分治法的几种写法(以归并排序为例)
递归
- 函数式
优点:便与描述和分析算法,代码简洁清晰,且具有一般性
(*以SML语言为例*)
fun mergeSort(L:int list) =
let
(L, R) = splitMid(L)
(L', R') = (mergeSort(L) || mergeSort(R))
in merge(L', R') end
说明:
- 一般性:这里虽然使用
list但实际上可以换成任意数据类型,影响的只是splitMid的开销,例如 list: W s p l i t M i d ( n ) = O ( n ) W_{splitMid}(n) = O(n) WsplitMid(n)=O(n),array: W s p l i t M i d ( n ) = O ( 1 ) W_{splitMid}(n) = O(1) WsplitMid(n)=O(1) 等- 由于 W m e r g e ( n ) = O ( n ) W_{merge}(n)=O(n) Wmerge(n)=O(n)上面无论那种结构均不会影响
mergeSort的开销( W m e r g e S o r t ( n ) = O ( n l o g n ) W_{mergeSort}(n)=O(nlogn) WmergeSort(n)=O(nlogn))
- 命令式
数据类型以使用数组为例
区别主要体现在语言上,C语言可以直接用指针操作划分数组,Java需要记录这些索引(见下面的例子)
public static void MergeSort(int[] A,int[] temp,int start,int end){
if (start<end){
int mid = (start+end)/2;
//把数组分解为两个子列
MergeSort(A,temp,start,mid);
MergeSort(A,temp,mid+1,end);
//逐级合并两个子列
Merge(A,temp,start,mid,end);
}
}
传递参数 s t a r t , e n d start, end start,end,函数中通过计算 m i d = ( s t a r t + e n d ) / 2 mid = (start+end)/2 mid=(start+end)/2来划分数组,划分为
L = A [ s t a r t , ⋯ m i d ] , R = A [ m i d + 1 , ⋯ e n d ] L=A[start,\cdots mid], \quad R=A[mid+1, \cdots end] L=A[start,⋯mid],R=A[mid+1,⋯end]
非递归
优点:避免递归天生的速度较慢的问题,相比较而言会更快
缺点:技巧性比较强,编程实现较困难且易出错
public static void mergeSort(int[] A) {
if (A.length == 0) return;
int interval= 1;
while(interval < A.length){
for(int i = 0;i+interval< A.length;i += 2*interval)
merge(A, i, interval);
interval*= 2;
}
}
//以升序为例
//(下面也会详细说明)
//调用时 start + interval < A.length 确保末尾
//(1) 没有长度 <= interval 调用
//(2) 要么是 = A.length 要么是 (interval, A.length)
static void merge(int[] A, int start, int interval){
int left = start, right = start + interval,
mid = right, end = mid + interval, k = 0;
int tmplen = min(A.length-start, 2*interval);
int[] tmp = new int[tmplen ];
while(left < mid && right < end && right < A.length){
if(A[left] <= A[right]){
tmp[k++] = A[left++];
}else{
tmp[k++] = A[right++];
}
}
while(left < mid) tmp[k++] = A[left++];
while(right < end && right < A.length) tmp[k ++] = A[right ++];
for(k = 0;k < tmplen;k ++)
A[start+k] = tmp[k];
}
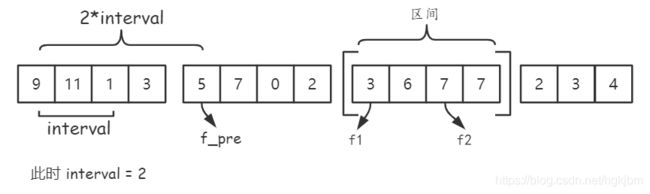
-
i n t e r v a l interval interval 是间隔,表示同一区间内相邻两个(待合并的)数组的距离
如上图第一个区间内两个待合并的数组为 [ 9 , 11 ] , [ 1 , 3 ] [9,11],[1,3] [9,11],[1,3],而 [ 9 , 11 , 1 , 3 ] [9,11,1,3] [9,11,1,3]称为一个区间
(1)区间内 f 2 = f 1 + i n t e r v a l f_2 = f_1+interval f2=f1+interval,其中 f 1 , f 2 f_1,f_2 f1,f2分别表示两个数组的首元素的索引(位置)
(2)相邻区间 f = f p r e + 2 ⋅ i n t e r v a l f = f_{pre} +2\cdot interval f=fpre+2⋅interval, f p r e f_{pre} fpre表示前一个区间的首元素的索引 -
完整区间与不完整区间(重要性质)
当间隔是 i n t e r v a l interval interval 时,
(1)一个完整区间的长度为 2 ⋅ i n t e r v a l 2\cdot interval 2⋅interval,
(2)不完整区间只可能是最后一个区间,有两种情况,一种如上图所示 [ 2 , 3 , 4 ] [2,3,4] [2,3,4],即 l > i n t e r v a l l>interval l>interval,此时它仍然有两个待合并数组组成 [ 2 , 3 ] , [ 4 ] [2,3],[4] [2,3],[4];还一种情况是 l ≤ i n t e r v a l l\le interval l≤interval 时,很容易证明这一不完整区间是已经合并(排序好的)——它一定在间隔为 i n t e r v a l / 2 interval/2 interval/2 做了合并处理。 -
mergeSort中循环条件的说明
记最后一个区间长度 l l l
(1)while: i n t e r v a l < A . l e n g t h interval < A.length interval<A.length
当整个数组为第二类不完整区间( l ≤ i n t e r v a l l\le interval l≤interval)时,即 A . l e n g t h ≤ i n t e r v a l A.length\le interval A.length≤interval 时可知整个数组已经排好序。
(2)for: i + i n t e r v a l < A . l e n g t h i+interval< A.length i+interval<A.length,其中 i i i为某已取件的首元素索引,那么自然可知 i i i按 2 ⋅ i n t e r v a l 2\cdot interval 2⋅interval挪动,退出循环的依据和(1)大同小异,也就是第一类不完整区间要处理,第二类不完整区间不处理。很显然,当 f 2 f_2 f2(第二数组首元素索引)不存在时,最后一区间为第二类,对应 f 2 = i + i n t e r v a l ≥ A . l e n g t h f_2=i+interval\ge A.length f2=i+interval≥A.length,此时应退出循环! -
merge:主要缺陷是反复创建 t m p tmp tmp数组和拷贝至原数组的操作,可以作如下改进
public static void mergeSort(int[] A) {
if (A.length == 0) return;
int interval= 1;
int[] tmp = new int[A.length];
while(interval < A.length){
merge(A, tmp, interval);
interval *= 2;
merge(tmp, A, interval);
interval *= 2;
}
}
//以升序为例
static void merge(int[] source, int[] des, int interval){
int k = 0, start;
for(start = 0;start+interval < source.length;start += 2*interval){
int left = start, right = start + interval,
mid = right, end = mid + interval;
while(left < mid && right < end && right < source.length){
if(source[left] <= source[right]){
des[k++] = source[left++];
}else{
des[k++] = source[right++];
}
}
while(left < mid) des[k++] = source[left++];
while(right < end && right < source.length)
des[k++] = source[right++];
}
//容易遗漏
while (k < source.length) des[k++] = source[start ++];
}
- 将 s o u r c e source source数组和 d e s t i n a t i o n destination destination数组反复交替使用的技巧值得注意
- 易出错:由于最后一个区间长度 l < i n t e r v a l l < interval l<interval,我们不做归并处理(因为它在较小的 i n t e r v a l interval interval一定已经处理过了),但需要拷贝到 d e s des des中
while (k < source.length) des[k++] = source[start ++];