浅谈J-Hi查询过滤器的实现原理
J-Hi设计自己的查询过滤器而没有直接采用Hibernate的Criteria,是出于以下两个原因:
1、Hibernate的Criteria的功能是很强大,但在使用上还是比较繁琐。因此J-Hi想从用户使用的简单易用性上考虑设计一款查询过滤器。
2、J-Hi是一款跨ORM的多框架平台,不能拘泥一种只在Hibernate适用的产品。因此从设计角度考虑,J-Hi对于查询过滤功能必须要有一个中间层,从而使适应多ORM框架成为可能。
下面让我们来分析一下对于SQL的查询具体应该考虑些什么
1、字段名 数据库表的字段名
2、操作符 比如大于、小于。还会包括一些特殊的操作符如like和in
3、NO NO操作符是对操作符的补充,只有in和lik也会有no
4、值 对应字段类型的具体值,如字符串就要加引号,日期就要做转换
5、空值 空值是特殊值,表述形式如IS NULL或IS NOT NULL
6、关系符 两个查询条件之间的关系包括三种 AND OR NOT
7、优前级 通过左右括号来控制查询条件的优前级
8、通配符 如果是like操作符,在值的左侧或是右侧或两侧都可以通过%来控制值的匹配条件
对于java来说,无非就是考虑如何将上述的描述通过对象化的方式实现
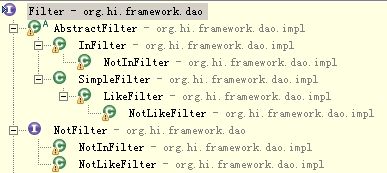
先让我们用例说明:
1 . Filter filter = FilterFactory.getSimpleFilter( " name " , " 马超 " );
首先所有的过滤器都必须由FilterFactory(过滤器工厂)创建,参数依次为
name:POJO的属性名的字符串,可以通过.级联如(org.id);
value:待过滤的过滤值
oprtion:操作符,提供多种操作符,具体参见javadoc
relation:关系符,两个过滤器之间的关系,如AND / OR / NOT
过滤器可以通过addCondition方法累加过滤条件,例如:
filter.addCondition( " name " , " 赵云 " , Filter.OPERATOR_EQ,Filter.RELATIO
调用addCondtion()方法返回是条件累加后的Filter,因此你可以一直不断的调用addCondtion()方法,而不用每做一个过滤条件就创建一个新的Flter。
也可以通过addFilter方法将两个过滤器连接合并在一起
otherFilter.addFilter(filter, Filter.RELATION_AND);
因为一个过滤器会有多个查询条件,因此在通过addFilter()将两上过滤器进行合并时会对这两个过滤器自动加左右括号。对应sql为:
1 . (otherFilter的查询条件) and (name like ‘ % 马超 % ’ or name = ‘赵云’ )
与addFilter对应,J-Hi还提供了removeFilter的功能,目的是通过目标过滤器中删除曾经加进来的子过滤器
otherFilter.remove(filter);
对字符串的操作,如果不加操作符那么系统默认采用like操作符,并且左右两侧均会加通配符,为了解决通配符的问题,J-Hi提供了
1 . Filter likeFilter = FilterFactory.getLikeFilter( " name " , " 马超 " ,
Filter.RELATION_AND, LikeFilter. LIKE_CONTROLER_LEFT );
对应的SQL语名为:name like ‘%马超’
如果对null或非null做过滤
1 . FilterFactory.getSimpleFilter(propertyName, null , Filter.OPERATOR_EQ);
2 . FilterFactory.getSimpleFilter(propertyName, null , Filter.OPERATOR_NOT_EQ);
对应的SQL语句分别为:propertyName IS NULL ; propertyName IS NOT NULL
如果做包含(IN)做过滤
FilterFactory.getInFilter(propertyName, coll);
其中coll是java.util.Collection接口的对象
除此以外,J-Hi还提供了排序器
1 . Sorter sorter = SorterFactory.getSimpleSort(propertyName, Sorter.ORDER_DESC);
2 . Sorter.addSort(properyName1, Sorter.ORDER_ASC);
首先所有的排序器都必须由SorterFactory(过滤器工厂)创建,排序器可以通过addSort方法累加。也可以通过addSort方法将两个排序器连接合并在一起。
具体的调用方法例如:
1 . HiUserManager userMgr = (HiUserManager)SpringContextHolder.getBean(HiUser. class );
2 . userMger.getObjects(filter,sorter);
总结:J-Hi的查询过滤器并没有象Hibernate的Criteria那么的强大,还不支持外连接与聚合。原因是这种大数据量的统计对ORM框架来实现在效率上并不是好的解决方案,再者实现上述功能增加了使用者操作的复杂度。荐于以上两个原因J-Hi的查询过滤器没有实现上述功能。