池化
池化
在通过卷积层获得特征(feature map) 之后 ,下一步要做的就是利用这些特征进行整合、分类。理论上来讲,所有经过卷积提取得到的特征都可以作为分类器的输入(比如 softmax 分类器) ,但这样做会面临着巨大的计算量. 比如对于一个 300X300 的输入图像(假设只有一个通道) ,经过 100个 3X3 大小的卷积核进行卷积操作后,得到的特征矩阵大小是 (300 -3+1) X(300 -3+1) = 88804 ,将这些数据一下输入到分类器中显然不好.
此时我们就会采用 池化层将得到的特征(feature map) 进行降维,假如我们得到一个局部特征,他是一个图像的一个局部放大图,分辨率很大,那么我们就可以将一些像素点周围的像素点(特征值) 近似看待,将平面内某一位置及其相邻位置的特征值进行统计,并将汇总后的结果作为这一位置在该平面的值.
常见的池化有 最大池化(Max Pooling) , 平均池化(Average Pooling) ,使用池化函数来进一步对卷积操作得到的特征映射结果进行处理。池化会将平面内某未知及其相邻位置的特征值进行统计汇总。并将汇总后的结果作为这一位置在该平面的值。最大池化会计算该位置及其相邻矩阵区域内的最大值,并将这个最大值作为该位置的值,平均池化会计算该位置及其相邻矩阵区域内的平均值,并将这个值作为该位置的值。使用池化不会造成数据矩阵深度的改变,只会在高度和宽带上降低,达到降维的目的。
池化过程
下面以最大池化为例,平均池化原理一样。
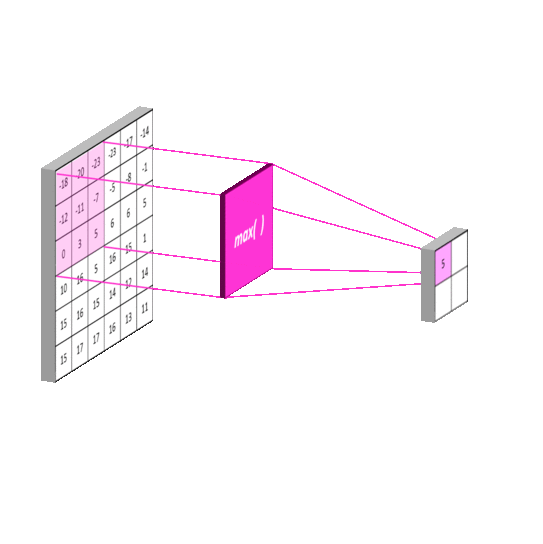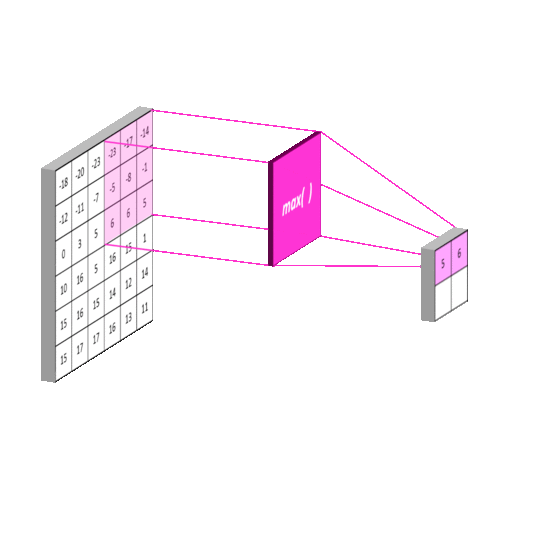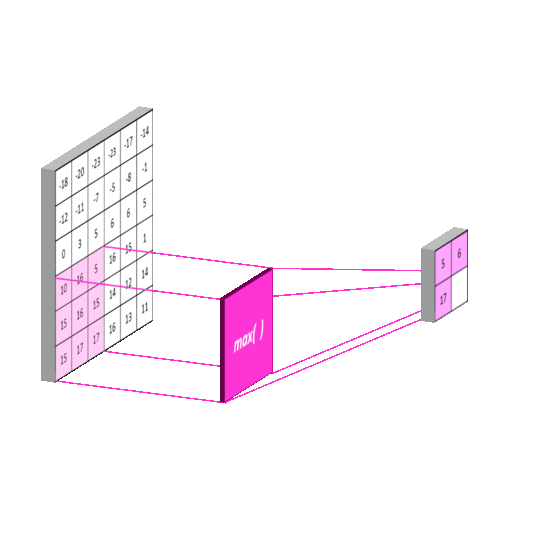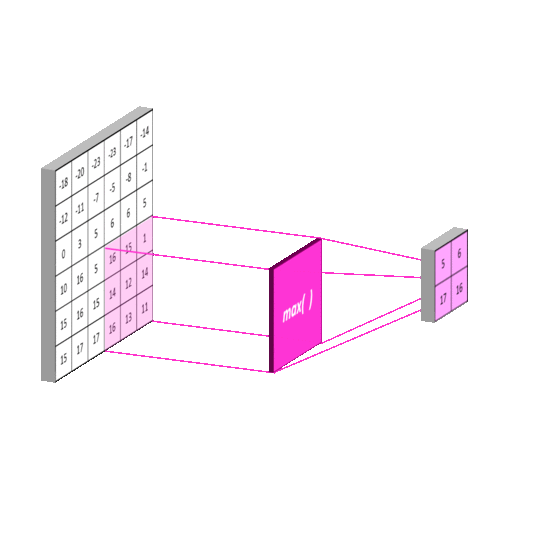
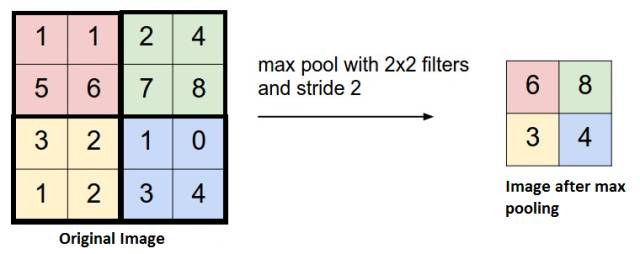
常用的池化函数
Tensorflow 提供了几个封装有池化操作的函数,如实现最大池化的 nn.max_pool() 函数,实现平均池化的 nn.avg_pool()函数。
pool(input,window_shape,pooling_type,padding,dilation_rate,strides,name,data_format)
avg_pool(value,ksize,strides,padding,data_format,name)
max_pool(value,ksize,strides,padding,data_format,name)
#ksize 参数提供了过滤器的尺寸,strides 参数提供步长信息
#padding 提供是否使用全0填充 以 nn.max_pool() 为例 ,首先需要传入当前层的单位矩阵,这个矩阵是四维矩阵(batch_size , 高度,宽度,深度) ,
第二个参数为过滤器(池化核)的尺寸。虽然能够将其赋值为长度为4 的一维数组,但是这个数的第一个数和第四个数必须是1
。nn.max_pool() 函数的第三个参数是步长。最后一个参数指定了是否使用全0填充。VALD 表示不使用全0 填充。 SAME表示使用全0 填充。
池化层的代码实现
1 #!/usr/bin/env python
2 # Author: xiaxiaosheng
3 # Created Time: 2019年07月31日 星期三 08时49分28秒
4
5 # icoding:utf-8
6 import tensorflow as tf
7 import numpy as np
8
9 M = np.array([[[-2],[2],[0],[3]],
10 [[1],[2],[-1],[2]],
11 [[0],[-1],[1],[0]]],dtype="float32").reshape(1,3,4,1)
12
13 filter_weight = tf.get_variable("weights",[2,2,1,1],initializer=
14 tf.constant_initializer([[2,0],[-1,1]]))
15 biase = tf.get_variable('biases',[1],initializer= tf.constant_initializer(1>
16 x = tf.placeholder('float32',[1,None,None,1])
17
18 conv = tf.nn.conv2d(x,filter_weight,strides=[1,1,1,1],padding="SAME")
19
20 add_bias = tf.nn.bias_add(conv,biase)
21