HTTP负载测试
英文原文:ON HTTP LOAD TESTING
有很多人在谈论HTTP服务器软件的性能测试,也许是因为现在有太多的服务器选择。
这很好,但是我看到有人很多基本相同的问题,使得测试结果的推论值得怀疑。在日常工作中花费了很多时间在高性能代理缓存和源站性能测试方面之后,这里有我认为比较重要的一些方面来分享。
希望能抛砖引玉。
0. 一致性
最最重要的是,每次都测试同一个时间点。因为系统发生的每个改变,无论是OS升级还是运行了其它消耗带宽和CPU的应用,都会影响测试的结果,所以一定要把测试环境固定下来。
也许,有人会说那就把测试放虚拟机里做吧,听起来不错。但是,这种方式加多了一个抽象层(而且宿主机上也跑了更多的进程),如果说这样就能得到更加一致的结果,我是无论如何也不会相信的。我觉得,最好的办法是为测试准备一套专用硬件。如果做不到这个,那么一定要把所有测试放在同一个会话里,不要去比较不同会话里的测试结果。
1. 每台机器,各司其职
人们常常会犯另一个错误,他们把负载生成器和被测试的服务器放在同一台机器上。这样做将导致产生不可靠的测试结果,因为,负载生成器实际上是「窃取」了一部分资源,而且这部分资源的量还会随着服务器处理负载情况的变化而变化。
最好的做法是,为测试主体和负载生成器分配不同的硬件,而且将它们放在封闭的网络上。这样做的代价并不是太高,我们并不需要非常高精尖的配置,只需要确保一致性就好。
所以,如果有人跟你说,他们的测试是在localhost上做的,或者拒绝透露测试用了几台机器,那么你尽可以忽略他们的结果。因为,这样的结果,往好了说,只有最基本的定性作用,往坏了说,甚至可能会误人子弟。
2. 检查网络
在测试前,一定要知道你的网络有多大容量,这样,你才会知道,什么时候是你测试的服务器制约了测试,什么时候是网络制约了测试。
一种方法是通过iperf:
qa1:~> iperf -c qa2 ------------------------------------------------------------ Client connecting to qa2, TCP port 5001 TCP window size: 16.0 KByte (default) ------------------------------------------------------------ [ 3] local 192.168.1.106 port 56014 connected with 192.168.1.107 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 1.10 GBytes 943 Mbits/sec
从上面的输出中可以看到,我的千兆网可以达到943Mbps的速度(之所以不到1000Mbps,是由于TCP的开销)。
知道网络容量后,我们需要确保它不会成为制约测试的因素。有几种方法,最简单的是记录当前使用的带宽。例如,httperf可以像这样展示当前的带宽用量:
Net I/O: 23399.7 KB/s (191.7*10^6 bps)
上例表明,我们目前只用了192Mbps。
记住,我们在负载产生工具中看到的数字并没有包括TCP开销,而且,如果我们的负载在整个测试期间并不固定,那么突发带宽一定会有超过平均值的时候。而且除了带宽以外还有其它的问题,例如,廉价的网卡和交换机很有可能会被大量的数据包淹没。

基于以上的种种原因,我们最好不要让测试的带宽逼近网络的可用带宽,最好是不要超过某个比例,比如2/3。对网络(包括网卡和交换机)错误和峰值速率进行监控也是一个很好的办法。
3. 去除OS限制
同样,我们还需要确保OS不会对服务器的表现构成限制。
TCP参数的调整颇为重要,但它会对所有测试主体产生相同的影响。更为重要的是,不要让你测试的服务器用光文件描述符(file descriptor)。
4. 避免压测客户端
现代高性能服务器使得容易将负载产生器的限制当作服务器的能力。所以,认真检查以确保你的客户端没有用爆CPU,如果有任何怀疑,就使用更多客户端压力来验证(autobench可以让这件事更简单)。
确保负载产生器的硬件优于要测试的服务端硬件,也很有帮助;比如,使用4核心的i5-750服务器产生负载,将服务器运行在较慢的双核i3-350服务器上,而且经常只用两个核心之一。
另外一个需要注意的因素是客户端错误,尤其是临时端口(ephemeral ports)用尽。处理这个问题有很多策略,扩大服务器的可用端口范围,或设置多个网络接口,确认由客户端使用它们(有时需要一些技巧)。也可以优化TIME_WAIT时间(只有是测试环境就没问题),或仅仅使用HTTP长连接和激进的客户端超时策略,确保连接速率不会用尽端口数。
我喜欢httperf的一个原因是它在结束时提供了错误的概要:
Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
这里,服务器的问题位于第一行(比如由于服务器端超过--timeout设置的超时时间而造成的请求超时,或拒绝连接,或连接重置),客户端错误(如文件描述符用尽或地址用尽)在第二行。
在测试本身出错时,这能够帮你及时了解。
5. 过载时的容量并不是真正的容量
产生尽可能大的负载,扔给服务器,这是许多负载产生工具的工作模式。
这种方法对于检查服务器在过载情况下的表现也许不错,但它并不能真正帮我们确定服务器的容量。因为,许多服务器在过载的情况下都会损失一部分的容量。
更好的方法是逐步加大负载,直到服务器达到容量上限,出现性能下降为止。我们可以把结果绘制成一条先抵达峰值、随后下降的曲线,而下降的程度意味着服务器应对过载时的表现情况。
autobench是其中的一种方法,我们可以设置测试的范围,然后就可以得到这样一张图:
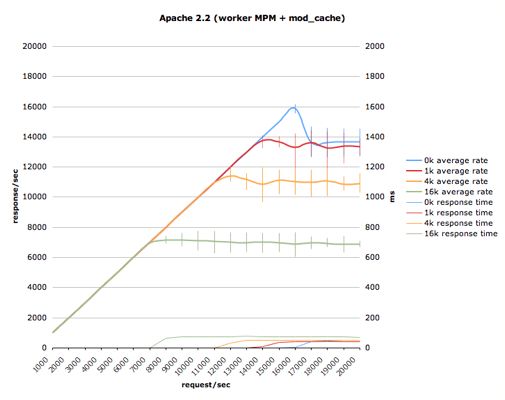
可以看到,在响应消息最小时,服务器的处理峰值为16,000响应/秒,但在过载情况下快速衰落至14,000响应/秒。而在响应消息更大时,过载情况下的衰落并没有这么多,但可以看到错误条不停弹出来,说明了服务器的紧张境况。
6. 30秒的测试不算测试
由于处于应用、OS与网络栈各层的缓冲区需要一定的稳定时间,所以30秒的测试很可能不准确。如果你的测试数据是要正式发布的,请至少测试3分钟,或者更长一些,比如5到10分钟。
7. 不要仅仅测试Hello World
如果要测试服务器的响应是否迅速,用4字节的响应消息过于局限,意义不大,4k甚至100k才更有现实意义。
另外一个需要测试的是服务器在面对大量空闲连接时的表现,比如10,000个连接。这对现代的成熟服务器来说本来不算什么,但往往会导致一些你想象不到的问题。
当然,以上仅仅只是两个例子而已。
8. 仅仅平均值是不够的
如果有人告诉你,服务器可以每秒产生1000个响应,平均时延为5ms,听起来是不是很棒?但是,如果这1000个响应里,有些需要100ms呢?或者,如果说在整个测试的10%时间里,由于垃圾收集的关系,只能达到500个响应/秒的速度,你怎么看?
平均值是个快速指标,但是,仅此而已。有许多重要的信息,包含在时间线和直方图(histogram)中,但平均值并没有提供。如果你的测试工具不提供时间线和直方图,那么还是换一个吧(开源的话,还可以选择提交一个patch)。
httperf可以显示:
Total: connections 180000 requests 180000 replies 180000 test-duration 179.901 s Connection rate: 1000.0 conn/s (99.9 ms/conn, <=2 concurrent connections) Connection time [ms]: min 0.4 avg 0.5 max 12.9 median 0.5 stddev 0.4 Connection time [ms]: connect 0.1 Connection length [replies/conn]: 1.000 Request rate: 1000.0 req/s (.9 ms/req) Request size [B]: 79.0 Reply rate [replies/s]: min 999.1 avg 1000.0 max 1000.2 stddev 0.1 (35 samples) Reply time [ms]: response 0.4 transfer 0.0 Reply size [B]: header 385.0 content 1176.0 footer 0.0 (total 1561.0) Reply status: 1xx=0 2xx=0 3xx=0 4xx=1800 5xx=0
可以看到,它不仅显示了响应速度的平均值,还显示了最小值、最大值和标准差(deviation)。连接时间也是这样。
9. 把相关信息全部发布出来
如果只是给出一个结果,而不给出重现它的必要信息,那么往好了说,这个结果只是一个全凭大家靠信仰来相信的没有用的结论,往坏了说,它甚至有故意误人子弟之嫌(译者注: 各种数据库的宣传式的benchmark表示纷纷中枪)。所以,如果要发布测试结果,记得要把测试的相关上下文也一起发布,不光是测试所用的硬件,还应包括OS版本与配置、网络设置、服务器与负载产生器的版本与配置、所用的负载,甚至必要时还要加上源代码。
理想情况下,我们可以采用代码库(比如github)的形式,使任何人都能以最小的代价(用自己的硬件)重现你的结果。
10. 尝试不同工具
看到这里,你也许会以为我只认httperf和autobench这两个工具。我很喜欢全能型选手,可惜httperf不是。对于现代的一些服务器来说,httperf太慢了,也许是由于它缺乏事件循环的缘故。httperf只能以每秒50到500个请求的速度测试一些PHP应用,但无论如何也做不到以每秒上万个请求的速度去测试那些现代的web服务器。
而且,如果只认准一个工具的话,可能会由于客户端与服务器之间一些奇怪的交互,导致对某个实现特别不利的情况发生。例如,有些工具建立持久连接的方式对一些服务器不够友好,导致它们的测试结果不佳。
而我之所以喜欢httperf,上文中也已经提过,由于它有很详细的统计信息和错误报告,而且可以自定义负载速率,让我们可以更清晰地了解我们的服务器。我希望其它工具也能输出同样详细的信息。
我最近还用了siege,虽然在信息方面还比不上httperf那么详细,不过也很好用,尤其速度真叫一个快。