第6章 特征检测、匹配与搜索 个人笔记
文章目录
- 1 前言
- 2 特征检测
- 2.1 基于Harris的特征检测
- 2.1.1 本书代码
- 2.2 基于DoG和SIFT的特征检测
- 2.2.1 本书代码
- 2.2.2 遇到的问题
- 2.3 基于Hessian和SURF的特征检测
- 2.3.1 本书代码
- 2.3.2 人为选择检测算法
- 2.3.3 带滚动条的基于Hessian和SURF的特征检测
- 2.3.3.1 个人代码
- 2.3.3.2 遇到的问题
- 3 特征匹配
- 3.1 基于ORB特征的暴力(Brute-Force)匹配
- 3.1.1 本书代码
- 3.1.2 遇到的问题
- 3.2 K-最邻近(KNN)匹配
- 3.1.1 本书代码
- 3.2.2 遇到的问题
- 3.3 近似最近邻的快速库(FLANN)
- 3.3.1 FLANN匹配
- 3.3.1.1 本书代码
- 3.3.2 FLANN单应性匹配
- 3.3.2.1 本书代码
- 3.3.2.2 部分代码解释
- 4 图像检索应用程序示例
- 4.1 将图像描述符保存到文件中
- 4.2 扫描匹配
- 4.3 匹配结果
- 5 结尾
- 参考链接
1 前言
主要针对 《OpenCV 3 计算机视觉 Python语言实现》 第6章 图像检索以及基于图像描述符的搜索 做的个人笔记。
本章主要分为三部分:基于Harris、SIFT、SURF的特征检测算法,基于Brute-Force、KNN、FLANN的特征匹配 和 图像检索应用程序示例 。
其中,特征匹配这一部分理解比较吃力,现已基本解决,特此记录。
2 特征检测
2.1 基于Harris的特征检测
2.1.1 本书代码
源码比较简单,就不再单独列出了。
2.2 基于DoG和SIFT的特征检测
2.2.1 本书代码
源码比较简单,就不再单独列出了。
2.2.2 遇到的问题
-
sys.argv[1]出现IndexError: list index out of range错误原因
见参考链接1和2.
出现该错误的原因是你的py文件是在类似于pycharm这样的IDE中运行产生的。其sys.argv[]是从Terminal的方式打开终端中运行py文件传递的参数。
我们在CMD中打开py文件并输入# 格式:python py文件名 照片路径 python sift_sys.py varese.jpg即可正常运行。
-
error: (-215:Assertion failed) VScn::contains(scn) && VDcn::contains(dcn) && VDepth::contains(depth) in function 'cv::CvtHelper
,struct cv::Set<1,-1,-1>,struct cv::Set<0,2,5>,2>::CvtHelper’
见参考链接3.
细节问题:通过CMD运行py文件时报错,原因是图片读取报错,没有将图片放到相关路径。 -
error: (-213:The function/feature is not implemented) This algorithm is patented and is excluded in this configuration; Set OPENCV_ENABLE_NONFREE CMake option and rebuild the library in function 'cv::xfeatures2d::SIFT::create’
见参考链接4.
原因:SIFT已经被申请专利了,在opencv3.4.3.16 版本后,这个功能就不能用了。解决方法:把版本退回到3.4.3以前
pip install opencv-contrib-python==3.4.2.16之后的所有代码都是基于opencv-contrib-python 3.4.2.16 实现的。
此链接还提供了一种CMAKE编译OpenCV的办法,并没有尝试,留存。
2.3 基于Hessian和SURF的特征检测
2.3.1 本书代码
源码比较简单,就不再单独列出了。
2.3.2 人为选择检测算法
根据输入检测算法的名字,执行相应的特征检测。个人觉得不错,已加注释,单独列出。
import cv2
import sys
import numpy as np
# 通过CMD得到图片路径、算法
imgpath = sys.argv[1]
img = cv2.imread(imgpath)
alg = sys.argv[2]
# 选择算法,创建对应的对象
def fd(algorithm):
# 创建算法的字典
algorithms = {
"SIFT": cv2.xfeatures2d.SIFT_create(),
# SURF需要读入Hessian阈值,默认4000
"SURF": cv2.xfeatures2d.SURF_create(float(sys.argv[3]) if len(sys.argv) == 4 else 4000),
"ORB": cv2.ORB_create()
}
# 根据输入的键,返回对应的值
return algorithms[algorithm]
# 读入图片灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 选择算法,检测并计算关键点和描述符,绘制显示
fd_alg = fd(alg)
keypoints, descriptor = fd_alg.detectAndCompute(gray,None)
img = cv2.drawKeypoints(image=img, outImage=img, keypoints = keypoints, flags = 4, color = (51, 163, 236))
cv2.imshow('keypoints', img)
# 等待按键
while (True):
if cv2.waitKey(1000 // 12) & 0xff == ord("q"):
break
cv2.destroyAllWindows()
2.3.3 带滚动条的基于Hessian和SURF的特征检测
本节后边提到一个练习:
创建一个滚动条,用来为SURF实例提供Hessian阈值。
2.3.3.1 个人代码
自己书写,已加注释,单独列出。转载请注明出处。
import cv2
# 定义update,每次滚动条变化时调用
def update(val = 0):
# 通过滚动条获取Hessian
Hessian = cv2.getTrackbarPos('Hessian', 'keypoints')
# 创建SURF对象,计算关键点和描述符并绘制
fd_alg = cv2.xfeatures2d.SURF_create(Hessian)
keypoints, descriptor = fd_alg.detectAndCompute(gray, None)
cv2.drawKeypoints(image=img, outImage=img, keypoints=keypoints, flags=4, color=(51, 163, 236))
# 显示结果
cv2.imshow('keypoints', img)
if __name__ == "__main__":
# Hessian滚动条初值及最大值
Hessian = 8000
max_Hessian = 10000
# 读入照片并灰度化
imgpath = 'varese.jpg'
img = cv2.imread(imgpath)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建窗口和滚动条
cv2.namedWindow('keypoints')
cv2.createTrackbar('Hessian', 'keypoints', Hessian, max_Hessian, update)
# 更新
update()
# 等待按键,销毁窗口
cv2.waitKey()
cv2.destroyAllWindows()
2.3.3.2 遇到的问题
在书写回掉函数update时,刚开始没在括号加val=0,会报错
TypeError: update() takes 0 positional arguments but 1 was given
之所以会注意到解决办法,是在本书 第4章 深度估计与分割 4.5 使用普通摄像头进行深度估计 这一节的滚动条回调函数为:
def update(val = 0):
--snip--
具体原因未知,求大神指点。
3 特征匹配
3.1 基于ORB特征的暴力(Brute-Force)匹配
3.1.1 本书代码
源码比较简单,就不再单独列出了。
下面解释部分代码:
# create BFMatcher object
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
# Match descriptors.
matches = bf.match(des1,des2)
# Sort them in the order of their distance.
matches = sorted(matches,key=lambda x:x.distance)
见参考链接5,6和7 .
matches为DMatch对象列表:
DMatch (int _queryIdx, int _trainIdx, int _imgIdx, float _distance)
DMatch.queryIdx表示查询图像中描述符的索引
DMatch.trainIdx表示目标图像中描述符的索引
DMatch.imgIdx表示目标图像的索引
DMatch.distance表示描述符之间的距离,越小越好
matches = sorted(matches,key=lambda x:x.distance)
表示对匹配的结果matches按照距离进行排序操作
3.1.2 遇到的问题
-
TypeError: Image data of dtype object cannot be converted to float
plt.imshow(img3),plt.show()
原因:图片的读取路径或者格式有问题文件路径的相关知识见参考链接8.
/ :表示当前路径的根路径。
./ :表示当前路径。
…/ :表示父级路径,当前路径所在的上一级路径。
3.2 K-最邻近(KNN)匹配
3.1.1 本书代码
源码比较简单,就不再单独列出了。
但是本书代码只是给出了KNN匹配的结果,并没有对结果进行比率测试。
SIFT描述符进行KNN和比率测试
见参考链接6和9.
对每个匹配返回两个最近邻的匹配,如果第一匹配和第二匹配距离比率足够大(向量距离足够远),则认为这是一个正确的匹配。比值检测认为第一个匹配和第二个匹配的比值小于一个给定的值(一般是0.5),这里是0.7。
代码如下:
import cv2
from matplotlib import pyplot as plt
# Read in the picture
img1 = cv2.imread('./manowar_logo.png', 0)
img2 = cv2.imread('./manowar_single.jpg', 0)
# Initiate SIFT detector
sift = cv2.xfeatures2d.SIFT_create()
# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# BFMatcher with default params
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)
# Apply ratio test
good = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good.append([m])
# cv2.drawMatchesKnn expects list of lists as matches
img3 = cv2.drawMatchesKnn(img1, kp1, img2, kp2, good, img2, flags=2)
plt.imshow(img3)
plt.show()
3.2.2 遇到的问题
error: (-215:Assertion failed) K == 1 && update == 0 && mask.empty() in function 'cv::batchDistance’
问题出处:crossCheck标志位
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
见参考链接7.
针对暴力匹配,可以使用交叉匹配的方法来过滤错误的匹配。交叉过滤的思想很简单,再进行一次匹配,反过来使用被匹配到的点进行匹配,如果匹配到的仍然是第一次匹配的点的话,就认为这是一个正确的匹配。举例来说就是,假如第一次特征点A使用暴力匹配的方法,匹配到的特征点是特征点B;反过来,使用特征点B进行匹配,如果匹配到的仍然是特征点A,则就认为这是一个正确的匹配,否则就是一个错误的匹配。
K近邻匹配,在匹配的时候选择K个和特征点最相似的点,如果这K个点之间的区别足够大,则选择最相似的那个点作为匹配点,通常选择K = 2,也就是最近邻匹配。
个人认为:
暴力匹配为了消除错误匹配,使用了交叉匹配得到最优解。
但是KNN得到的是K个最佳匹配,所以报错。
3.3 近似最近邻的快速库(FLANN)
3.3.1 FLANN匹配
3.3.1.1 本书代码
注释见参考链接9.
import cv2
from matplotlib import pyplot as plt
# 读入查询和训练图片
queryImage = cv2.imread('bathory_album.jpg', 0)
trainingImage = cv2.imread('bathory_vinyls.jpg', 0)
# 使用SIFT检测
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(queryImage, None)
kp2, des2 = sift.detectAndCompute(trainingImage, None)
# 设置FLANN匹配器参数,定义FLANN匹配器,使用KNN算法实现匹配
FLANN_INDEX_KDTREE = 0
indexParams = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
searchParams = dict(checks = 50)
flann = cv2.FlannBasedMatcher(indexParams, searchParams)
matches = flann.knnMatch(des1, des2, k=2)
# 根据matches生成相同长度的matchesMask列表,列表元素为[0,0]
matchesMask = [[0, 0] for i in range(len(matches))]
# 去除错误匹配
for i, (m, n) in enumerate(matches):
if m.distance < 0.7 * n.distance:
matchesMask[i] = [1, 0]
# 将图像显示
# matchColor是两图的匹配连接线,连接线与matchesMask相关
# singlePointColor是勾画关键点
drawParams = dict(matchColor = (0, 255, 0),
singlePointColor = (255, 0, 0),
matchesMask = matchesMask[:50],
flags = 0)
resultImage = cv2.drawMatchesKnn(queryImage, kp1, trainingImage, kp2, matches[:50], None, **drawParams)
plt.imshow(resultImage)
plt.show()
3.3.2 FLANN单应性匹配
单应性是一个条件,该条件表面当两幅图像中的一副出像投影畸变时,它们还能彼此匹配。
3.3.2.1 本书代码
注释见参考链接9.
import cv2
import numpy as np
from matplotlib import pyplot as plt
# 最小良好匹配数目
MIN_MATCH_COUNT = 10
# 读入查询和训练图片
img1 = cv2.imread('bb.jpg', 0)
img2 = cv2.imread('color2_small.jpg', 0)
# 使用SIFT检测
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# 设置FLANN匹配器参数,定义FLANN匹配器,使用KNN算法实现匹配
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks = 50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1, des2, k=2)
# 去除错误匹配
good = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good.append(m)
# 单应性
if len(good) > MIN_MATCH_COUNT:
# 改变数组的表现形式,不改变数据内容,数据内容是每个关键点的坐标位置
src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1, 1, 2)
# findHomography 函数是计算变换矩阵
# 参数cv2.RANSAC是使用RANSAC算法寻找一个最佳单应性矩阵H,即返回值M
# 返回值:M 为变换矩阵,mask是掩模
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC,5.0)
matchesMask = mask.ravel().tolist()
h,w = img1.shape
# pts是图像img1的四个顶点
pts = np.float32([[0,0],[0,h-1],[w-1,h-1],[w-1,0]]).reshape(-1,1,2)
# 计算变换后的四个顶点坐标位置
dst = cv2.perspectiveTransform(pts,M)
# 根据四个顶点坐标位置在img2图像画出变换后的边框
img2 = cv2.polylines(img2,[np.int32(dst)],True,(255,0,0),3, cv2.LINE_AA)
else:
print("Not enough matches are found - %d/%d") % (len(good),MIN_MATCH_COUNT)
matchesMask = None
draw_params = dict(matchColor = (0, 255, 0),
singlePointColor = None,
matchesMask = matchesMask[:100],
flags = 2)
img3 = cv2.drawMatches(img1, kp1, img2, kp2, good[:100], None, **draw_params)
plt.imshow(img3, 'gray')
plt.show()
3.3.2.2 部分代码解释
见参考链接6,7,9和10.
-
src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1, 1, 2)
将good中查询图像中描述符的索引转换为N个(1X2)的列表
Numpy会根据剩下的维度计算出数组的属性值N -
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC,5.0)
M 为变换矩阵,mask是掩模
随机采样一致性(RANSAC)可过滤掉错误的匹配,该方法利用匹配点计算两个图像之间单应性矩阵(3x3的转换矩阵)。
cv2.findHomography() 返回一个掩模,这个掩模确定了 inlier 和outlier 点。 -
matchesMask = mask.ravel().tolist()
将mask转换为一维列表 -
dst = cv2.perspectiveTransform(pts,M) img2 = cv2.polylines(img2,[np.int32(dst)],True,(255,0,0),3, cv2.LINE_AA)通过cv2.findHomography()确定的变换矩阵,使用函数cv2.perspectiveTransform() 找到查询图像里的四个顶点在训练图像的对应点,并画出变换后训练图像的边框。
4 图像检索应用程序示例
CSDN相关链接见参考链接11和12.
两篇内容基本相同,但链接11给出了训练集,所以本章主要参考链接11.
4.1 将图像描述符保存到文件中
在本书源码的基础上加了详细的注释,如下。
import cv2
import numpy as np
from os import walk
from os.path import join
import sys
# 创建描述符
def create_descriptors(folder):
# 将路径中的文件名存于files
files = []
for (dirpath, dirnames, filenames) in walk(folder):
files.extend(filenames)
# 对files中对应的文件保存SIFT特征描述符
for f in files:
save_descriptor(folder, f, cv2.xfeatures2d.SIFT_create())
# 保存描述符
def save_descriptor(folder, image_path, feature_detector):
# 打印当前文件名
print("reading %s" % image_path)
# 对npy结尾的文件跳过相关操作
if image_path.endswith("npy"):
return
# 读取文件,计算关键点和描述符,将描述符另存为npy文件
img = cv2.imread(join(folder, image_path), 0)
keypoints, descriptors = feature_detector.detectAndCompute(img, None)
descriptor_file = image_path.replace("jpg", "npy")
np.save(join(folder, descriptor_file), descriptors)
# 读取路径并创建描述符npy文件
dir = sys.argv[1]
create_descriptors(dir)
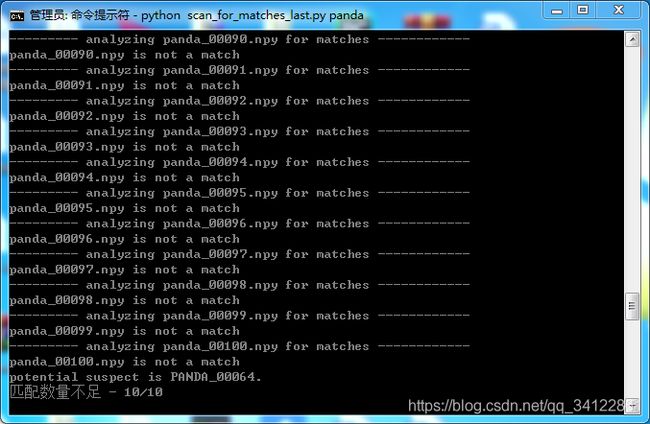
4.2 扫描匹配
本书代码只给出了匹配的文本结果,没有绘制匹配结果的图片部分的代码,所以使用链接11的代码。
在参考链接11的代码的基础上,个人加了详细的注释,如下。
from os.path import join
from os import walk
import numpy as np
import cv2
from sys import argv
from matplotlib import pyplot as plt
# 读取文件所在路径,并读取查询图像
folder = argv[1]
query = cv2.imread(join(folder, "test.jpg"), 0)
# 创建相关列表
files = []
images = []
descriptors = []
for (dirpath, dirnames, filenames) in walk(folder):
# 将路径中的文件名都存于files
files.extend(filenames)
# 将files中npy结尾且不是查询图像的描述符存于descriptors
for f in files:
if f.endswith("npy") and f != "test.npy":
descriptors.append(f)
# 打印descriptors
print(descriptors)
# 创建SIFT对象,并计算关键点和描述符
sift = cv2.xfeatures2d.SIFT_create()
query_kp, query_ds = sift.detectAndCompute(query, None)
# 设置FLANN匹配器参数,定义FLANN匹配器
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
# 最小良好匹配数目
MIN_MATCH_COUNT = 10
# 可能的描述符
potential_culprits = {}
# 打印“启动图片扫描......”
print(">> Initiating picture scan...")
for d in descriptors:
# 打印“分析匹配......”
print("--------- analyzing %s for matches ------------" % d)
# 将descriptors中的每一个描述符与查询图像的描述符进行KNN匹配
matches = flann.knnMatch(query_ds, np.load(join(folder, d)), k=2)
# 去除错误匹配
good = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good.append(m)
# 单应性匹配
if len(good) > MIN_MATCH_COUNT:
print("%s is a match! (%d)" % (d, len(good)))
else:
print("%s is not a match" % d)
# 将每个描述符的序号和匹配数存于potential_culprits
potential_culprits[d] = len(good)
max_matches = None
potential_suspect = None
# 寻找potential_culprits中最大的匹配数,并将描述符序号赋于potential_suspect
for culprit, matches in potential_culprits.items():
if max_matches == None or matches > max_matches:
max_matches = matches
potential_suspect = culprit
# 打印最可能匹配到图像的文件名
print("potential suspect is %s" % potential_suspect.replace("npy", "").upper())
# 读取匹配到的图像,并进行SIFT特征检测,得到关键点和描述符
culprit_image = potential_suspect.replace("npy", "jpg")
target = cv2.imread(join(folder, culprit_image), 0)
target_kp, target_ds = sift.detectAndCompute(target, None)
# 添加文字说明,并显示匹配图像
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(target, 'match.jpg ', (10, 30), font, 1, (255, 0, 0), 2, cv2.LINE_AA)
cv2.putText(query, 'test.jpg', (10, 30), font, 1, (255, 0, 0), 2, cv2.LINE_AA)
cv2.imshow('match', target)
# 将匹配图像与查询图像使用KNN算法实现匹配
matches_o = flann.knnMatch(query_ds, target_ds, k=2)
# 去除错误匹配
well = []
for k, l in matches_o:
if k.distance < 0.7 * l.distance:
well.append(k)
# 单应性匹配
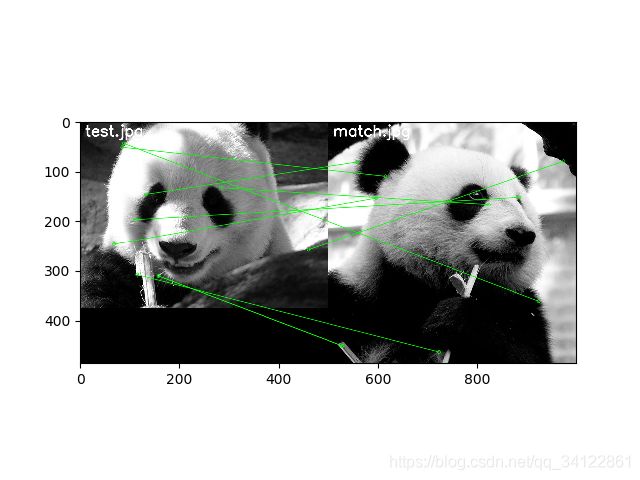
if len(well) > MIN_MATCH_COUNT:
# 计算变换矩阵,计算匹配图像的对应点并绘制
src_pts = np.float32([query_kp[k.queryIdx].pt for k in well]).reshape(-1, 1, 2)
dst_pts = np.float32([target_kp[k.trainIdx].pt for k in well]).reshape(-1, 1, 2)
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
matchesMask = mask.ravel().tolist()
h, w = query.shape
pts = np.float32([[0, 0], [0, h - 1], [w - 1, h - 1], [w - 1, 0]]).reshape(-1, 1, 2)
dst = cv2.perspectiveTransform(pts, M)
image = cv2.polylines(target, [np.int32(dst)], True, 255, 3, cv2.LINE_AA)
else:
print("匹配数量不足 - %d/%d" % (len(well), MIN_MATCH_COUNT))
matchesMask = None
# 绘制连接线并显示
drawParams = dict(matchColor=(0, 255, 0), singlePointColor=None, matchesMask=matchesMask, flags=2)
resultImage = cv2.drawMatches(query, query_kp, target, target_kp, well, None, **drawParams)
plt.imshow(resultImage)
plt.show()
4.3 匹配结果
5 结尾
这是研究生开学前最后一篇个人笔记的博客了。
本文主要针对 《OpenCV 3 计算机视觉 Python语言实现》 第6章 图像检索以及基于图像描述符的搜索 的内容,做了一份个人笔记。
经过这一个多月的学习,主要以Python为工具,做了一些计算机视觉入门的学习。
后边的 目标检测与识别 、 目标跟踪 和 基于OpenCV的神经网络简介 三章,具体会不会继续学习还是得看导师安排。
回看 《OpenCV 3 计算机视觉 Python语言实现》 自学的六章内容,看着自己发表的博客,还是觉得有一丢丢佩服能静下心来的自己。
哈哈哈哈哈哈,有点骄傲放纵了,不过与航院、计院的那群真正的一流高校的大神相比,估计自己仍旧还是菜的可怜,菜的真实,菜到爆了。
最有感触自然是 第5章的人脸识别 和 第6章的图像搜索 ,让我实实在在的接触了计算机视觉的相关应用,即便这是很久之前的内容了。
开学后会根据学习进度继续更博客,暂定一个月2~3篇。
给自己定个小目标:过年前更10篇!
个人水平有限,有问题欢迎各位大神批评指正!
参考链接
- sys.argv[1]出现IndexError: list index out of range错误原因https://blog.csdn.net/littlle_yan/article/details/86029375
- sys.argv是什么?
https://blog.csdn.net/benniaofei18/article/details/85722333 - 解决opencv:error: (-215:Assertion failed) VScn::contains(scn) && VDcn::contains(dcn) &&VDepth::contai
https://blog.csdn.net/qq_41895747/article/details/97696813 - opencv4.10不能使用sift = cv2.xfeatures2d.SIFT_create()
https://blog.csdn.net/wcx1293296315/article/details/95207586 - cv::DMatch Class Reference
https://docs.opencv.org/master/d4/de0/classcv_1_1DMatch.html#a43d07332011940086bae0ae4a43da06e - 图像特征匹配总结
https://blog.csdn.net/ssw_1990/article/details/72629655 - 特征提取与匹配—SURF;SIFT;ORB;FAST;Harris角点
https://www.cnblogs.com/Jessica-jie/p/8622449.html - 文件路径./和…/
https://blog.csdn.net/qq_20412595/article/details/82423764 - OpenCV—python 角点特征检测之三(FLANN匹配)
https://blog.csdn.net/wsp_1138886114/article/details/90578810 - OpenCV-Python教程:42.特征匹配+Homography找目标
https://www.jianshu.com/p/d835f1a4717c - opencv3计算机视觉 6.1.9基于文身取证的应用程序
https://blog.csdn.net/sinat_38685910/article/details/95620052 - OpenCV3.x Python语言实现—基于文身取证的应用程序示例
https://blog.csdn.net/qq_20156437/article/details/80886434