网易云音乐歌手歌曲、用户评论、用户信息爬取
这里以邓紫棋歌手为例,可以去网易云音乐看她的主页:
所有完整的代码在楼主的github:https://github.com/duchp/python-all/tree/master/web-crawler
# 嘿嘿先说个题外话=。=如果觉得有帮助~麻烦给楼主的github一个star(收藏)~~Thank~
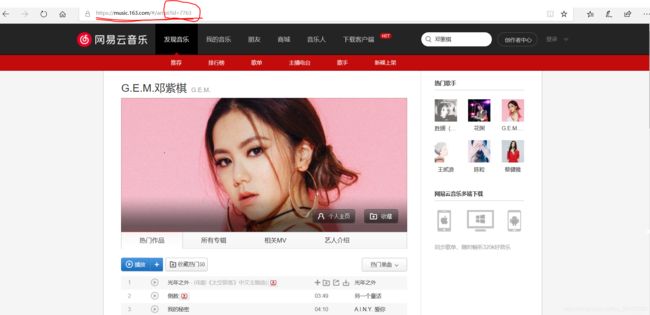
网址里面有她的id,这里是7763。
这个id后面代码中需要使用到,所以在这里预先提一下。
一、歌手热门歌曲爬取
首先上代码:
def get_html_src(url):
# 可以任意选择浏览器,前提是要配置好相关环境,这里选择的是Chrome
driver = webdriver.Chrome()
driver.get(url)
# 切换成frame
driver.switch_to_frame("g_iframe")
# 休眠3秒,等待加载完成!
time.sleep(3)
page_src = driver.page_source
driver.close()
return page_src
def parse_html_page(html):
soup = BeautifulSoup(html, 'lxml')
items = soup.find_all('span', 'txt')
return items由于歌曲的爬取直接用requests库没法得到想要的数据,所以这里采用selenium动态爬取的方式,然后用BeautifulSoup解析爬取下来的信息。
注意:我这里选择了Chrome浏览器,用webdriver.Chrome时,需要调用安装好的浏览器对应的chromedriver.exe文件,这里可以去官网查对应版本,然后下载到代码文件所在的path就好了~
爬取函数和解析函数定义好了,剩下的就是看怎么提取关键信息了,代码如下:
def all_song():
url = "https://music.163.com/artist?id=" + str(7763)
html = get_html_src(url)
items = parse_html_page(html)
muidtol = song_id(items)
return(muidtol) 这里url是我们要爬取的网址,通过爬取解析函数,得到的item包含我们想要的id信息,这里通过song_id函数来提取,我们来看看song_id是什么:
def song_id(items):
songid = []
for item in items:
# print('歌曲id:', item.a['href'].replace('/song?id=', ''))
# song_name = item.b['title']
# print('歌曲名字:', song_name)
songid.append(str(item.a['href'].replace('/song?id=', '')))
return songid
这里我将所以id都存放在一个数组里,item.a['href'].replace('/song?id=','')是提取歌曲id的关键操作,item.b里面用歌曲名字,通过item.b['title']可以提取出来,这里我在后面要爬取用户评论和信息,只需要用到歌曲id,所以没有将歌曲名字保存下来。
所以~邓紫棋的热门歌曲我们就轻轻松松get啦~~~
二、歌曲用户评论爬取
用户评论的爬取可以直接用requests库就可以做到,我用的就是这个方法~
那怎么索引到用户评论呢?我们可以发现,在每首歌的页面下面有评论区,并且需要我们翻页才能看到更多的评论。楼主发现网易云这边对于评论区的爬取有加密的反爬技术,有很多帖子描述了如何解密,楼主决定采用更简单的方式,于是使用API方式爬取,来看看怎么爬取:
def get_response(offset,limit,muid):
#参数
para = {
'offset':offset,#页数
'limit':limit#总数限制
}
# 歌曲id
musicid = muid #
#歌曲api地址
musicurl = "http://music.163.com/api/v1/resource/comments/R_SO_4_"+musicid+"?"+urlencode(para)
#头结构
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Cookie':'vjuids=-13ac1c39b.1620457fd8f.0.074295280a4d9; vjlast=1520491298.1520491298.30; _ntes_nnid=3b6a8927fa622b80507863f45a3ace05,1520491298273; _ntes_nuid=3b6a8927fa622b80507863f45a3ace05; vinfo_n_f_l_n3=054cb7c136982ebc.1.0.1520491298299.0.1520491319539; __utma=94650624.1983697143.1521098920.1521794858.1522041716.3; __utmz=94650624.1521794858.2.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; JSESSIONID-WYYY=FYtmJTTpVwmbihVrUad6u76CKxuzXZnfYyPZfK9bi%5CarU936rIdoIiVU50pfQ6JwjGgBvSyZO0%2FR%2BcoboKdPuMztgHCJwzyIgx1ON4v%2BJ2mOvARluNGpRo6lmhA%5CfcfCd3EwdS88sPgxpiiXN%5C6HZZEMQdNRSaHJlcN%5CXY657Faklqdh%3A1522053962445; _iuqxldmzr_=32',
'Host':'music.163.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134'
}
#代理IP
proxies= {
'http:':'http://121.232.146.184',
'https:':'https://144.255.48.197',
'https:':'https://94.240.33.242:3128',
'http:':'http://221.4.150.7:8181',
'https:' : 'https://123.163.117.246:33915',
'https:' : 'https://180.125.17.139:49562',
'https:' : 'https://117.91.246.244:36838',
'https:' : 'https://121.227.24.195:40862',
'https:' : 'https://180.116.55.146:37993',
'https:' : 'https://117.90.7.57:28613',
'https:' : 'https://193.112.111.90:51933',
'https:' : 'https://61.130.236.216:58127',
'https:' : 'https://60.189.203.144:16820',
'https:' : 'https://111.177.185.148:9999',
'http:' : 'http://140.207.50.246:51426'
}
try:
#用post方式接收数据
response = requests.post(musicurl,headers=headers,proxies=proxies)
if response.status_code == 200:
return response.content
except RequestException:
print("访问出错")para是我们爬取评论时需要用到的参数,用requests库爬取自然是需要设置好头结构和代理IP,UserAgent可以通过F12审查网页元素,点击head去查看,IP是楼主随便找的几个~防止本地IP被禁~这些都是爬虫的基本操作=。=
用post方式接受数据,下面就是解析收到的数据了~:
def parse_return(html):
data = json.loads(html)#将返回的值格式化为json
hotct = []
ct = []
if data.get('hotComments'):
hotcomm = data['hotComments']
for hotitem in hotcomm:
hotct.append(hotitem['content'])
if data.get('comments'):
comm = data['comments']
for item in comm:
ct.append(item['content'].replace('\r', ' '))
idd.write(str(item['user']['userId'])+'\n')
return hotct,ct将得到的数据,转化为json格式,用get形式,提取想要爬取的热评(hotComments)和评论(Comments)内容。
这里为了后面用户信息的爬取,还提取了Comments中的user中的userID内容,方便得到用户主页地址。
三、用户信息爬取
根据第二部分得到了用户ID,得到他们的主页格式:https://music.163.com/#/user/home?id=(用户ID)",同样的用F12审查该主页元素,发现用普通的request得到的数据里面,关于地区仅有邮编数据,关于年龄则是一串数字。所以楼主换了另一种方式,动态爬取Selenium:
def get_html_src(url):
# 可以任意选择浏览器,前提是要配置好相关环境
driver = webdriver.Chrome()
driver.get(url)
# 切换成frame
driver.switch_to_frame("g_iframe")
# 休眠3秒,等待加载完成!
time.sleep(3)
page_src = driver.page_source
driver.close()
return page_src
def parse_html_page(html):
soup = BeautifulSoup(html, 'lxml')
city = soup.find('div', 'inf s-fc3')
if(city != None):
city = city.get_text().replace('所在地区:','')
year = soup.find('div','sep')
gender = soup.find('i','icn')
if(gender != None):
gender = re.sub("\D", "", str(gender))
if(year != None):
year = year.get_text().replace('年龄:','')
return city,year,gender通过动态爬取,自然是可以得到地区年龄的中文信息了~做一些删除无关信息等预处理操作,可以得到city、year、gender为想要的数据。
最后,每段解析数据代码中,对数据做的预处理会用到.find,使用方法举例如下:
这里解释一下parse数据的代码部分,怎么去找soup.find里面的元素,使得正好指向我们想要的数据:
第一步:进入爬取的页面,F12审查元素,选择元素,点击我们想要的页面数据,这里以地区为例,点击主页中的“所在地区”
第二步:点击后,我们会发现右边的审查页面会自动跳到对应段:
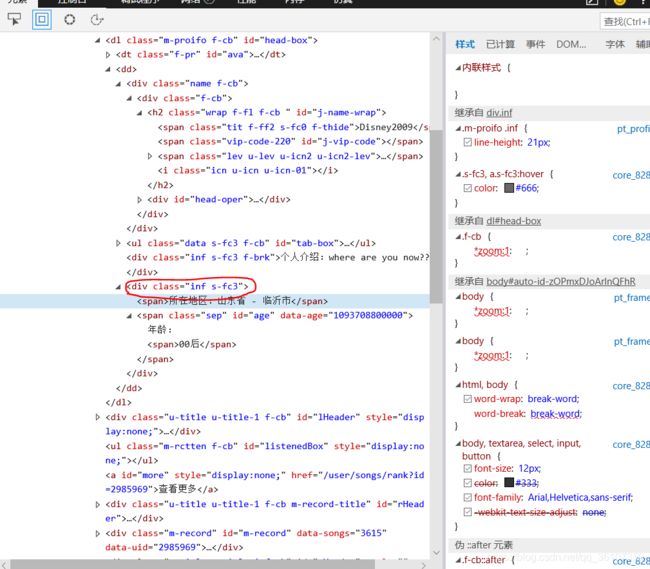
上图,我们想要的数据在
soup.find('div', 'inf s-fc3')第一个元素为class前面的字符串,第二个为class的值,这样就会找到我们需要的数据。