:
*args是可变参数,args接收的是一个tuple**kw是关键字参数,kw接收的是一个dict
命名关键字参数是为了限制调用者可以传入的参数名,同时可以提供默认值。定义命名关键字参数不要忘了写分隔符 *,否则定义的是位置参数。
警告:虽然可以组合多达 5 种参数,但不要同时使用太多的组合,否则函数很难懂。
# 定义一个函数,可以求任意个数字的和
def sum(*nums):
# 定义一个变量,来保存结果
result = 0
# 遍历元组,并将元组中的数进行累加
for n in nums :
result += n
print(result)
sum(123,456,789,10,20,30,40)
# 在定义函数时,可以在形参前边加上一个*,这样这个形参将会获取到所有的实参
# 它将会将所有的实参保存到一个元组中
a,b,*c = (1,2,3,4,5,6)
# *a会接受所有的位置实参,并且会将这些实参统一保存到一个元组中(装包)
def fn(*a):
print("a =",a,type(a))
fn(1,2,3,4,5)
# 带星号的形参只能有一个
# 带星号的参数,可以和其他参数配合使用
# 第一个参数给a,第二个参数给b,剩下的都保存到c的元组中
def fn2(a,b,*c):
print('a =',a)
print('b =',b)
print('c =',c)
# 可变参数不是必须写在最后,但是注意,带*的参数后的所有参数,必须以关键字参数的形式传递
# 第一个参数给a,剩下的位置参数给b的元组,c必须使用关键字参数
def fn2(a,*b,c):
print('a =',a)
print('b =',b)
print('c =',c)
# 所有的位置参数都给a,b和c必须使用关键字参数
def fn2(*a,b,c):
print('a =',a)
print('b =',b)
print('c =',c)
# 如果在形参的开头直接写一个*,则要求我们的所有的参数必须以关键字参数的形式传递
def fn2(*,a,b,c):
print('a =',a)
print('b =',b)
print('c =',c)
fn2(a=3,b=4,c=5)
# *形参只能接收位置参数,而不能接收关键字参数
def fn3(*a) :
print('a =',a)
# **形参可以接收其他的关键字参数,它会将这些参数统一保存到一个字典中
# 字典的key就是参数的名字,字典的value就是参数的值
# **形参只能有一个,并且必须写在所有参数的最后
def fn3(b,c,**a) :
print('a =',a,type(a))
print('b =',b)
print('c =',c)
fn3(b=1,d=2,c=3,e=10,f=20)
# 参数的解包(拆包)
def fn4(a,b,c):
print('a =',a)
print('b =',b)
print('c =',c)
# 创建一个元组
t = (10,20,30)
# 传递实参时,也可以在序列类型的参数前添加星号,这样他会自动将序列中的元素依次作为参数传递
# 这里要求序列中元素的个数必须和形参的个数的一致
fn4(*t)
# 创建一个字典
d = {'a':100,'b':200,'c':300}
# 通过 **来对一个字典进行解包操作
fn4(**d)4.函数的返回值
# 返回值,返回值就是函数执行以后返回的结果
# 可以通过 return 来指定函数的返回值
# 可以之间使用函数的返回值,也可以通过一个变量来接收函数的返回值
def sum(*nums):
# 定义一个变量,来保存结果
result = 0
# 遍历元组,并将元组中的数进行累加
for n in nums:
result += n
print(result)
sum(123,456,789) # 1368
# return 后边跟什么值,函数就会返回什么值
# return 后边可以跟任意的对象,返回值甚至可以是一个函数
def fn():
# return 'Hello'
# return [1,2,3]
# return {'k':'v'}
def fn2():
print('hello')
return fn2 # 返回值也可以是一个函数
r = fn() # 这个函数的执行结果就是它的返回值
r() # hello
print(fn()) # .fn2 at 0x0000018BA1EAC4C8>
print(r) # .fn2 at 0x0000018BA1EAC4C8>
# 如果仅仅写一个return 或者 不写return,则相当于return None
def fn2():
a = 10
return
# 在函数中,return后的代码都不会执行,return 一旦执行函数自动结束
def fn3():
print('hello')
return
print('abc')
r = fn3()
print(r) # hello,None
def fn4():
for i in range(5):
if i == 3:
# break 用来退出当前循环
# continue 用来跳过当次循环
return # return 用来结束函数
print(i)
print('循环执行完毕!')
fn4() # 0,1,2
def sum(*nums):
# 定义一个变量,来保存结果
result = 0
# 遍历元组,并将元组中的数进行累加
for n in nums:
result += n
return result
r = sum(123, 456, 789)
print(r + 778) # 2146
def fn5():
return 10
# fn5 和 fn5()的区别
print(fn5) # fn5是函数对象,打印fn5实际是在打印函数对象 # 5.变量作用域
- Python 中,程序的变量并不是在哪个位置都可以访问的,访问权限决定于这个变量是在哪里赋值的。
- 定义在函数内部的变量拥有局部作用域,该变量称为局部变量。
- 定义在函数外部的变量拥有全局作用域,该变量称为全局变量。
- 局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。
在Python中一共有两种作用域
全局作用域
- 全局作用域在程序执行时创建,在程序执行结束时销毁
- 所有函数以外的区域都是全局作用域
- 在全局作用域中定义的变量,都属于全局变量,全局变量可以在程序的任意位置被访问
函数作用域
- 函数作用域在函数调用时创建,在调用结束时销毁
- 函数每调用一次就会产生一个新的函数作用域
- 在函数作用域中定义的变量,都是局部变量,它只能在函数内部被访问
变量的查找
- 当我们使用变量时,会优先在当前作用域中寻找该变量,如果有则使用,
如果没有则继续去上一级作用域中寻找,如果有则使用,
如果依然没有则继续去上一级作用域中寻找,以此类推
直到找到全局作用域,依然没有找到,则会抛出异常
NameError: name ‘a’ is not defined
# 作用域(scope)
# 作用域指的是变量生效的区域
b = 20 # 全局变量
def fn():
a = 10 # a定义在了函数内部,所以他的作用域就是函数内部,函数外部无法访问
print('函数内部:', 'a =', a)
print('函数内部:', 'b =', b)
fn()
print('函数外部:','a =',a) # NameError: name 'a' is not defined
print('函数外部:','b =',b)
# 在Python中一共有两种作用域
# 全局作用域
# - 全局作用域在程序执行时创建,在程序执行结束时销毁
# - 所有函数以外的区域都是全局作用域
# - 在全局作用域中定义的变量,都属于全局变量,全局变量可以在程序的任意位置被访问
#
# 函数作用域
# - 函数作用域在函数调用时创建,在调用结束时销毁
# - 函数每调用一次就会产生一个新的函数作用域
# - 在函数作用域中定义的变量,都是局部变量,它只能在函数内部被访问
#
# 变量的查找
# - 当我们使用变量时,会优先在当前作用域中寻找该变量,如果有则使用,
# 如果没有则继续去上一级作用域中寻找,如果有则使用,
# 如果依然没有则继续去上一级作用域中寻找,以此类推
# 直到找到全局作用域,依然没有找到,则会抛出异常
# NameError: name 'a' is not defined
def fn2():
def fn3():
print('fn3中:', 'a =', a)
fn3() # NameError: name 'a' is not defined
fn2()
a = 20
def fn3():
# a = 10 # 在函数中为变量赋值时,默认都是为局部变量赋值
# 如果希望在函数内部修改全局变量,则需要使用global关键字,来声明变量
global a # 声明在函数内部的使用a是全局变量,此时再去修改a时,就是在修改全局的a
a = 10 # 修改全局变量
print('函数内部:', 'a =', a)
fn3()
print('函数外部:','a =',a)
# 命名空间(namespace)
# 命名空间指的是变量存储的位置,每一个变量都需要存储到指定的命名空间当中
# 每一个作用域都会有一个它对应的命名空间
# 全局命名空间,用来保存全局变量。函数命名空间用来保存函数中的变量
# 命名空间实际上就是一个字典,是一个专门用来存储变量的字典
# locals()用来获取当前作用域的命名空间
# 如果在全局作用域中调用locals()则获取全局命名空间,如果在函数作用域中调用locals()则获取函数命名空间
# 返回的是一个字典
scope = locals() # 当前命名空间
print(type(scope))
print(a)
print(scope['a'])
# 向scope中添加一个key-value
scope['c'] = 1000 # 向字典中添加key-value就相当于在全局中创建了一个变量(一般不建议这么做)
print(c)
def fn4():
a = 10
scope = locals() # 在函数内部调用locals()会获取到函数的命名空间
scope['b'] = 20 # 可以通过scope来操作函数的命名空间,但是也是不建议这么做
# globals() 函数可以用来在任意位置获取全局命名空间
global_scope = globals()
print(global_scope['a'])
global_scope['a'] = 30
print(scope)
fn4()
'''
函数内部: a = 10
函数内部: b = 20
函数外部: b = 20
函数内部: a = 10
函数外部: a = 10
10
10
1000
10
{'a': 10, 'b': 20}
''' 1.闭包
- 是函数式编程的一个重要的语法结构,是一种特殊的内嵌函数。
- 如果在一个内部函数里对外层非全局作用域的变量进行引用,那么内部函数就被认为是闭包。
- 通过闭包可以访问外层非全局作用域的变量,这个作用域称为 闭包作用域。
- 闭包的返回值通常是函数。
# 将函数作为返回值返回,也是一种高阶函数
# 这种高阶函数我们也称为叫做闭包,通过闭包可以创建一些只有当前函数能访问的变量
# 可以将一些私有的数据藏到的闭包中
def fn():
a = 10
# 函数内部再定义一个函数
def inner():
print('我是fn2' , a)
# 将内部函数 inner作为返回值返回
return inner
# r是一个函数,是调用fn()后返回的函数
# 这个函数实在fn()内部定义,并不是全局函数
# 所以这个函数总是能访问到fn()函数内的变量
r = fn()
r()
# 求多个数的平均值
nums = [50,30,20,10,77]
# sum()用来求一个列表中所有元素的和
print(sum(nums)/len(nums))
# 形成闭包的要件
# ① 函数嵌套
# ② 将内部函数作为返回值返回
# ③ 内部函数必须要使用到外部函数的变量
def make_averager():
# 创建一个列表,用来保存数值
nums = []
# 创建一个函数,用来计算平均值
def averager(n) :
# 将n添加到列表中
nums.append(n)
# 求平均值
return sum(nums)/len(nums)
return averager
averager = make_averager()
print(averager(10))
print(averager(20))
print(averager(30))
print(averager(40))
'''
我是fn2 10
37.4
10.0
15.0
20.0
25.0
'''- 如果要修改闭包作用域中的变量则需要
nonlocal关键字
def outer():
num = 10
def inner():
nonlocal num # nonlocal关键字声明
num = 100
print(num)
inner()
print(num)
outer()
# 100
# 1002.递归
- 如果一个函数在内部调用自身本身,这个函数就是递归函数。
# 尝试求10的阶乘(10!)
# 1! = 1
# 2! = 1*2 = 2
# 3! = 1*2*3 = 6
# 4! = 1*2*3*4 = 24
# print(1*2*3*4*5*6*7*8*9*10)
# 创建一个变量保存结果
# n = 10
# for i in range(1,10):
# n *= i
# print(n)
# 创建一个函数,可以用来求任意数的阶乘
def factorial(n):
'''
该函数用来求任意数的阶乘
参数:
n 要求阶乘的数字
'''
# 创建一个变量,来保存结果
result = n
for i in range(1, n):
result *= i
return result
# 求10的阶乘
print(factorial(20)) # 2432902008176640000
# 递归式的函数
# 从前有座山,山里有座庙,庙里有个老和尚讲故事,讲的什么故事呢?
# 从前有座山,山里有座庙,庙里有个老和尚讲故事,讲的什么故事呢?....
# 递归简单理解就是自己去引用自己!
# 递归式函数,在函数中自己调用自己!
# 无穷递归,如果这个函数被调用,程序的内存会溢出,效果类似于死循环
def fn():
fn() # RecursionError: maximum recursion depth exceeded
fn()
# 递归是解决问题的一种方式,它和循环很像
# 它的整体思想是,将一个大问题分解为一个个的小问题,直到问题无法分解时,再去解决问题
# 递归式函数的两个要件
# 1.基线条件
# - 问题可以被分解为的最小问题,当满足基线条件时,递归就不在执行了
# 2.递归条件
# - 将问题继续分解的条件
# 递归和循环类似,基本是可以互相代替的,
# 循环编写起来比较容易,阅读起来稍难
# 递归编写起来难,但是方便阅读
# 10! = 10 * 9!
# 9! = 9 * 8!
# 8! = 8 * 7!
# ...
# 1! = 1
def factorial(n):
'''
该函数用来求任意数的阶乘
参数:
n 要求阶乘的数字
'''
# 基线条件 判断n是否为1,如果为1则此时不能再继续递归
if n == 1:
# 1的阶乘就是1,直接返回1
return 1
# 递归条件
return n * factorial(n - 1)
print(factorial(10)) # 3628800- 设置递归的层数,Python默认递归层数为 100
import sys
sys.setrecursionlimit(1000)二. Lambda 表达式
1.匿名函数的定义
在 Python 里有两类函数:
- 第一类:用
def关键词定义的正规函数 - 第二类:用
lambda关键词定义的匿名函数
python 使用 lambda 关键词来创建匿名函数,而非def关键词,它没有函数名,其语法结构如下:
lambda argument_list: expression
lambda- 定义匿名函数的关键词。argument_list- 函数参数,它们可以是位置参数、默认参数、关键字参数,和正规函数里的参数类型一样。:- 冒号,在函数参数和表达式中间要加个冒号。expression- 只是一个表达式,输入函数参数,输出一些值。
注意:
expression中没有 return 语句,因为 lambda 不需要它来返回,表达式本身结果就是返回值。- 匿名函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
def sqr(x):
return x ** 2
print(sqr)
# at 0x000000BABB6AC1E0>
y = [lbd_sqr(x) for x in range(10)]
print(y)
# [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
sumary = lambda arg1, arg2: arg1 + arg2
print(sumary(10, 20)) # 30
func = lambda *args: sum(args)
print(func(1, 2, 3, 4, 5)) # 152.匿名函数的应用
函数式编程 是指代码中每一块都是不可变的,都由纯函数的形式组成。这里的纯函数,是指函数本身相互独立、互不影响,对于相同的输入,总会有相同的输出,没有任何副作用。
- 非函数式编程
def f(x):
for i in range(0, len(x)):
x[i] += 10
return x
x = [1, 2, 3]
f(x)
print(x)
# [11, 12, 13]- 函数式编程
def f(x):
y = []
for item in x:
y.append(item + 10)
return y
x = [1, 2, 3]
f(x)
print(x)
# [1, 2, 3]匿名函数 常常应用于函数式编程的高阶函数 (high-order function)中,主要有两种形式:
- 参数是函数 (filter, map)
- 返回值是函数 (closure)
如,在 filter和map函数中的应用:
filter(function, iterable)过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用list()来转换。
odd = lambda x: x % 2 == 1
templist = filter(odd, [1, 2, 3, 4, 5, 6, 7, 8, 9])
print(list(templist)) # [1, 3, 5, 7, 9]map(function, *iterables)根据提供的函数对指定序列做映射。
m1 = map(lambda x: x ** 2, [1, 2, 3, 4, 5])
print(list(m1))
# [1, 4, 9, 16, 25]
m2 = map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])
print(list(m2))
# [3, 7, 11, 15, 19]- 除了 Python 这些内置函数,我们也可以自己定义高阶函数。
def apply_to_list(fun, some_list):
return fun(some_list)
lst = [1, 2, 3, 4, 5]
print(apply_to_list(sum, lst))
# 15
print(apply_to_list(len, lst))
# 5
print(apply_to_list(lambda x: sum(x) / len(x), lst))
# 3.0三.练习题:
-
怎么给函数编写⽂档?
答:
def MyFirstFunction(name): "函数定义过程中name是形参" # 因为Ta只是一个形式,表示占据一个参数位置 print('传递进来的{0}叫做实参,因为Ta是具体的参数值!'.format(name)) MyFirstFunction('老马的程序人生') # 传递进来的老马的程序人生叫做实参,因为Ta是具体的参数值! print(MyFirstFunction.__doc__) -
怎么给函数参数和返回值注解?
答:
def func(x: int, y: int) -> int: '''return type int, return x add y ''' return x+y print(func(1,3)) # 4 -
闭包中,怎么对数字、字符串、元组等不可变元素更新。
答: 要修改闭包作用域中的变量则需要
nonlocal关键字 -
分别根据每一行的首元素和尾元素大小对二维列表 a = [[6, 5], [3, 7], [2, 8]] 排序。(利用lambda表达式)
答:
a = [[6, 5], [3, 7], [2, 8]] a = sorted(a,key=lambda i:i[0]) print(a) a = sorted(a,key=lambda i:i[-1]) print(a) ''' [[2, 8], [3, 7], [6, 5]] [[6, 5], [3, 7], [2, 8]] ''' -
利用python解决汉诺塔问题?
有a、b、c三根柱子,在a柱子上从下往上按照大小顺序摞着64片圆盘,把圆盘从下面开始按大小顺序重新摆放在c柱子上,尝试用函数来模拟解决的过程。(提示:将问题简化为已经成功地将a柱上面的63个盘子移到了b柱)
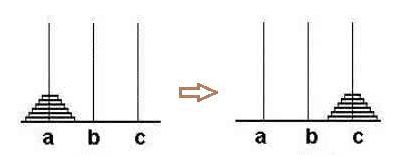
答:
def move(n, a, b, c):
if n == 1:
print(a, "->", c)
else:
print(a, "->", b)
move(n - 1, a, b, c)
print(b, "->", c)
move(64, "a", "b", "c")