计算机视觉ch8 图像内容分类——基于KNN的手势识别
文章目录
- KNN算法原理
- 用KNN实现简单分类
- 图像稠密 sift特征的实现
- Python实现手势识别
KNN算法原理
KNN即K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻居来代表。KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。在分类中选择K个最相似数据中出现次数最多的分类作为新数据的分类,即“投票法”。它的核心思想可以用一句话来概括:物以类聚,人以群分。KNN算法主要涉及3个因素:样本集、距离或相似的衡量、K的大小。
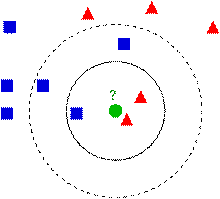
如上图,求绿色圆圈的所属类别,正方形和三角形都是样本数据。假设k=3,则绿色圆圈的邻居有两个三角形和一个正方形,按照投票法,绿色圆圈所属类别应该是红色三角形。若k=5,则绿色圆圈的邻居有两个三角形和三个正方形,则绿色圆圈所属类别是蓝色正方形
基本步骤
- 计算测试对象和训练集每个对象之间的距离
- 按递增顺序对距离进行排序
- 把距离最近的K个点作为测试对象的最近邻
- 找到这些邻居中的绝大多数类
- 将绝大多数类返回作为我们对测试对象归属类的预测
用KNN实现简单分类
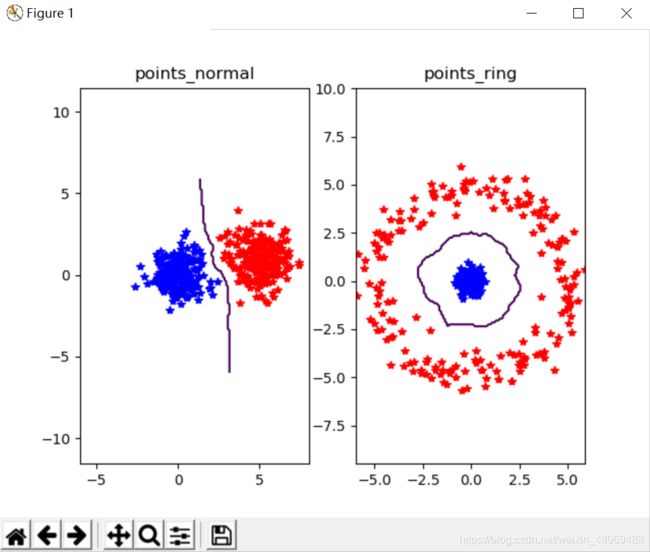
通过随机生成的方式,创建两个不同的二维点集class1和class2,每个点集有两类,分别是正态分布和绕环状分布,正态分布的范围主要通过代码中参数的调节实现,该参数越大,数据点范围越大,就更分散。
# -*- coding: utf-8 -*-
# 生成点的过程
from numpy.random import randn
import pickle
from pylab import *
# create sample data of 2D points
# 打印两百个点
n = 200
# two normal distributions
# 两百个二维的点并通过*0.6限制他们的范围
class_1 = 0.8 * randn(n, 2)
class_2 = 1.0 * randn(n, 2) + array([5, 1])
# 给他们分标签
labels = hstack((ones(n), -ones(n)))
# save with Pickle
# with open('points_normal.pkl', 'w') as f:
# 把他们存进
with open('points_normal_test.pkl', 'wb') as f:
pickle.dump(class_1, f)
pickle.dump(class_2, f)
pickle.dump(labels, f)
# normal distribution and ring around it
print("save OK!")
# 环状的数据
class_1 = 0.3 * randn(n, 2)
r = 0.5 * randn(n, 1) + 5
angle = 2 * pi * randn(n, 1)
class_2 = hstack((r * cos(angle), r * sin(angle)))
labels = hstack((ones(n), -ones(n)))
# save with Pickle
# with open('points_ring.pkl', 'w') as f:
with open('points_ring_test.pkl', 'wb') as f:
pickle.dump(class_1, f)
pickle.dump(class_2, f)
pickle.dump(labels, f)
print("save OK!")
用KNN分类器对生成的点击分类
# -*- coding: utf-8 -*-
import pickle
from pylab import *
from PCV.classifiers import knn
from PCV.tools import imtools
pklist = ['points_normal.pkl', 'points_ring.pkl']
figure()
# load 2D points using Pickle
# 枚举前面的两个元素
for i, pklfile in enumerate(pklist):
with open(pklfile, 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
# load test data using Pickle
with open(pklfile[:-4] + '_test.pkl', 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
# knn分类器
model = knn.KnnClassifier(labels, vstack((class_1, class_2)))
# test on the first point
print(model.classify(class_1[0]))
# define function for plotting
def classify(x, y, model=model):
return array([model.classify([xx, yy]) for (xx, yy) in zip(x, y)])
# lot the classification boundary
subplot(1, 2, i + 1)
# 画分界线
imtools.plot_2D_boundary([-6, 6, -6, 6], [class_1, class_2], classify, [1, -1])
titlename = pklfile[:-4]
title(titlename)
show()
图像稠密 sift特征的实现
# -*- coding: utf-8 -*-
from PCV.localdescriptors import sift, dsift
from pylab import *
from PIL import Image
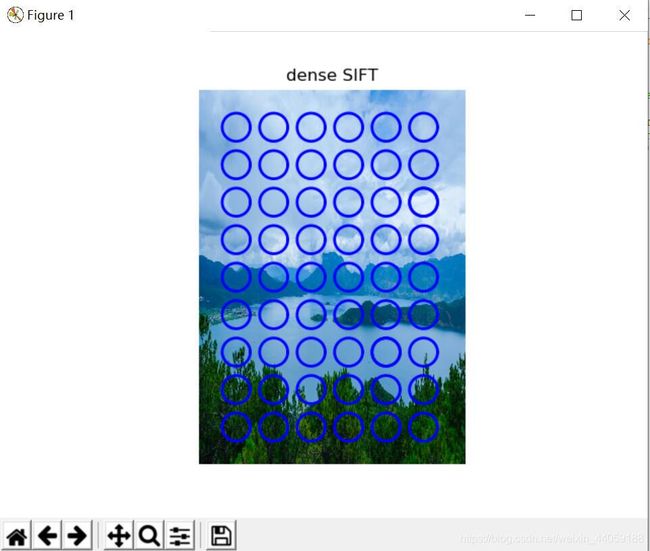
dsift.process_image_dsift('E:\Program Files (x86)\PyCharm Community Edition 2019.1.2\code\pcv-book-code-master\ch08\1.jpg', '1.dsift', 90, 40, True)
# 读取dsif文件
l, d = sift.read_features_from_file('wenwen.dsift')
im = array(Image.open('gesture/wenwen.jpg'))
sift.plot_features(im, l, True)
title('dense SIFT')
show()

上述代码dsift.process_image_dsift(‘E:\Program Files (x86)\PyCharm Community Edition 2019.1.2\code\pcv-book-code-master\ch08\1.jpg’, ‘1.dsift’, 90, 40, True)中90表示圈的大小,40表示步长,当保持圈的大小不变,将步长变大成80时的结果图如下:
Python实现手势识别
# -*- coding: utf-8 -*-
import os
from PCV.localdescriptors import sift, dsift
from pylab import *
from PIL import Image
imlist = ['E:/Program Files (x86)/PyCharm Community Edition 2019.1.2/code/pcv-book-code-master/ch08/C-uniform02.jpg',
'E:/Program Files (x86)/PyCharm Community Edition 2019.1.2/code/pcv-book-code-master/ch08/B-uniform02.jpg',
'E:/Program Files (x86)/PyCharm Community Edition 2019.1.2/code/pcv-book-code-master/ch08/A-uniform02.jpg',
'E:/Program Files (x86)/PyCharm Community Edition 2019.1.2/code/pcv-book-code-master/ch08/fIVE-uniform02.jpg',
'E:/Program Files (x86)/PyCharm Community Edition 2019.1.2/code/pcv-book-code-master/ch08/pOINT-uniform02.jpg',
'E:/Program Files (x86)/PyCharm Community Edition 2019.1.2/code/pcv-book-code-master/ch08/v-uniform02.jpg']
figure()
for i, im in enumerate(imlist):
print(im)
dsift.process_image_dsift(im, im[:-3] + 'dsift', 40, 20, True)
l, d = sift.read_features_from_file(im[:-3] + 'dsift')
dirpath, filename = os.path.split(im)
im = array(Image.open(im))
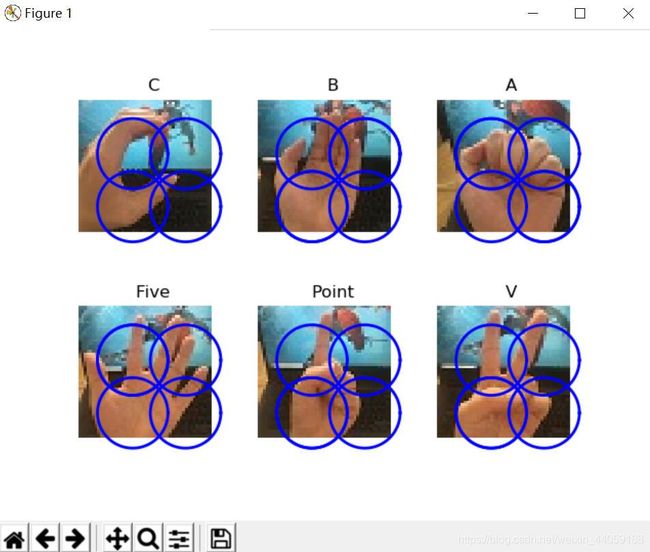
# 显示手势含义title
titlename = filename[:-14]
subplot(2, 3, i + 1)
sift.plot_features(im, l, True)
title(titlename)
show()
运行完后结果会用显示正确率对于给定的测试集有多少图像是正确分类的,但是它并没有告诉我们哪些手势难以分类,或者犯哪些错误。这时,我们可以通过混淆矩阵来显示错误分类的情况。混淆矩阵是一个可以显示每类有多少个样本被分在每一类中的矩阵,它可以显示错误的分布情况,以及哪些类是经常相互“混淆”的
# -*- coding: utf-8 -*-
from PCV.localdescriptors import dsift
import os
from PCV.localdescriptors import sift
from pylab import *
from PCV.classifiers import knn
def get_imagelist(path):
# 获取图片的路径
return [os.path.join(path, f) for f in os.listdir(path) if f.endswith('.jpg')]
def read_gesture_features_labels(path):
# create list of all files ending in .dsift
featlist = [os.path.join(path, f) for f in os.listdir(path) if f.endswith('.dsift')]
# read the features
features = []
for featfile in featlist:
l, d = sift.read_features_from_file(featfile)
features.append(d.flatten())
features = array(features)
# create labels
labels = [featfile.split('/')[-1][0] for featfile in featlist]
return features, array(labels)
def print_confusion(res, labels, classnames):
n = len(classnames)
# confusion matrix
class_ind = dict([(classnames[i], i) for i in range(n)])
confuse = zeros((n, n))
for i in range(len(test_labels)):
# 是正确的类别就加一
confuse[class_ind[res[i]], class_ind[test_labels[i]]] += 1
print('Confusion matrix for')
print(classnames)
print(confuse)
filelist_train = get_imagelist('gesture/train')
filelist_test = get_imagelist('gesture/test')
imlist = filelist_train + filelist_test
# process images at fixed size (50,50)
for filename in imlist:
featfile = filename[:-3] + 'dsift'
dsift.process_image_dsift(filename, featfile, 10, 5, resize=(50, 50))
features, labels = read_gesture_features_labels('gesture/train/')
test_features, test_labels = read_gesture_features_labels('gesture/test/')
classnames = unique(labels)
# test kNN
k = 1
knn_classifier = knn.KnnClassifier(labels, features)
res = array([knn_classifier.classify(test_features[i], k) for i in
range(len(test_labels))])
# accuracy
acc = sum(1.0 * (res == test_labels)) / len(test_labels)
print('Accuracy:', acc)
print_confusion(res, test_labels, classnames)
# 结果竖着看,其他数值表示错判的类别
