对话系统评价指标Greedy Match代码实现
Greedy Matching 贪婪匹配方法是基于词级别的一种矩阵匹配方法,在给出的两个句子r和r^,每一个词w∈r都会经过词向量转换后变为词向量ew,同时与r^中的每一个词序列w^∈r^的词向量ew^最大程度进行余弦相似度匹配,最后得出的结果是所有词匹配之后的均值:
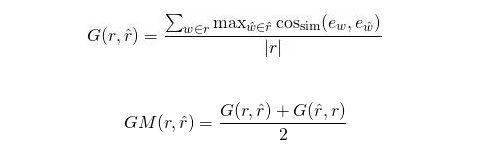
首先要去glove官网https://nlp.stanford.edu/projects/glove/下载训练好的英文词向量压缩包,我选择的是glove.840B.300d.zip,解压得到文件glove.840B.300d.txt,你可以下载比较小的包,解压并保存到你创建的项目下,中文的话要自己去腾讯的AILab下载中文词向量,以下是实现计算两个句子基于词级别的贪婪匹配代码:
import numpy as np
import re
def cosine_similarity(x, y, norm=False):
""" 计算两个向量x和y的余弦相似度 """
assert len(x) == len(y), "len(x) != len(y)"
zero_list = [0] * len(x)
if x == zero_list or y == zero_list:
return float(1) if x == y else float(0)
# method 1
res = np.array([[x[i] * y[i], x[i] * x[i], y[i] * y[i]] for i in range(len(x))])
cos = sum(res[:, 0]) / (np.sqrt(sum(res[:, 1])) * np.sqrt(sum(res[:, 2])))
return 0.5 * cos + 0.5 if norm else cos # 归一化到[0, 1]区间内
def conver_float(x):
'''将词向量数据类型转换成可以计算的浮点类型'''
float_str = x
return [float(f) for f in float_str]
def process_wordembe(path):
'''
将词向量文件中的所有词向量存放到一个列表lines里
:param path: a path of english word embbeding file 'glove.840B.300d.txt'
:return: a list, element is a 301 dimension word embbeding, it's form like this
['- 0.12332 ... -0.34542\n', ', 0.23421 ... -0.456733\n', ..., 'you 0.34521 0.78905 ... -0.23123\n']
'''
f = open(path, 'r', encoding='utf-8')
lines = f.readlines()
return lines
def word2vec(x, lines):
'''
将一个字符串(这里指句子)中所有的词都向量化,并存放到一个列表里
:param x: a sentence/sequence, type is string, for example 'hello, how are you ?'
:return: a list, the form like [[word_vector1],...,[word_vectorn]], save per word embbeding of a sentence.
'''
x = x.split()[:-1]
x_words = []
for w in x:
for line in lines:
# print(line)
if w == line.split()[0]: # 将词向量按空格切分到一个列表里,将列表的第一个词与x的word比较
print(w)
x_words.append(conver_float(line[:-1].split()[1:])) # 若在词向量列表中找到对应的词向量,添加到x_words列表里
break
return x_words
def greedy(x, x_words, y_words):
'''
上面提到的第一个公式
:param x: a sentence, type is string.
:param x_words: list[list1, list2,...,listn], listk(k=1...n) is word vector which from sentence x,
:param y_words: list[list1, list2,..., listn], listk(k=1...n) is word vector which from sentence y,
:return: a scalar, it's value is in [0, 1]
'''
cosine = [] # 存放一个句子的一个词与另一个句子的所有词的余弦相似度
sum_x = 0 # 存放最后得到的结果
for x_v in x_words:
for y_v in y_words:
cosine.append(cosine_similarity(x_v, y_v))
if cosine:
sum_x += max(cosine)
cosine = []
sum_x = sum_x / len(x.split()[:-1])
return sum_x
def greedy_match(path, x, y):
'''
上面的第二个公式
:param lines: english word embbeding list, like[['-','0.345',...,'0.3123'],...]
:param x: a sentence, here is a candidate answer
:param y: a sentence, here is reference answer
:return: a scalar in [0,1]
'''
lines = process_wordembe(path)
# x_words.append(line.split()[1:] for line in lines for w in x if w in line)
x_words = word2vec(x, lines)
y_words = word2vec(y, lines)
# greedy match
sum_x = greedy(x, x_words, y_words)
sum_y = greedy(y, y_words, x_words)
score = (sum_x+sum_y)/2
return score
if __name__ == '__main__':
# print(cosine_similarity([1, 1], [0, 0])) # 0.0
# print(cosine_similarity([1, 1], [-1, -1])) # -1.0
# print(cosine_similarity([1, 1], [2, 2])) # 1.0
f = open('G:\\PycharmProjects\\test\\glove.840B.300d.txt', 'r', encoding='utf-8') #这里改成你自己项目的路径
path = 'G:\\PycharmProjects\\test\\glove.840B.300d.txt' #这里改成你自己项目的路径
# lines = process_wordembe(path)
# print(lines[:1])
x = "what 's wrong ? \n"
y = "I 'm fine . \n"
# x_words = word2vec(x, lines)
# y_words = word2vec(y, lines)
# print(x_words[0])
# print(y_words[0])
# sum = greedy(x, x_words, y_words)
# print(sum)
score = greedy_match(path, x, y)
print(score)
如有问题,欢迎评论指正。