scrpayd安装与scrapy爬虫的部署
以前我用scrapy写爬虫的时候都是通过crawl来执行的,但这样的运行方式只能执行一个爬虫,如果想同时运行多个爬虫可以考虑使用scrapyd的方式,也就是scrapy server。查看http://scrapyd.readthedocs.io/en/stable/index.html 了解更多关于scrapyd的知识。
在 ubuntu 上安装scrapyd
我是把scrapyd放到了虚拟机上,下面是我在ubuntu 16.04上安装scrpayd的过程。
scrapyd 一下三个包,但是使用pip安装scrapy时可以自动安装。
Python 2.6及以上版本
Twisted 8.0及以上版本
Scrapy 0.17及以上版本
scrapyd对Ubuntu带有特有的安装包,这个安装包可以很大程度上简化管理工作,但是根据官方文档的说法,ubuntu16.04可能不支持。(其他的操作系统可没有这个)。所以我们直接使用pip进行安装。
pip install scrapyd
安装之后控制台会显示类似的输出
Successfully installed scrapyd
Cleaning up...
启动scrapyd
命令行输入
scrapyd
会得到类似下面的输出,表示scrapyd服务器启动成功,至此我们便可以开始下一步–部署scrapy项目。
2018-08-20T15:43:08+0800 [-] Loading /usr/local/lib/python2.7/dist-packages/scrapyd/txapp.py...
2018-08-20T15:43:08+0800 [-] Scrapyd web console available at http://0.0.0.0:6800/
2018-08-20T15:43:08+0800 [-] Loaded.2017-02-20T15:43:08+0800 [twisted.scripts._twistd_unix.UnixAppLogger#info] twistd 16.6.0 (/usr/bin/python 2.7.12) starting up.
2018-08-20T15:43:08+0800 [twisted.scripts._twistd_unix.UnixAppLogger#info] reactor class: twisted.internet.epollreactor.EPollReactor.
2018-08-20T15:43:08+0800 [-] Site starting on 6800
2018-08-20T15:43:08+0800 [twisted.web.server.Site#info] Starting factory
2018-08-20T15:43:08+0800 [Launcher] Scrapyd 1.1.1 started: max_proc=4, runner='scrapyd.runner'
在虚拟机命令行输入
ifconfig
查看虚拟机的ip地址(inet addr)。
此时在本机的浏览器中输入虚拟机的ip和scrapyd的端口号(默认6800)就可以访问scrapyd服务器
http://192.168.83.130:6800/
由于尚未部署项目,浏览器上显示如下:
# Scrapyd
Available projects:
* Jobs* Logs* Documentation
## How to schedule a spider?
To schedule a spider you need to use the API (this web UI is only for monitoring)
Example using [curl](http://curl.haxx.se/):
`curl http://localhost:6800/schedule.json -d project=default -d spider=somespider`
For more information about the API, see the [Scrapyd documentation](http://scrapyd.readthedocs.org/en/latest/)
关闭scrapy
在命令行输入”Ctrl+C”,然后enter之后,就能停止scrapyd
^C2018-08-21T17:40:08+0800 [-] Received SIGINT, shutting down.
2018-08-21T17:40:08+0800 [-] (TCP Port 6800 Closed)
2018-08-21T17:40:08+0800 [twisted.web.server.Site#info] Stopping factory
2018-08-21T17:40:08+0800 [-] Main loop terminated.
2018-08-21T17:40:08+0800 [twisted.scripts._twistd_unix.UnixAppLogger#info] Server Shut Down.
部署scrapy项目到scrapyd
安装scrapyd-client
根据scrapyd的官方文档,我们可以手动地将项目添加到addversion.json中,当然,scrapyd为我们提供了更为简单的方法–scrapyd-client,利用这个工具可以很方便的将项目发布到scrapyd服务器上。
在本机上直接使用pip安装即可。
pip install scrapyd-client
安装好scrapy-client后,根据文档,我cd到scrapy项目目录下(f:\scrapydata\cdqqcom),输入
scrapyd-deploy -l
这是应该出现该目录下可以部署的项目名称,但是却提示:
scrapyd-deploy不是内部或外部命令,也不是可运行的程序或批处理文件
百度之后发现windows下缺少文件,解决方案是在你的python\Script下创建一个scrapyd-deploy.bat文件,比如我的python放在f:\python下,因此我创建文件的地址为:
f:\python\Script
填充的内容为
@echo off"f:\python\python.exe" "f:\python\Scripts\scrapyd-deploy" %1 %2 %3 %4 %5 %6 %7 %8 %9
此时,我再cd到scrapy项目根目录下,执行
scrapy-deploy -l
得到以下结果,即为操作成功。
scrapy_cdqqcom = http://192.168.83.130:6800/
当然,前提是我们需要在当前项目的 scrapy.cfg 文件中将爬虫配置好。我的配置是:
[deploy:scrapy_cdqqcom]url = http://192.168.83.130:6800/project = cdqqcom
通过scrpy-client将项目部署到服务器
cd到项目的根目录下,运行以下命令:
scrapyd-deploy scrapy-cdqqcom -p cdqqcom
成功反馈,部署成功:
Packing version 1487599081
Deploying to project "cdqqcom" in http://192.168.83.130:6800/addversion.json
Server response (200):
{"status": "ok", "project": "cdqqcom", "version": "1487599081", "spiders": 1, "node_name": "potential-virtual-machine"}
要查看该爬虫是否部署成功可以先cd到爬虫根目录下,然后通过以下命令:
scrapyd-deploy -L scrapy_cdqqcom
这里,scrapy_cdqqcom 是配置文件中的deploy-name,得到的结果如下:
cdqqcom
thepaper
这里我也不清楚怎么出来了thepaper这个爬虫,这个爬虫deploy叫scrapy_thepaper
调度爬虫
调度爬虫需要用到调度工具curl,关于curl可以查看 官网。
Linux系统一般自带curl,windows可在官网 下载,下载之后解压到
F:\curl\curl-7.52.1-win64-mingw
还需要在系统环境变量中进行配置,在 path 中新增环境变量:
F:\curl\curl-7.52.1-win64-mingw\bin
重启控制台后,输入
curl
显示
curl: try 'curl --help' or 'curl --manual' for more information
curl安装成功。使用一下命令可以看到scrapyd上已经部署的工程。
curl http://192.168.83.130:6800/listprojects.json
结果返回如下:
{"status": "ok", "projects": ["cdqqcom", "thepaper"], "node_name": "potential-virtual-machine"}
启动爬虫
curl http://192.168.83.130:6800/schedule.json -d project=cdqqcom -d spider=cdqqcom
其中,project是配置文件中的project名称,spider是我们编写的spider里面的name。返回一下信息则启动成功:
{"status": "ok", "jobid": "ad9e4c82f7e111e6a7a6000c2922d487", "node_name": "potential-virtual-machine"}
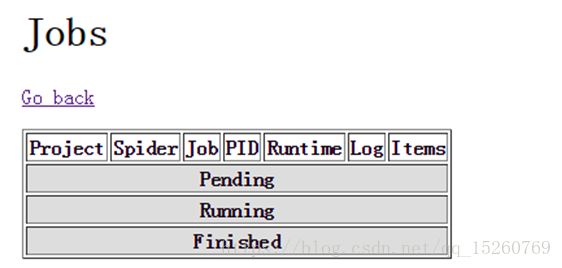
此时,我们访问
http://192.168.83.130:6800/jobs
可以看到

点击log可以看到爬虫的日志,运行完的爬虫会显示在Finished一栏。
停止爬虫
curl http://192.168.83.130:6800/cancel.json -d project=cdqqcom -d job=ad9e4c82f7e111e6a7a6000c2922d487
爬虫停止,浏览器显示如下:
exceptions.TypeError: __init__() got an unexpected keyword argument '_job'.
从scrapyd移除工程
curl http://192.168.83.130:6800/delproject.json -d project=thepaper
移除成功的反馈:
{"status": "ok", "node_name": "potential-virtual-machine"}
文件及日志
部署后会在ubuntu的home下生成dbs、logs、eggs三个文件夹,logs顾名思义是放日志的,另外两个我也不知道干嘛的。