tqdm+pd.concat+dataframe基本操作+pd格式化输出时间+pd.merge(),group,apply,agg,np.where()函数
tqdm模块:用来显示工作的进度条
from tqdm import tqdm
import time
bar = tqdm(['p1','p2','p3','p4','p5'])
for b in bar:
time.sleep(0.5)
bar.set_description("处理{0}中".format(b))
进度条一直往下滚动的问题,可以通过加ncols参数解决,一般设置ncols = 80即可
bar.update(1) #每次更新进度条的长度
pandas pd.concat()函数
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False)
参数说明
objs: series,dataframe或者是panel构成的序列lsit
axis: 需要合并链接的轴,0是行,1是列
join:连接的方式 inner,或者outer
1.1 相同字段的表首尾相接

pandas修改列名:
new_name_list = ['A', 'B', 'C', 'D']
df.columes = new_name_list
DataFrame的基础属性
df.shape ——行数 列数
df.dtypes——列数据类型
df.ndim ——数据维度
df.index——行索引
df.columns——列索引
df.values——对象值,二维ndarray数组
DataFrame整体情况
df.head(10)——显示前10行,默认是5行
df.tail()——显示末尾几行,默认是5
df.info()——相关系数,如行数,列数,列索引、列非空值个数,列类型,内存占用
df.describe()——快速统计结果,计数、均值、标准差、最大值、四分数、最小值
pandas格式化输出时间
transactions['date_formatted']=pd.to_datetime(transactions['date'], format='%d.%m.%Y')
%Y 4位数的年
%y 2位数的年
%m 2位数的月[01,12]
%d 2位数的日[01,31]
%H 时(24小时制)[00,23]
%l 时(12小时制)[01,12]
%M 2位数的分[00,59]
%S 秒[00,61]有闰秒的存在
%w 用整数表示的星期几[0(星期天),6]
%F %Y-%m-%d简写形式例如,2017-06-27
%D %m/%d/%y简写形式
pd.merge()函数
使用过sql语言的话,一定对join,left join, right join等非常熟悉,在pandas中,merge的作用也非常类似。
如:pd.merge(df1, df2) 找到一个外键,然后将两条数据合并成一条。
left: 按照left的dataframe为基准,右边值为空的话就默认nan
train = pd.merge(train, t, on='ship', how='left')
Pandas里Groupby的apply用法

df.groupby('key').apply(lamdba x: x['v'].sum())

下面是apply的另外一种用途,即保证原数据的前提下把分组后求得的和与原数据合并,首先我们先定义一个函数
def func_sum(df):
df['v_sum'] = df['v'].sum()
return df

可以看到原数据添加了新的一列,这一列的值是每种key对应的v的和,上述自定义函数这类方法更具有灵活性,可以同时求和,平均,最大值,最小值,排序等等.
以上便是对于Groupby中的apply函数的简单介绍,在Groupby中还有一类函数,那就是agg函数,这个函数只能实现特定的聚合操作,比如mean,sum, apply函数可以说是它的泛化,比如你可以用apply实现组内排序,但是agg函数并不能。
Pandas里Groupby的agg函数用法
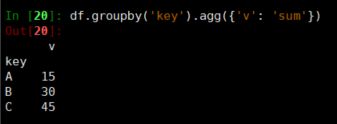
agg函数传入一个字典,键指对应的列名,值指聚合函数如{‘sum’, ‘count’, ‘mean’}之类
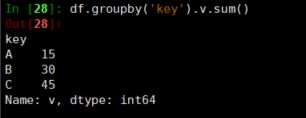
下面的操作是agg的简化版
np.where()函数使用
np.where 函数是三元表达式 x if condition else y的矢量化版本
result = np.where(cond,x,y)
当符合条件时是x,不符合是y,常用于根据一个数组产生另一个新的数组。
栗子:假设有一个随机数生成的矩阵,希望将所有正值替换为2,负值替换为-2
arr = np.random.randn(4,4)
arr
np.where(arr>0,2,-2)